

不專業整理 - A100 / RTX 6000 / 4090 價格與 LLM 效能數據
source link: https://blog.darkthread.net/blog/gpu-4-llm-price-n-performance/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
4090 價格與 LLM 效能數據-黑暗執行緒
論大型語言模型(LLM),目前仍由 ChatGPT 稱霸,要開發相關應用,LLM 模型訓練及執行成本很高(參考:訓練大型語言模型有多燒錢?),透過 OpenAI 或 Azure 的 API 整合應是成本效益比較高的做法,
不過,有些應用情境不允許資料上傳到雲端,或必須重訓練或微調以符合需求,就必須考量採用 LLaMA、Mistral、Gemma 等開源模型並採購設備在地端執行。
跑 LLM 模型的 CPU/RAM/SSD 等級是其次,最關鍵的還是 GPU。
H100 / A100 價格為 120 及 60 萬,目前有錢也買不到,可不用列入考量。再來是工作站等級 GPU,RTX-6000/5000/4500/4000/4000 SFF... 等,RTX-6000 有 48G 記憶體,不需量化可直接跑 13B 大小的模型,價格約 18 萬。再下來是一般玩家咬咬牙勉強買得下手的消費級顯卡 4090,價格 6 萬。若一張不夠,想體驗團結就是力量,工作站等級的高階主機,可以讓你插到四張雙寬度顯卡或七張單寬度顯卡。
總之,要發揮地端 LLM 威力還是要靠鈔能力,要跑 7B 或 13B LLaMA 2 模型,不同等級 GPU 的效能差異如何?砸錢裝兩張 GPU 效能會加倍嗎?這篇算是「遠觀豬走路」性質的不專業資料蒐集,求有個籠統概念就好。
既然花了時間查了資料,順手分享給有興趣的同學加減參考。
先看不同型號單一 GPU 的價格與跑 LLM 的效能數字:
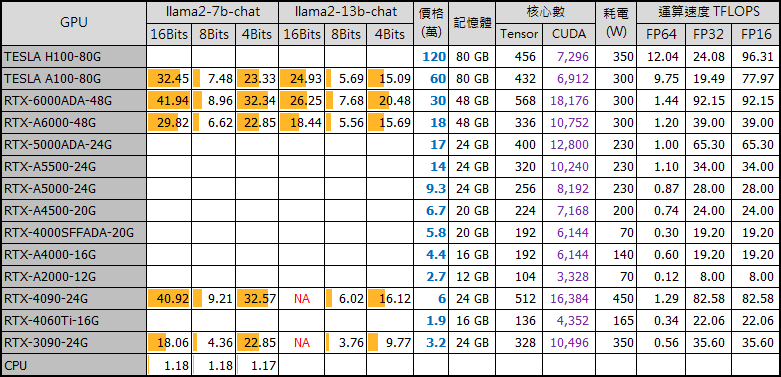
【資料來源】
表格有附不同 GPU 跑 llama2-7b-chat 及 llama2-13b-chat 模型的效能數字,單位為 Tokens/s。CPU 只能用慘烈形容,不到 2。4090 跑 7B 模型數字挺漂亮,甚至贏過 A100。有趣的是 8 bit 量化版的數很難看,4 bit 量化版也輸給 16 bit,關於這點網路上討論不少,我的理解這是用動態量化節省記憶體的代價。參考:2-3x slower is to be expected with load_in_4bit (vs 16-bit weights), on any model -- that's the current price of performing dynamic quantization。
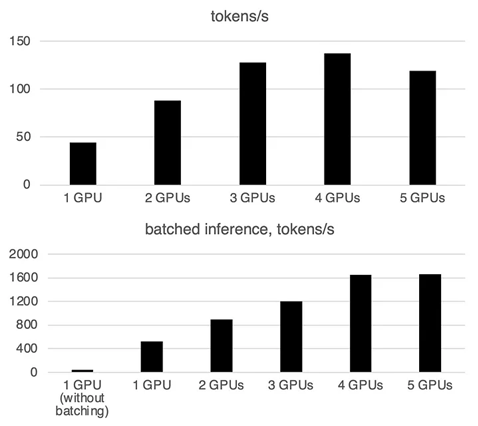
下個問題,如果口袋夠深,買了可插多卡的工作站,多插幾張 GPU 跑推理模型會快一點嗎?我找到一篇 3090 跑 Llama2 7B 的測試數據 (LLM Inference on multiple GPUs with 🤗 Accelerate),圖表上方為單純推理,下方為批次模式執行。插到五張 3090 時可明顯看到隨著 GPU 數量增加,GPU 間溝通成本會抵銷增加的算力,成績不升反降。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK