

bitcask论文翻译/笔记
source link: https://www.cnblogs.com/metaphysics/p/17977236
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
bitcask论文翻译/笔记
论文来源:bitcask-intro.pdf (riak.com)
Bitcask的起源与Riak分布式数据库的历史紧密相连。在Riak的K/V集群中,每个节点都使用了可插拔的本地存储;几乎任何结构的K/V存储都可以用作每个主机的存储引擎。这种可插拔性使得Riak的处理能够并行化,从而可以在不影响代码库其他部分的情况下改进和测试存储引擎。
有很多类似的本地K/V存储系统,包括但不限于Berkeley DB、Tokyo Cabinet和Innostore。在评估此类存储引擎时,我们想实现的目标包括:
- 读取或写入每个项目的低延迟
- 高吞吐量,尤其是在写入随机项目的传入流时
- 处理比RAM大得多的数据集的能力,无退化
- 故障友好性,在快速恢复和不丢失数据方面都很好
- 易于备份和恢复
- 相对简单、可理解(因而可支持)的代码结构和数据格式
- 访问负载大或容量大时的可预测行为
- 允许在Riak中轻松默认使用的许可证
实现其中一些目标并不困难,但是想实现所有目标就不那么容易了。
现有的本地K/V存储系统(包括但不限于作者编写的系统)均未达到上述所有目标。当我们在与Eric Brewer讨论这个问题时,他关于哈希表日志合并的关键见解是:这样做可能会比LSM树更快或更快。
这导致我们以新的视角探索了20世纪80年代和90年代首次开发的日志结构化文件系统所使用的一些技术。这次探索导致了Bitcask的诞生,它是一个能够完全实现上述所有目标的存储系统。虽然Bitcask最初是为了给Riak使用而诞生,但是它的设计很通用,因此也可以作为其他应用程序的本地K/V存储。
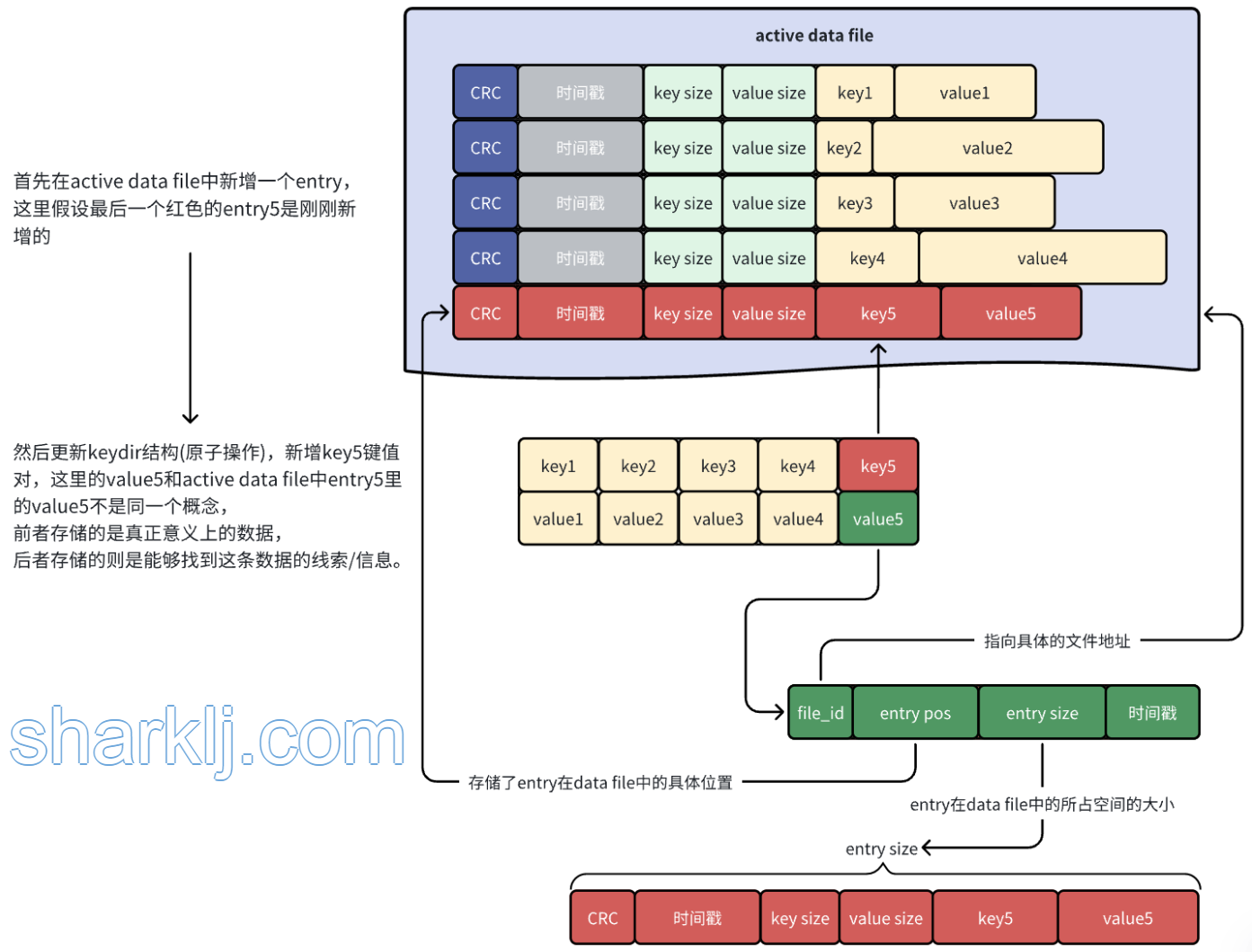
active data file
最终采用的模型在概念上非常简单。Bitcask实例是一个目录,我们强制规定在给定时间内,只有一个操作系统进程可以打开该Bitcask进行写入。您可以将该进程有效地视为“数据库服务器”。在任何时候,该目录中都有一个文件由服务器进行写入操作。当该文件达到一定大小时,它将被关闭,并创建一个新的活动文件。[font color="#FFA500"]一旦文件被关闭,无论是出于有意还是由于服务器退出,它都被视为不可变的,并且永远不会被再次打开进行写入。[/font]
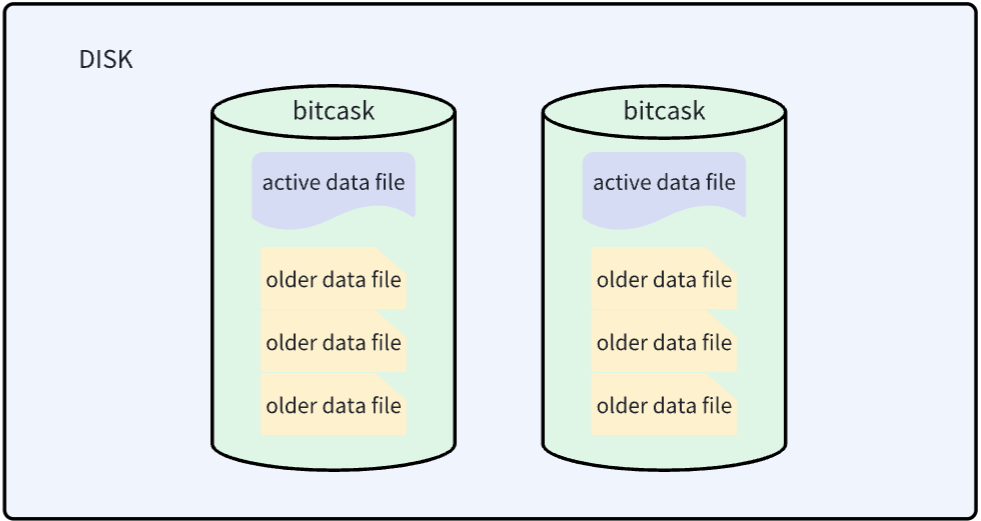
活动文件,也就是上文提到的active data file,只能以追加的方式写入,这意味着顺序写入的同时不需要磁盘寻址。
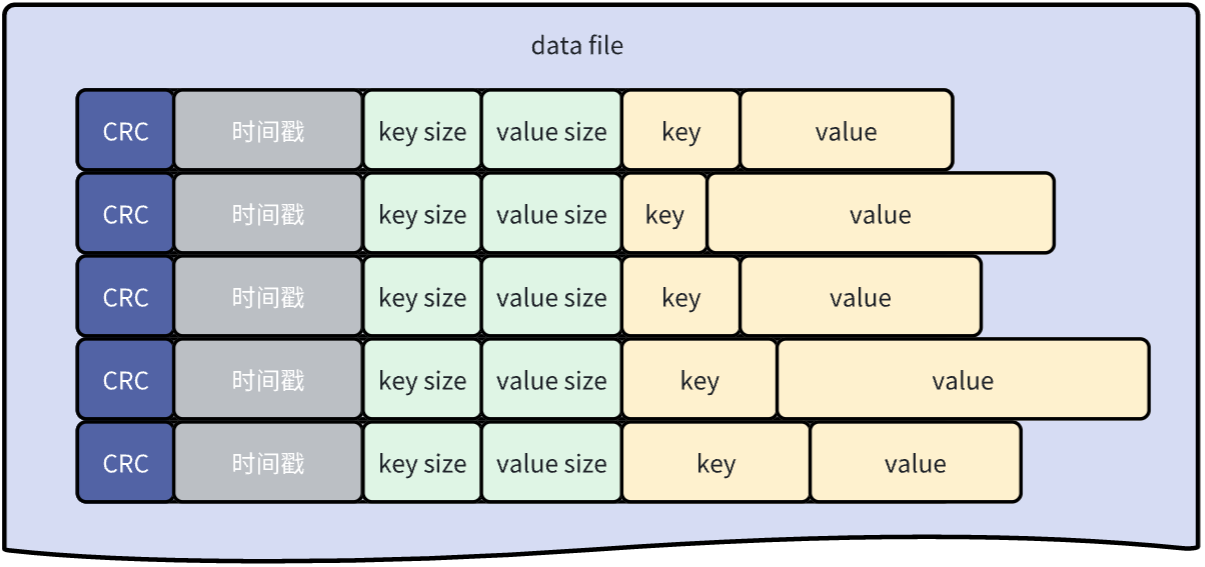
文件中的每个键值对entry的格式如下:
每次写入时,都只是向active data file追加一个新的entry。删除操作只是写入一个特殊的墓碑值(可以理解为是一个特殊标记),它将在下一次合并时被删除。因此,Bitcask数据文件无非是这些entry的线性序列:
keydir
在active data file中完成追加操作后,接着去内存中更新一个名为keydir的数据结构。keydir是一个哈希表(在本论文中它是一个哈希表,也可以是其他数据结构),它将Bitcask中的每个key映射到一个固定大小的结构,这个结构记录了这个key写在哪个文件、该键在该文件中的偏移量以及大小。
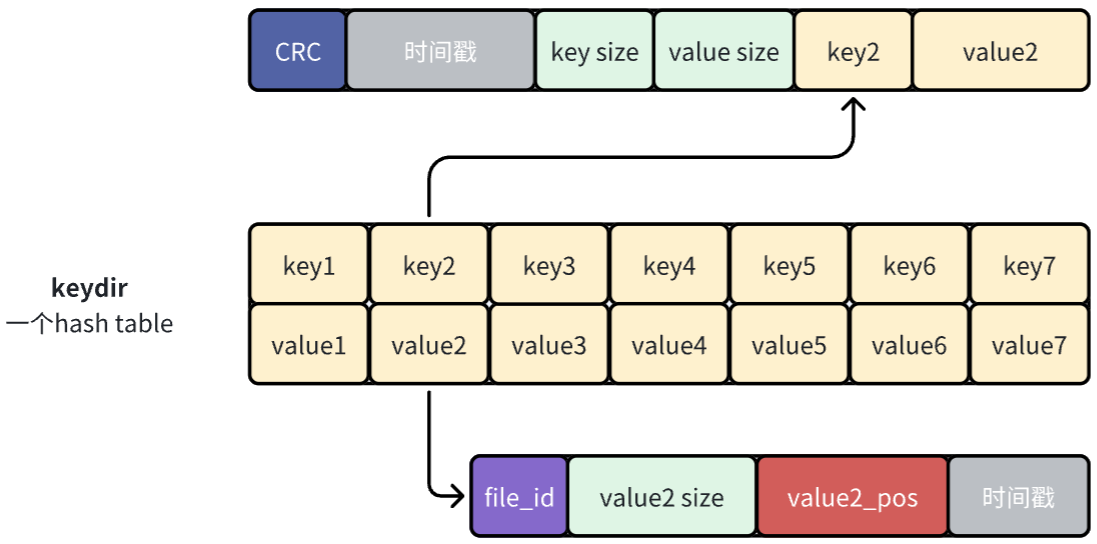
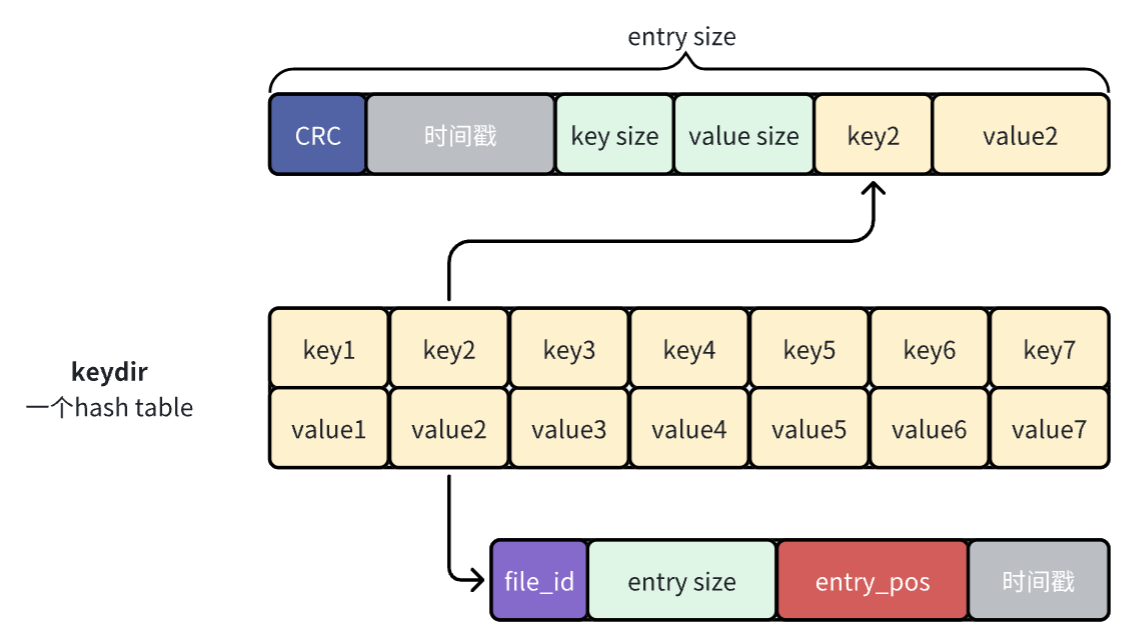
一开始我觉得上面这张图就是对bitcask中哈希表存储内容的正确理解,但是后来觉得下面这个图才是,因为哈希表的value存储的应该是entry的信息,而不是entry中value的信息。原论文中的图有比较大的迷惑性。
数据写入与读取
数据的写入其实在上面两节已经介绍过了,为了方便理解记忆就再总结一下。
写入很简单,就是往bitcask中追加一条entry,然后更新keydir(原子操作),将刚刚新增的entry的信息存储起来,就像下面这样:
数据的读取流程则是先拿着key去keydir中取出相应的entry信息,然后根据entry中提供的信息去data file中取出key对应的value,就像下面这样:
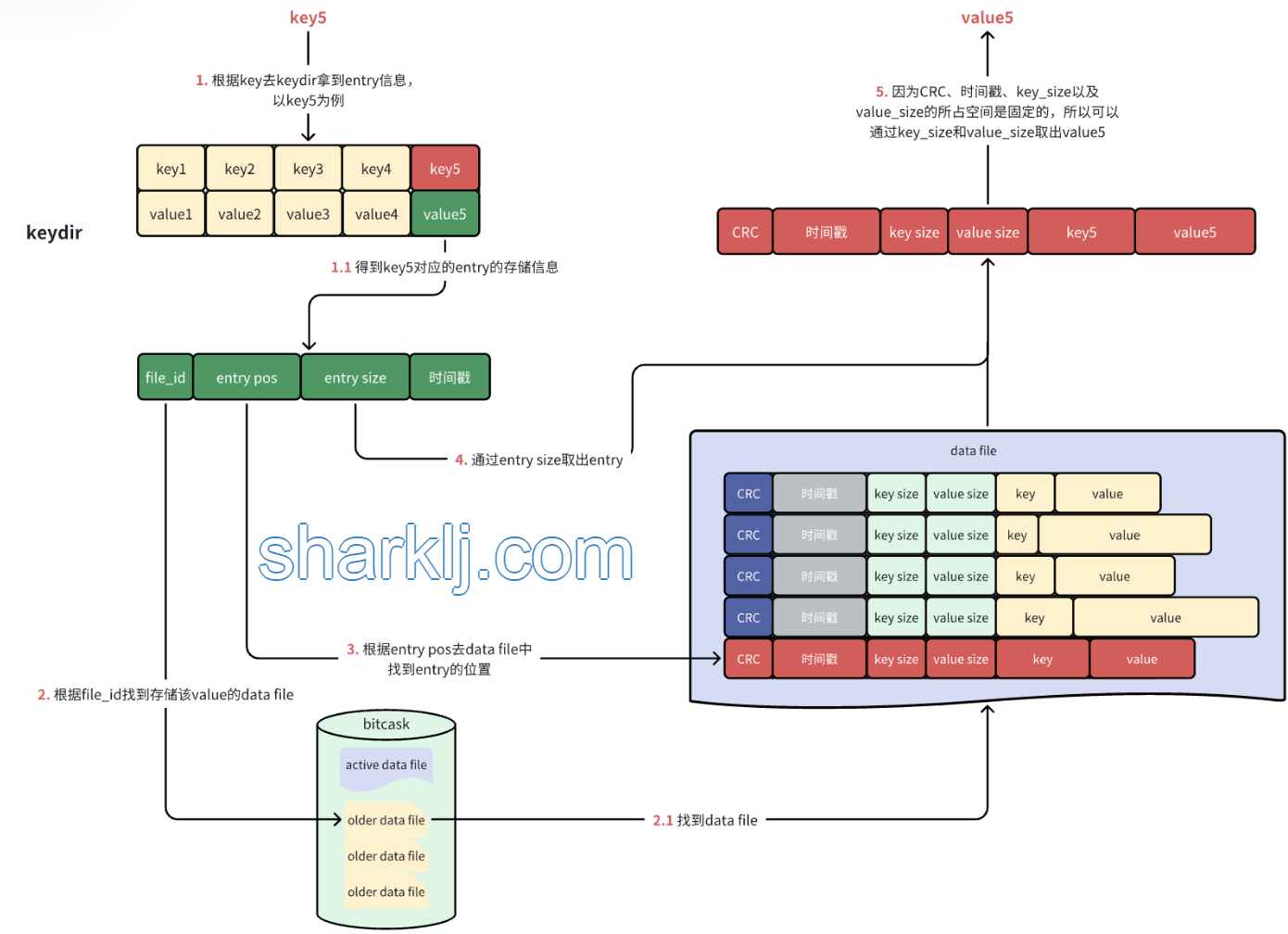
因为bitcask删除的数据的方式是通过追加一条相同key的entry实现的,所以文件的size会越来越大,就需要定期的合并文件,合并的过程是这样的:
- 先遍历所有的
old data file,将所有的有效数据进行合并,如果有多个entry含有相同的key,则只保留最新的entry,有点像Redis中的AOF, - 合并完成后,
old data file会变成merge data file,且数量也会减少,例如10个old data file合并成5个merge data file。 - 因为
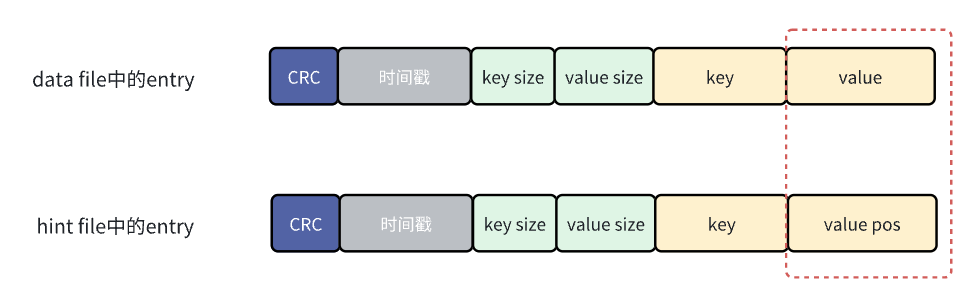
bitcask是在内存中构建索引,也就是之前提到的keydir,构建keydir需要在启动的时候扫描所有的data file,如果数据量很大,那么构建索引的过程就会很耗时,为了解决这个问题,bitcask在合并数据的时候还会为每个merge data file生成一个hint file,这个hint file中存储的也是一堆entry,这些entry的格式和data file中的entry保持一致,唯一的区别就是data file中的entry存储的value是真实数据,而hint file中entry的value存储的是数据的位置。
目前对bitcask的理解也就是这些了,肯定有不准确的地方,想要彻底弄明白也只能自己手搓一个kv存储才行。有任何问题都可以在评论区交流。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK