
1

Oracle "脑残" CBO 优化案例 - 小至尖尖
source link: https://www.cnblogs.com/yuzhijian/p/18156615
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Oracle "脑残" CBO 优化案例
今天晚上下班回来才有空看群,群友发了一条很简单的慢SQL问怎么优化。
非常简单,我自己模拟的数据。
表结构:
-- auto-generated definition
CREATE TABLE HHHHHH
(
ID NUMBER NOT NULL
PRIMARY KEY,
NAME VARCHAR2(20),
PARAGRAPH_ID NUMBER
)
/
CREATE INDEX IDX_1_2_PARAGRAPH_HIST_RULE
ON HHHHHH (PARAGRAPH_ID)
/
CREATE INDEX IDX_1_2_NAME_HIST_RULE
ON HHHHHH (NAME)
/
数据量:
SQL> select count(1) from HHHHHH;
COUNT(1)
----------
200002
Elapsed: 00:00:00.00
慢SQL:
SELECT a.* FROM hhhhhh a
WHERE a.name IN (
SELECT name from hhhhhh b
GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1
);
Plan hash value: 1063187735
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 5 (20)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
|* 3 | FILTER | | | | | |
| 4 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 5 | VIEW | VM_NWVW_1 | 1 | 25 | 3 (34)| 00:00:01 |
| 6 | SORT GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 7 | TABLE ACCESS FULL| HHHHHH | 1 | 25 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
" 1 - filter( EXISTS (SELECT 0 FROM (SELECT ""B"".""PARAGRAPH_ID"" "
" ""$vm_col_1"",""B"".""NAME"" ""$vm_col_2"" FROM ""HHHHHH"" ""B"" GROUP BY "
" ""B"".""NAME"",""B"".""PARAGRAPH_ID"") ""VM_NWVW_1"" GROUP BY ""$vm_col_2"" HAVING "
" ""$vm_col_2""=:B1 AND COUNT(""$vm_col_1"")=1))"
" 3 - filter(""$vm_col_2""=:B1 AND COUNT(""$vm_col_1"")=1)"
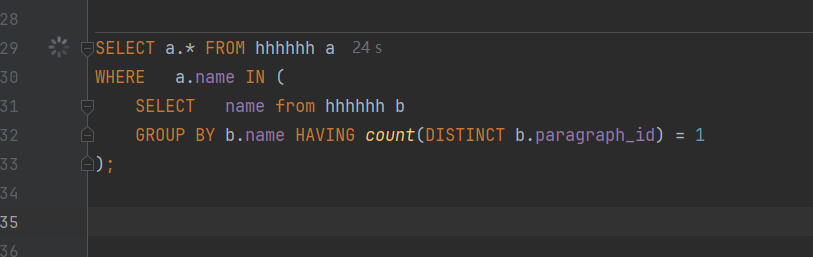
跑了24秒没出结果我就干掉了,正常来说Oracle 这种遥遥领先的数据库,不能100毫秒以内出结果都有问题。
简单看了下上面的计划 Predicate Information 谓词信息,里面信息很复杂,懒得解释(其实我也不懂为啥CBO为啥这样乱分组过滤),并没啥卵用,感觉很SB。
一句话就是CBO等价改写了 EXISTS 还有 :B1这种变量,每次都是传个值到:B1 然后进行filter , 重点是每次。反正各位读者以后在计划中看到这种 :B1 变量都是每次每次,就是一次一次的传值,比较完一个数据继续传。
这种按照 PG 的说法就是复杂的子连接无法提升, GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1 惹得锅。
复杂的子连接无法提升参考 <<PostgreSQL技术内幕:查询优化深度探索 >>这本书 3.2篇章。
加个HINT:
SELECT a.* FROM hhhhhh a
WHERE a.name IN (
SELECT /*+ unnest */ name from hhhhhh b
GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1
5 );
ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001
Elapsed: 00:00:00.05
Plan hash value: 3353221841
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 50 | 5 (20)| 00:00:01 |
|* 1 | HASH JOIN SEMI | | 1 | 50 | 5 (20)| 00:00:01 |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
| 3 | VIEW | VW_NSO_1 | 1 | 12 | 3 (34)| 00:00:01 |
|* 4 | FILTER | | | | | |
| 5 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 6 | VIEW | VM_NWVW_2 | 1 | 25 | 3 (34)| 00:00:01 |
| 7 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 8 | TABLE ACCESS FULL| HHHHHH | 1 | 25 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
" 1 - access(""A"".""NAME""=""NAME"")"
" 4 - filter(COUNT(""$vm_col_1"")=1)"
使用HINT将子链接强行提升(展开)以后,秒出。
但是使用HINT容易将执行计划固定住,非必要情况下不推荐。
等价改写该SQL 方式1:
SELECT A.*
FROM HHHHHH A
INNER JOIN (SELECT COUNT(1) BB, NAME
FROM HHHHHH B
5 GROUP BY NAME) B ON A.NAME = B.NAME AND B.BB = 1;
ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001
Elapsed: 00:00:00.03
Plan hash value: 3909860973
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 50 | 5 (20)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 50 | 5 (20)| 00:00:01 |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
| 3 | VIEW | | 1 | 12 | 3 (34)| 00:00:01 |
|* 4 | FILTER | | | | | |
| 5 | HASH GROUP BY | | 1 | 12 | 3 (34)| 00:00:01 |
| 6 | TABLE ACCESS FULL| HHHHHH | 1 | 12 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
" 1 - access(""A"".""NAME""=""B"".""NAME"")"
4 - filter(COUNT(*)=1)
改写成 join 以后也是秒出。
等价改写该SQL 方式2:
SELECT X.ID,
X.NAME,
X.PARAGRAPH_ID
FROM (SELECT A.*, COUNT(DISTINCT PARAGRAPH_ID) OVER (PARTITION BY NAME) CNT FROM HHHHHH A) X
5 WHERE X.CNT = 1;
ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001
Elapsed: 00:00:00.07
Plan hash value: 2750561680
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 51 | 3 (34)| 00:00:01 |
|* 1 | VIEW | | 1 | 51 | 3 (34)| 00:00:01 |
| 2 | WINDOW SORT | | 1 | 38 | 3 (34)| 00:00:01 |
| 3 | TABLE ACCESS FULL| HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
" 1 - filter(""X"".""CNT""=1)"
改写成开窗函数以后也是秒出。
<<PostgreSQL技术内幕:查询优化深度探索 >> 这本书是真的不错,偷偷刷了好几次,每次看完都有新的理解。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK