

Mamba超强进化体一举颠覆Transforme,单张A100跑140K上下文
source link: https://www.36kr.com/p/2710168130680706
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
52B的生产级Mamba大模型来了!这个超强变体Jamba刚刚打破世界纪录,它能正面硬刚Transformer,256K超长上下文窗口,吞吐量提升3倍,权重免费下载。
之前引爆了AI圈的Mamba架构,今天又推出了一版超强变体!
人工智能独角兽AI21 Labs刚刚开源了Jamba,世界上第一个生产级的Mamba大模型!

Jamba在多项基准测试中表现亮眼,与目前最强的几个开源Transformer平起平坐。
特别是对比性能最好的、同为MoE架构的Mixtral 8x7B,也互有胜负。
具体来说它——
- 是基于全新SSM-Transformer混合架构的首个生产级Mamba模型
- 与Mixtral 8x7B相比,长文本处理吞吐量提高了3倍
- 实现了256K超长上下文窗口
- 是同等规模中,唯一一个能在单张GPU上处理140K上下文的模型
以Apache 2.0开源许可协议发布,开放权重
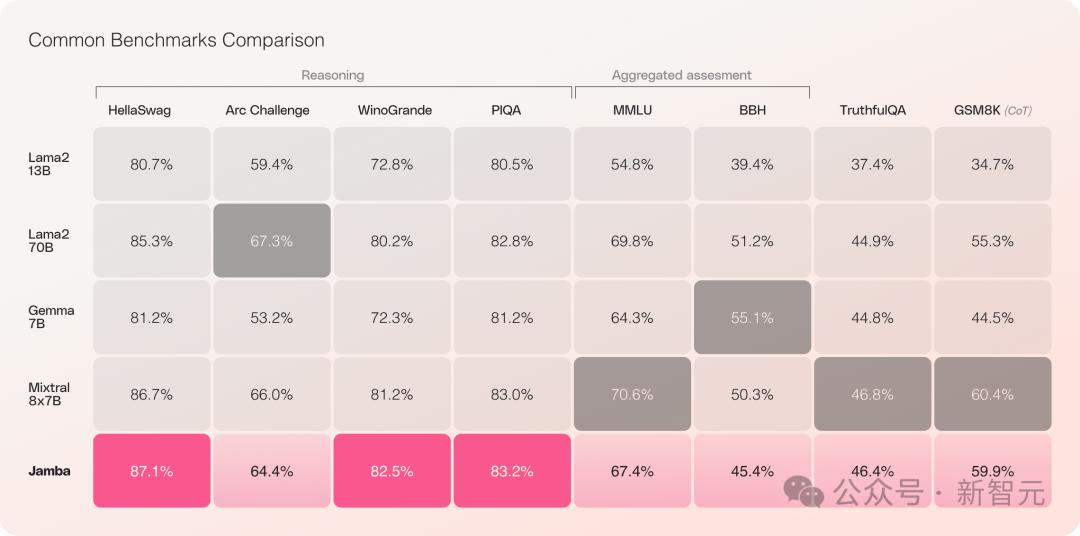
之前的Mamba因为各种限制,只做到了3B,还被人质疑能否接过Transformer的大旗,而同为线性RNN家族的RWKV、Griffin等也只扩展到了14B。
——Jamba这次直接干到52B,让Mamba架构第一次能够正面硬刚生产级别的Transformer。

Jamba在原始Mamba架构的基础上,融入了Transformer的优势来弥补状态空间模型(SSM)的固有局限性。
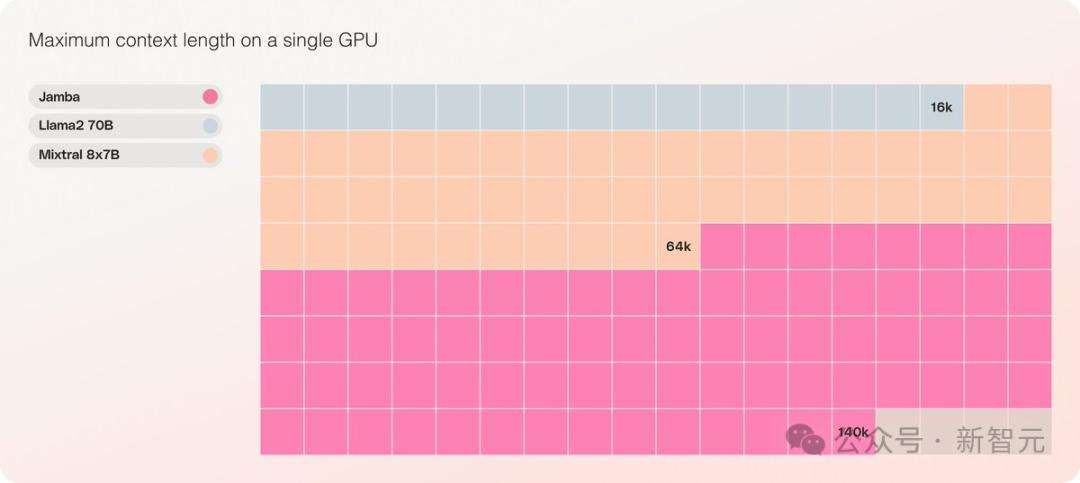
可以认为,这实际上是一种新的架构——Transformer和Mamba的混合体,最重要的是,它可以在单张A100上运行。
它提供了高达256K的超长上下文窗口,单个GPU就可以跑140K上下文,而且吞吐量是Transformer的3倍!
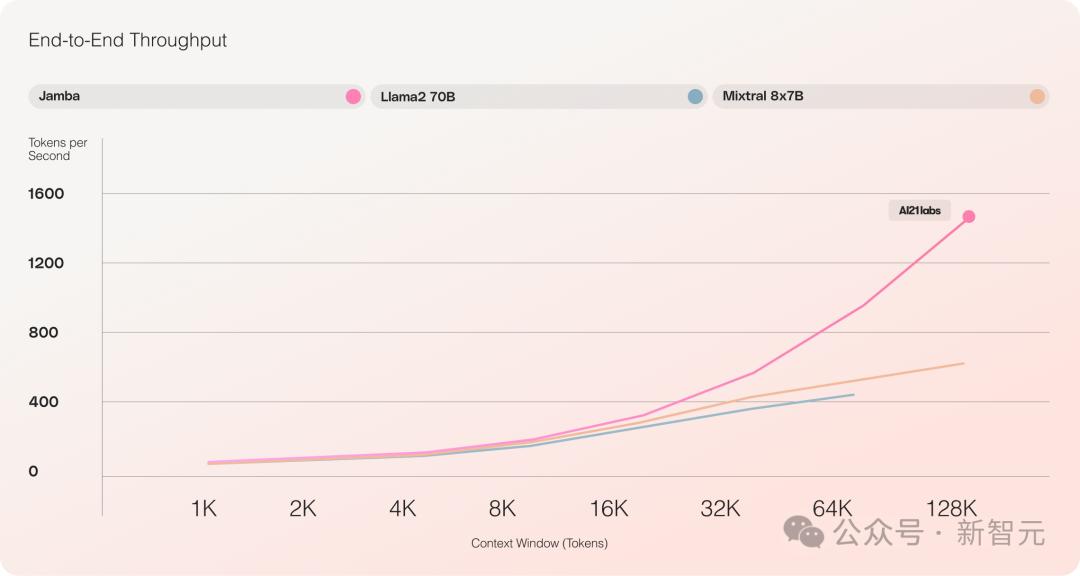
与Transformer相比,看Jamba如何扩展到巨大的上下文长度,非常震撼
Jamba采用了MoE的方案,52B中有12B是活跃参数,目前模型在Apache 2.0下开放权重,可以在huggingface上下载。

模型下载:https://huggingface.co/ai21labs/Jamba-v0.1
LLM新里程碑
Jamba的发布标志着LLM的两个重要里程碑:
一是成功将Mamba与Transformer架构相结合,二是将新形态的模型(SSM-Transformer)成功提升到了生产级的规模和质量。
当前性能最强的大模型全是基于Transformer的,尽管大家也都认识到了Transformer架构存在的两个主要缺点:
内存占用量大:Transformer的内存占用量随上下文长度而扩展。想要运行长上下文窗口,或大量并行批处理就需要大量硬件资源,这限制了大规模的实验和部署。
随着上下文的增长,推理速度会变慢:Transformer的注意力机制导致推理时间相对于序列长度呈平方增长,吞吐会越来越慢。因为每个token都依赖于它之前的整个序列,所以要做到超长上下文就变得相当困难。
年前,来自卡内基梅隆和普林斯顿的两位大佬提出了Mamba,一下子就点燃了人们的希望。
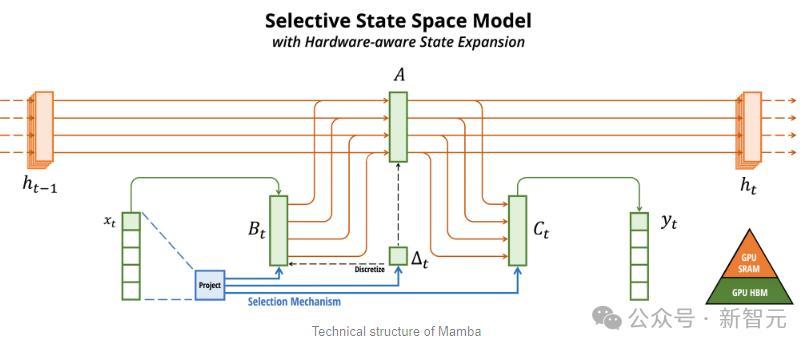
Mamba以SSM为基础,增加了选择性提取信息的能力、以及硬件上高效的算法,一举解决了Transformer存在的问题。
这个新领域马上就吸引了大量的研究者,arXiv上一时涌现了大量关于Mamba的应用和改进,比如将Mamba用于视觉的Vision Mamba。
不得不说,现在的科研领域实在是太卷了,把Transformer引入视觉(ViT)用了三年,但Mamba到Vision Mamba只用了一个月。
不过原始Mamba的上下文长度较短,加上模型本身也没有做大,所以很难打过SOTA的Transformer模型,尤其是在与召回相关的任务上。
Jamba于是更进一步,通过Joint Attention and Mamba架构,整合了Transformer、Mamba、以及专家混合(MoE)的优势,同时优化了内存、吞吐量和性能。

Jamba是第一个达到生产级规模(52B参数)的混合架构。
如下图所示,AI21的Jamba架构采用blocks-and-layers的方法,使Jamba能够成功集成这两种架构。
每个Jamba块都包含一个注意力层或一个Mamba层,然后是一个多层感知器(MLP)。
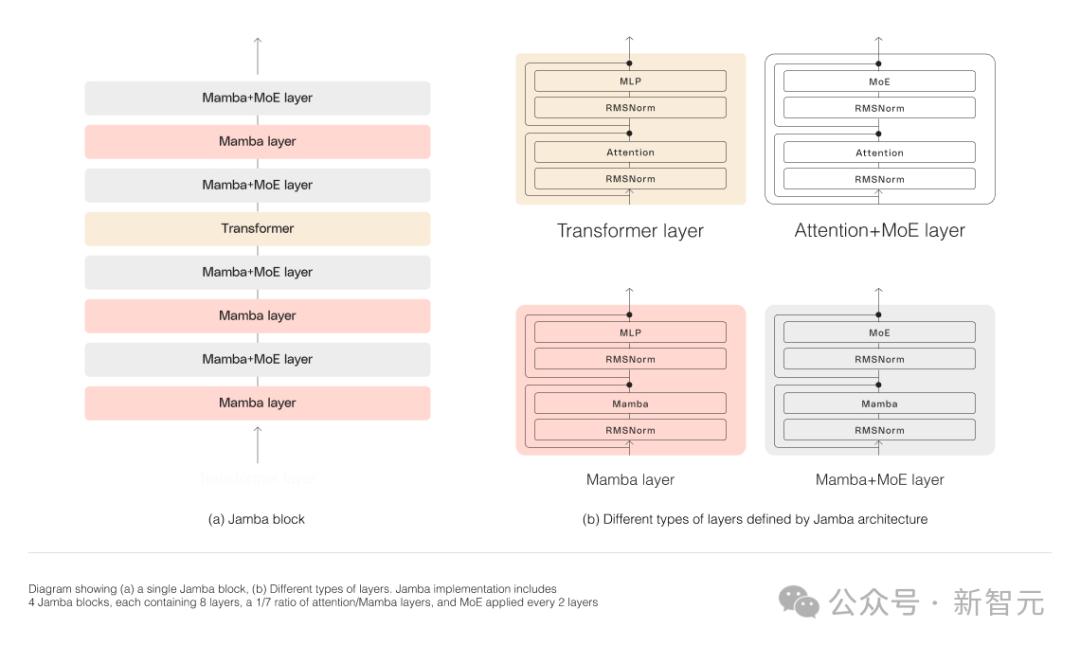
Jamba的第二个特点,是利用MoE来增加模型参数的总数,同时简化推理中使用的活动参数的数量,从而在不增加计算要求的情况下提高模型容量。
为了在单个80GB GPU上最大限度地提高模型的质量和吞吐量,研究人员优化了使用的MoE层和专家的数量,为常见的推理工作负载留出足够的内存。
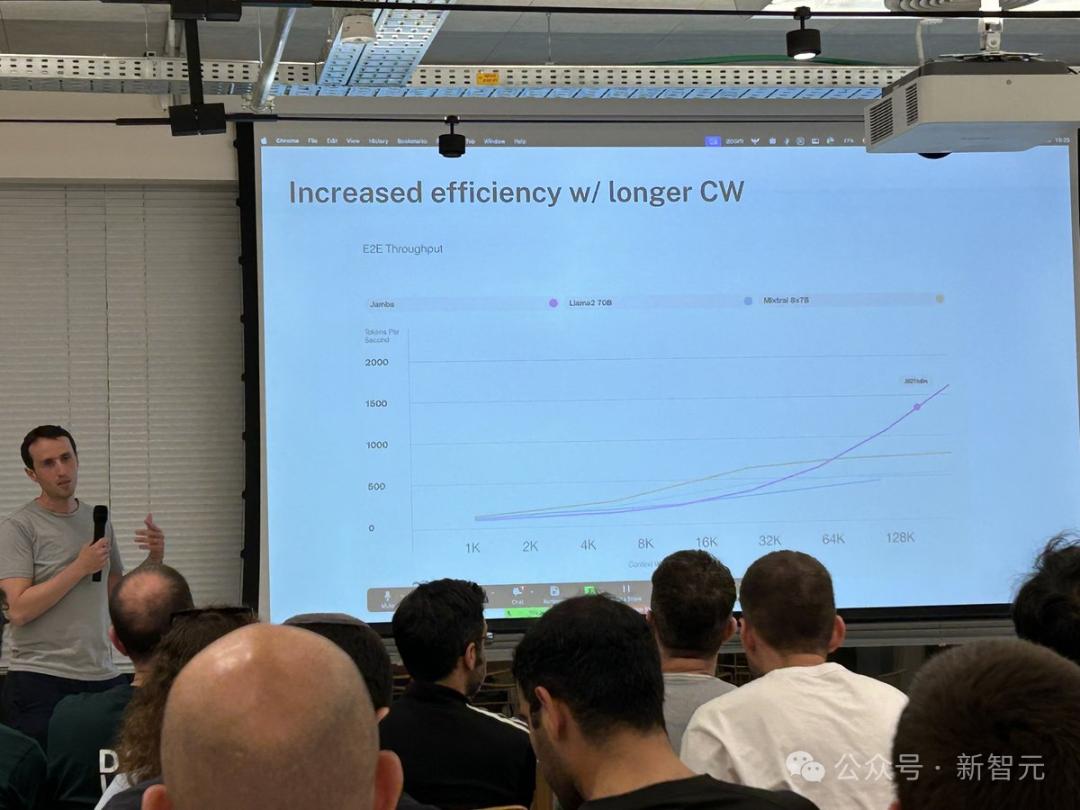
对比Mixtral 8x7B等类似大小的基于Transformer的模型,Jamba在长上下文上做到了3倍的加速。
Jamba将在不久之后加入NVIDIA API目录。
长上下文又出新选手
最近,各大公司都在卷长上下文。
具有较小上下文窗口的模型,往往会忘记最近对话的内容,而具有较大上下文的模型则避免了这种陷阱,可以更好地掌握所接收的数据流。
不过,具有长上下文窗口的模型,往往是计算密集的。
初创公司AI21 Labs的生成式模型就证明,事实并非如此。

Jamba在具有至少80GB显存的单个GPU(如A100)上运行时,可以处理多达140,000个token。
这相当于大约105,000字,或210页,是一本长度适中的长篇小说的篇幅。
相比之下,Meta Llama 2的上下文窗口,只有32,000个token,需要12GB的GPU显存。
按今天的标准来看,这种上下文窗口显然是偏小的。
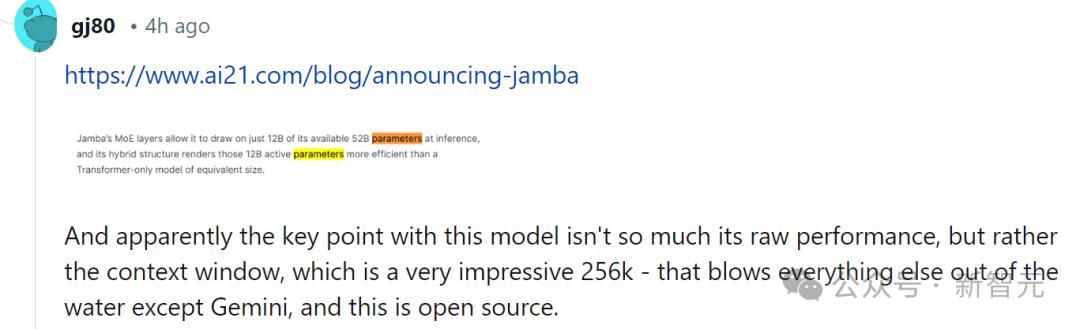
对此,有网友也第一时间表示,性能什么的都不重要,关键的是Jamba有256K的上下文,除了Gemini,其他人都没有这么长,——而Jamba可是开源的。
Jamba真正的独特之处
从表面上看,Jamba似乎并不起眼。
无论是昨天风头正盛的DBRX,还是Llama 2,现在都已经有大量免费提供、可下载的生成式AI模型。
而Jamba的独特之处,是藏在模型之下的: 它同时结合了 两种模型架构—— Transformer和 状态空间 模型 SSM 。
一方面,Transformer是复杂推理任务的首选架构。 它 最核心的定义特征,就是「注意力机制」。 对于每条输入数据,Transformer会权衡所有其他输入的相关性,并从中提取以生成输出。
另一方面,SSM结合了早前AI模型的多个优点,例如递归神经网络和卷积神经网络,因此能够实现长序列数据的处理,且计算效率更高。
虽然SSM有自己的局限性。但一些早期的代表 ,比如由普林斯顿和CMU提出的Mamba,就可以处理比Transformer模型更大的输出,在语言生成任务上也更优。
对此,AI21 Labs产品负责人Dagan表示——
虽然也有一些SSM模型的初步样例,但Jamba是第一个生产规模的商业级模型。
在他看来,Jamba除了创新性和趣味性可供社区进一步研究,还提供了巨大的效率,和吞吐量的可能性。
目前,Jamba是基于Apache 2.0许可发布的,使用限制较少但不能商用。后续的微调版本,预计会在几周内推出。
即便还处在研究的早期阶段,但Dagan断言,Jamba无疑展示了SSM架构的巨大前景。
「这种模型的附加价值——无论是因为尺寸还是架构的创新——都可以很容易地安装到单个GPU上。」
他相信,随着Mamba的继续调整,性能将进一步提高。
https://www.ai21.com/blog/announcing-jamba
https://techcrunch.com/2024/03/28/ai21-labs-new-text-generating-ai-model-is-more-efficient-than-most/
本文来自微信公众号“新智元”(ID:AI_era),作者:新智元,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK