

我们一起聊聊复杂度来源:高可用
source link: https://www.51cto.com/article/786151.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
我们一起聊聊复杂度来源:高可用
高可用性定义为系统持续不间断地执行其功能的能力,是衡量系统可用性的重要指标之一。这一概念的核心在于实现“无中断”运行,但这正是其实现过程中的主要挑战。由于无论硬件还是软件都难以避免出现故障——硬件可能会遭遇故障和老化,软件可能存在bug且随着时间推移变得更加复杂和庞大。此外,外部因素如断电、自然灾害等也可能导致系统服务中断,这些因素往往不可预测且难以控制。
因此,实现系统的高可用性通常依赖于“冗余”的概念。简而言之,如果一台服务器不足以保障服务的持续性,那么就使用两台,如果两台还不够,那么就增加到四台,以此类推。对于可能出现的断电情况,可以在多个地理位置部署服务器。如果担心网络通道的不稳定,可以同时使用多个网络服务提供商。虽然从表面上看,无论是为了提升性能还是实现高可用性,解决方案似乎都是增加更多的机器,但二者的目的完全不同:提升性能的目的是“扩展”系统的处理能力,而实现高可用性的目的则是通过增加“冗余”单元来确保服务的连续性和稳定性。
计算高可用
这里的“计算”指的是业务的逻辑处理。计算有一个特点就是无论在哪台机器上进行计算,同样的算法和输入数据,产出的结果都是一样的,所以将计算从一台机器迁移到另外一台机器,对业务并没有什么影响。既然如此,计算高可用的复杂度体现在哪里呢?我以最简单的单机变双机为例进行分析。先来看一个单机变双机的简单架构示意图:
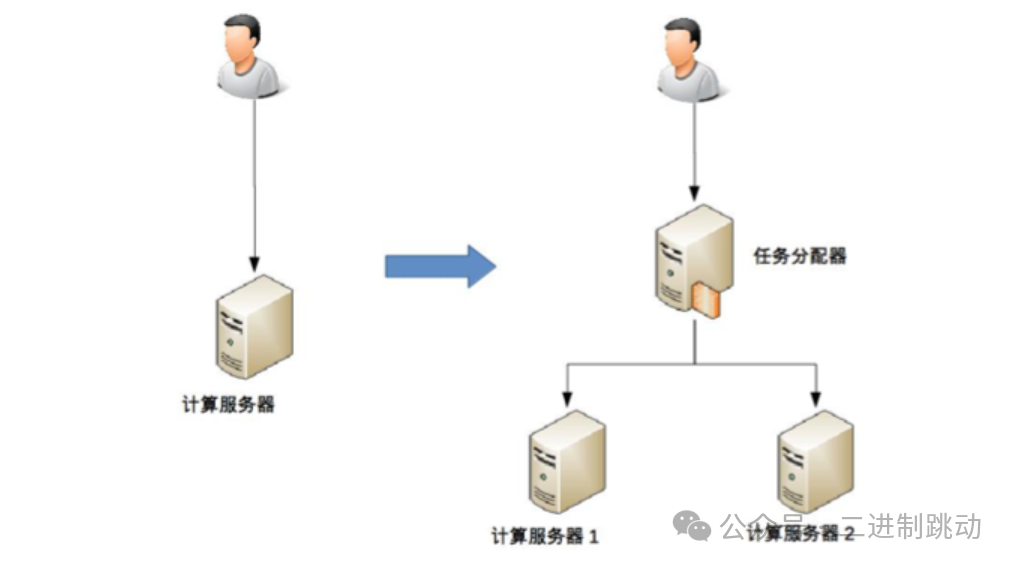
你可能会注意到,提到的双机架构与我们之前在“高性能”主题中讨论的架构非常相似,因此它们的复杂性也有所类似。具体来说:
尽管上述讨论的只是一个基础的双机架构,我们还可以进一步探讨更为复杂的高可用集群架构。与简单的双机设置相比,高可用集群在分配算法上更为复杂,配置形式包括但不限于1主3备、2主2备、3主1备、到4主0备等不同组合。选择哪种配置方案,需根据实际业务需求进行分析和判断,因为并没有一种算法能够绝对胜出。例如,ZooKeeper就采用了1主多备的模式,而Memcached则是采用了全主0备的策略。
存储高可用
在设计需要数据存储的系统时,确保存储的高可用性成为整个系统设计的关键和挑战所在。与计算任务不同,存储任务的一个基本区别在于数据需要通过网络线路从一台机器传输到另一台机器。这种传输的速度受到物理限制,即便是在同一个机房内,传输速度也可能只有几毫秒,而跨越不同地域的机房,传输延时则可能增至数十甚至上百毫秒。例如,从广州到北京的机房之间,稳定时的网络延迟大约是50毫秒,但在不稳定的网络环境下,延迟可能会增加到1秒甚至更长。
为了解决这一问题,系统设计中通常会加入任务分配器,其选择依赖于多种因素,包括性能、成本、可维护性和可用性等。任务分配器不仅需要处理与业务服务器之间的连接和交互,还需选取适宜的连接方式,并妥善管理这些连接,如连接的建立、检测和断开后的处理策略。
此外,任务分配器还需配备高效的分配算法,如主备、双主等模式,其中主备模式又可以细分为冷备、温备和热备等。尽管对于人类来说,毫秒级的时间差异几乎感觉不到,但对于追求高可用的系统而言,这种时间差意味着数据的瞬时不一致性,这对系统的整体业务有着根本性的影响。
举个例子,银行储蓄业务中,如果客户在北京机房存入金额,而此时数据尚未同步至上海机房,当客户查询余额时可能会发现新存入的金额未能显示,造成用户疑虑,这种体验对客户而言极为不佳。他们可能会担心自己的资金安全,甚至可能导致客户投诉或报警。即使最终确认问题仅因为数据同步的延迟,对用户而言,这段经历的体验仍是负面的。
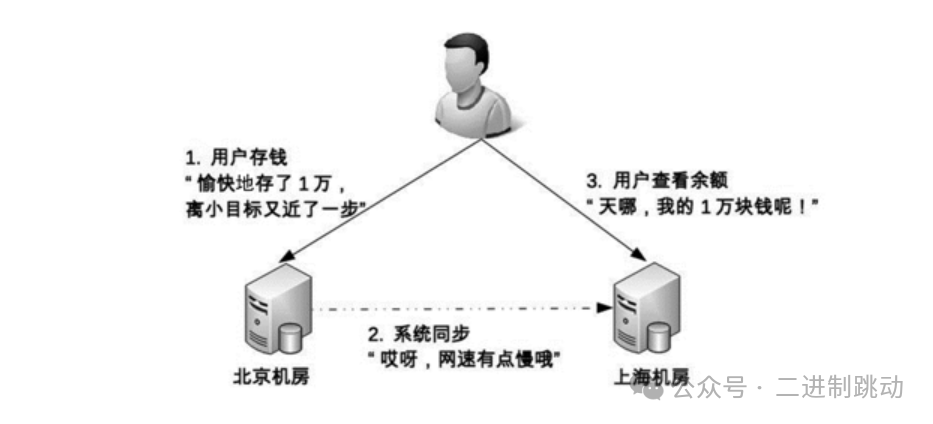
除了物理传输速度的限制,网络线路的可靠性也是一个重要考虑因素。线路可能会遇到中断、拥堵或异常情况(如数据错误、丢失),并且这些问题的修复时间可能长达数小时。以往的事故中,如2015年支付宝因光缆被挖断而业务受影响超过4小时,2016年中美之间的海底光缆断裂导致通讯中断3小时,都是典型例子。这些线路问题意味着数据同步可能会被暂时中断,从而导致系统在一段时间内数据不一致。
从更广的视角来看,不论是在正常情况下的传输延迟,还是异常状况下的传输中断,都可能导致系统在某一时间点或时间段内数据不一致,进而引发业务问题。然而,如果不进行数据的冗余备份,又无法保证系统的高可用性。因此,设计存储高可用系统的挑战不在于数据的备份本身,而在于如何减少或规避数据不一致对业务的影响。
在分布式系统领域,有一个著名的CAP定理,理论上证明了存储高可用的复杂性。CAP定理指出,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个需求,最多只能满足其中两项。这就意味着在架构设计时,需要根据业务需求做出相应的权衡和选择。
高可用状态决策
无论是实现计算的高可用还是存储的高可用,其核心都在于“状态决策”——系统必须能够识别当前状态是正常还是有故障的,并且在检测到故障时采取措施以保持高可用。然而,如果状态的决策过程存在误差或错误,那么接下来的所有优化措施都将失去效果和价值。在实际操作中,存在一个根本的挑战:依赖冗余机制来提高系统可用性的同时,几乎无法实现绝对准确的状态决策。接下来,我们将通过分析几种常用的决策方法来深入探讨这一问题。
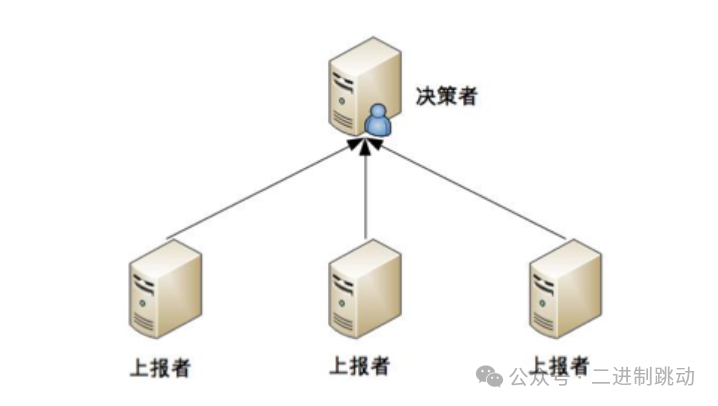
1.独裁式
在讨论如何确保计算和存储的高可用性时,我们不得不关注“状态决策”的重要性——即系统能否正确判断其当前状态为正常或异常,并在发现异常时采取相应措施以维持高可用性。问题在于,如果状态判断过程本身存在误差或错误,则之后的所有优化和处理措施均会失去其意义。在实践中,这里面隐藏着一个基本的矛盾:尽管通过增加冗余来提高系统的可用性,但在状态决策方面却难以保证其绝对的准确性。为了进一步理解这一挑战,我们将对几种主要的决策方式进行详尽的分析。
2.协商式
协商式决策指的是两个独立的个体通过交流信息,然后根据规则进行决策,最常用的协商式决策就是主备决策。
这个架构的基本协商规则可以设计成:
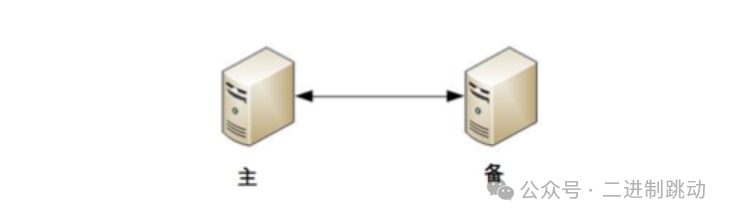
协商式决策的架构不复杂,规则也不复杂,其难点在于,如果两者的信息交换出现问题(比如主备连接中断),此时状态决策应该怎么做。
综合分析,协商式状态决策在某些场景总是存在一些问题的。
2 台服务器启动时都是备机。
2 台服务器建立连接。
2 台服务器交换状态信息。
某 1 台服务器做出决策,成为主机;另一台服务器继续保持备机身份。
如果备机在连接中断的情况下认为主机故障,那么备机需要升级为主机,但实际上此时主机并没有故障,那么系统就出现了两个主机,这与设计初衷(1 主 1 备)是不符合的。
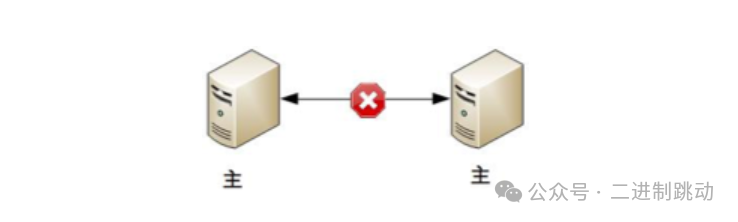
如果备机在连接中断的情况下认为主机故障,那么备机需要升级为主机,但实际上此时主机并没有故障,那么系统就出现了两个主机,这与设计初衷(1 主 1 备)是不符合的。
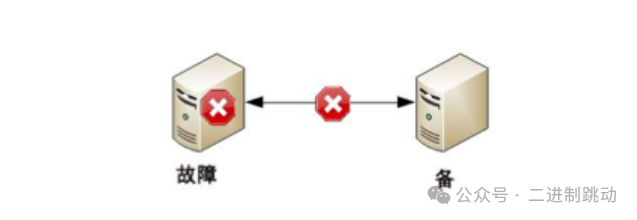
为了缓解连接中断对状态决策的负面影响,一种方法是增加多条连接,比如使用双连接或三连接策略。这种做法确实可以减少单一连接故障时对系统状态判断的影响,但是,它并不能完全消除问题,而且引入了新的挑战:当不同连接传递的信息出现差异时,系统应该依据哪条连接的信息进行决策呢?实际上,这个问题并没有一个一刀切的解决方案。选择任一连接作为决策依据,在某些特定情况下总会遇到困难和挑战。
综合分析,协商式状态决策在某些场景总是存在一些问题的。
3.民主式
民主式决策过程涉及到多个独立实体通过投票机制共同进行状态的判断。这种方式在ZooKeeper集群中选举领导者时得到了应用。
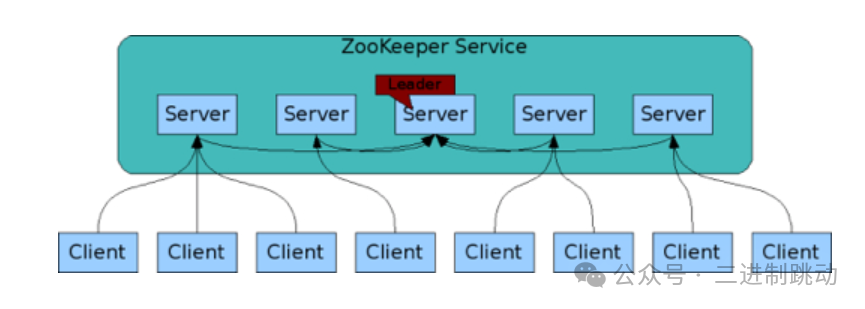
通过这种方法,集群中的每个成员都参与到领导者的选举中,最终根据投票结果决定领导者。
尽管这种决策机制在算法上较为复杂,它自身也带有一个本质上的问题,即“脑裂”现象。这一术语源自于医学领域,描述的是左右大脑半球连接断裂,导致无法互相交换信息,从而分别控制身体做出不同或相互矛盾的行为。在分布式系统中,脑裂指的是原本统一的集群因网络分割成两个独立的子集群,每个子集群都会独立进行领导者选举,结果可能出现两个不同的领导者,类似于一个体系内存在两个“大脑”。民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。例如,ZooKeeper 集。
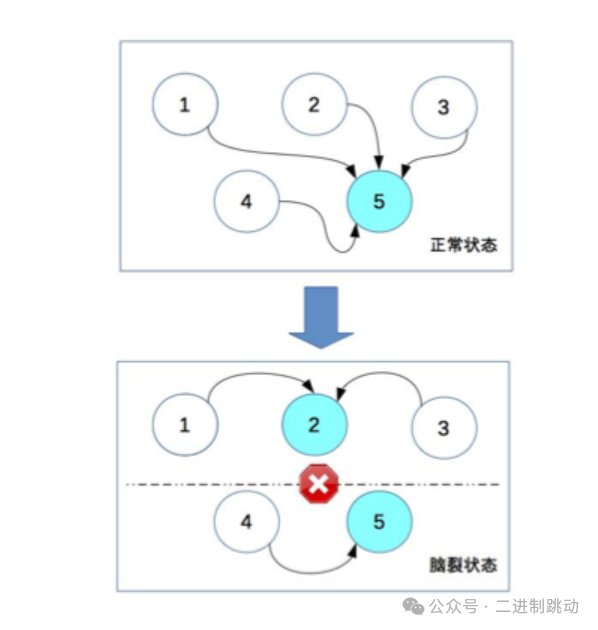
在一个理想的分布式系统设置中,通常会有一个节点被选举为主节点,而其他节点则充当备份角色。假设在一个正常运行的环境里,节点5是主节点,其他节点则作为备份。但当网络故障导致节点间连接断开时,可能会出现节点1、2、3形成一个独立的子集群,而节点4和5形成另一个子集群,这两个子集群因为连接断开而无法相互通信。根据民主式决策机制,这两个子集群可能会分别选举出自己的主节点,比如节点2和节点5,这样系统就会同时存在两个主节点。
这种多主节点的状态与系统的设计初衷相违背,因为每个主节点都会独立作出决策,导致系统状态变得混乱。为了防止这种脑裂现象的发生,采用民主式决策的系统通常实施一项规则:参与投票的节点数必须超过系统总节点数的一半。在上述示例中,由于节点4和节点5组成的子集群总节点数不足系统总数的一半,因此不会进行选举,从而避免了脑裂问题。然而,这种做法虽然能够预防脑裂,却也可能降低系统的整体可用性。例如,如果节点1、2、3的故障并非由脑裂引起,而是真实的故障,这时即便节点4和5仍然健康,系统也无法选举出新的主节点,相当于整个系统停止服务,尽管有部分节点依然处于正常状态。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK