

揭秘 | 为什么一家风控公司要通过网页重要性分析来进行机器学习?
source link: http://www.freebuf.com/articles/es/159976.html?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
1 我们是谁,为什么要做这些
我们是一家业务风控公司, 公司的一项主要业务是提供给客户私有化部署的风控系统和长期的风控分析服务,最后提供给客户的产出,简单归纳来说就是哪些ip,哪些用户,哪些设备,哪些页面存在风险,并提供确实的证据。因为客户的需求、访问流量、内部架构情况各不相同,前期双方对接中涉及爬虫、订单、营销活动等大量业务信息需要大量的时间投入,接入之后分析师需要大量的时间来观察、分析、跟客户的不断沟通,因为当遇到某些业务细节的时候,沟通的成本就会被放大,才能确认最后完成策略的制定,然后观察效果,如此反复来确定风险IP、风险用户、风险设备和风险页面,即客户所需的业务风险评估。
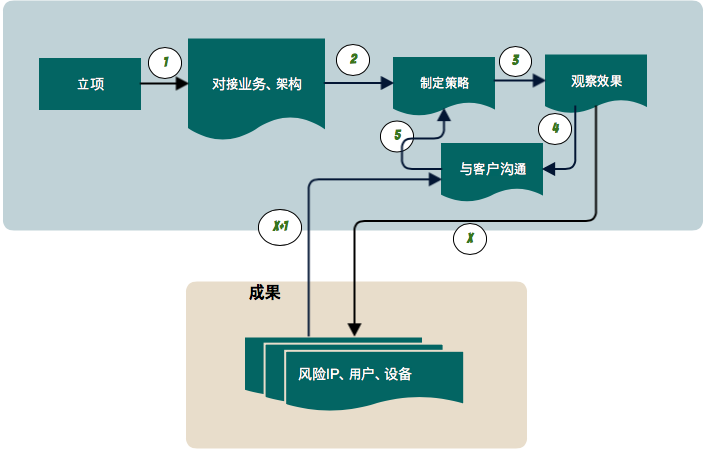
2 为什么要分析网站结构、网站关键路径?
分析、计算成本的上升
一个最简单的博客,只有博文的增删改查4个功能,1个URL接口,但是这样一个博客现在是不可能作为产品投入使用的,自然而然的,评论、标签、类别、用户权限系统、分享... 随着功能的不断完善,接口数量也随之不断增加,更恐怖的是后端程序经常将id之类的非固定内容放到URL当中,所以我们在给客户提供私有化风控服务的时候常有几十万甚至百万量级的URL进行数据统计,这一点在一开始的时候确实会造成我们计算和运营分析资源的浪费,因为分析的对象远远超过了可人工审查的范围,最后也只能靠分析师通过和客户的交涉和自己去使用客户网站的最原始的方法来缩减需要特别关注或需要制定阻断策略的。
简而言之就是随着业务的不断发展, 复杂度无疑是以更快的速度增长,由此带来我们运营分析的沟通、时间成本和我们风控系统计算成本的浪费,我们迫切的想解决这个问题。
报警监控
最基础的监控可能只是针对访问量、流量和一些服务器机器性能指标的,如果监控所有的页面,又显得目标太散,换句话说就是我们盯着全北京的所有路面情况全面标红没有意义,我们只关心我们到家的路径上是否堵车,对客户也是一样,只关心核心资源、活动页面这样的关键节点是否被攻击就足够了。但是只是简单的筛选出需要监控的页面,监控其余所有页面的系统资源也是一种奢侈的浪费,所以我们的结论就是:只监控我们关心的重要页面就好,不关心多余的页面,不需要多余的服务器计算资源,岂不是一步到位?
机器学习
和报警监控的需求类似,机器学习需要关注的只是少量关键资源节点上IP、用户、设备的行为统计数据,因为爬虫、订单之类业务风险流量是不会盯着一个404页面做文章的。
3 为什么要用机器学习来分析风险IP、用户、设备?
咋眼一看,风险分析师根据一个IP、用户或者设备的各种统计性数据来分析风险的IP、用户或者设备,这个分析判断的过程是适合机器学习的目的。
人工分析的成本
笔者所接触到的传统风控都是世代累计的案例构成的成百上千的策略来完成的,通过初筛一些可疑的用户,然后堆人来分析案例,然后复审,逐渐累计汇总成为策略,口耳相传。但是我们的风控服务是面向各行业的客户的,所以只靠堆人已经不能满足我们的,我们还需要加快效率。我们的愿景是教会机器学习这个学生,能够帮助分析师更快的发现风险,最终不断的自我学习,接近人工分析的准确。
过程
那么分析网站结构、网站关键路径我们遇到了哪些坑呢?
理想中的架构
少量的网站入口,层次分明的访问层级,每个关键资源都是这棵树的一个叶子节点,一颗理想完美的网站树结构,只要找到了网站的入口,剩下的问题只是遍历图中的路径了,单纯的笔者,一开始是这么以为的。
现实
当网站被搜索引擎全网索引的时候,网站的大量流量是直接从搜索引擎页面直接抵达,网站的入口成了摆设,人们可以直达想要的内容页面,从此没有了清晰的访问路径, 对于用户可能是一件好事,但是网站规划的访问路径被绕过,损失的可能就不止是广告的浏览量了,一旦爬虫之流伪装成搜索引擎,到时候的难题就是无法分辨真实的爬虫还是真实的流量。
App端,随着移动端的流量逐年增大,很多公司的后端架构都往微服务方向转型,既后端只提供API,具体的业务是放到了具体平台的App中,这样带来的结果是,虽然用户可以离线使用任何不带网络访问的本地内容,但是用户在App客户端中的访问路径之类的数据的不再像传统网站一样是现成的了。
单页应用这样动态前端的网站,随着前后端分离的趋势,跟App端流量类似的是业务、页面访问的逻辑都放到了前端,前端控制后端接口调用,所以我们只知道了用户调用了什么接口,不知道用户从哪里来在什么地方调用的接口。
很多URL是由像id这样的动态内容构成的,所以没人知道URL究竟有多少个。
机器学习来预测业务风险我们遇到了哪些坑呢?
理想情况
机器学习来根据客户流量日志来预测风险就跟机器学习来判断瓜是否好吃的经典案例一样,我们清楚的知道瓜的好吃与否与你看到瓜时残留的藤的长度无关(既特征筛选符合直觉), 只跟瓜的外表图案、响声,品种等有限的特征有关(特征新增、挑选简单), 结果是否准确,吃一口就知道了(判断条件简单,可解释性就强,特征好坏容易判断), 判断错了,反省一下挑的原则就好了(几乎没有错误惩罚)。
回归现实
样本少,靠人工复审效率也不高;因为每个客户的实际情况不同,模型的通用性有待考证的情况下,初始样本就只有传统策略引擎贡献的相对少的量,另外的话,因为我们的风控服务追求的是准确,所以只能牺牲分析师的时间效率,初期训练模型的话,还需要分析师的复审之后筛选出新的样本,扩充了样本库之后,再重新训练如此反复,反而增加了分析师的分析负担。
训练出来的模型通用性, 因为我们服务的是各行业的客户,各个客户的现实问题各不相同,有的被爬虫困扰,有的是活动营销被薅羊毛,所以在每个客户的私有化部署环境里面训练出来的模型很有可能是不具备通用性的。
特征的增加和筛选很纠结;当一些常见的统计特征,例如总量、比率,都加上之后,可能就一百出头的特征,这时候训练的效果并不是太好 ,愁的是如何增加特征,但是当我们的特征增加到十几k的时候,训练结果并没有飞跃性的提升,这时候我们愁的是如何自动化的筛选出完全无关的特征,特征太多的时候,不仅仅是无法解释,数据量过大,对于程序而言,还需要针对内存使用进行专门的优化。
因为错误惩罚的后果严重仍然无法完全脱离分析师的复审; 跟挑西瓜失败不同的是,我们不能简单的重头来过,因为这样错怪一个好人导致的结果很可能是客户需要面对一个愤怒的正常用户的投诉,一个失误就可能引发对我们系统可靠性的严重怀疑,面对如此严重的错误惩罚,所以我们只能对于模型预测的风险再通过分析师的专家复审去寻求一个合理的解释,才能加入到传统策略引擎的风险预测的结果中。
分析网页重要性的解决方案
第一步,折叠动态URL, 简单说来就是通过将URL分层,通过配置的阈值来控制动态层次的总体大小 ,一旦超过阈值就自动折叠, 最后的结果是我们page页面维度的对象数量下降了至少2个数量级,从一般几十万缩减到了几千,我们满意了么?还没有。
第二步,在折叠URL的基础上,构建网站的访问图,再进一步通过pagerank算法的计算和我们自己累计的一些统计指标,分析得出流量入口、关键索引页面、关键资源节点、必经路径,一些黑名单页面(例如404跳转页面), 然后再通过访问流量构建这些关键节点之间的访问关系图,至此我们成功的将page页面维度的对象数量减少至小于100的常数级别。
基于机器学习的风险预测的解决方案
我们在分析好的网站重要网页关系图上重放流量,根据统计的IP、用户、设备的各种行为作为特征,每个小时跟策略引擎产生的风险IP、用户、设备做新的样本集,来继续增强学习已有的模型,并且产出一些不在样本集的风险IP、用户、设备供给分析师做复审。
每个小时会以上个小时的模型为基础,根据样本集,来遍历所有算法、自动调优所有的特征,给出一个当前小时最佳模型。
*本文作者:岂安科技 toyld,转载请注明来自FreeBuf.COM
本文作者:岂安科技, 转载请注明来自FreeBuf.COM
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK