

提速10倍+,携程OLAP指标平台优化实践 - 运维 - dbaplus社群:围绕Data、Blockchain、...
source link: https://dbaplus.cn/news-134-5933-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
提速10倍+,携程OLAP指标平台优化实践
携程火车票事业群运营着铁友、携程火车票和去哪儿火车票等重要的业务和品牌,目前正在积极地拓展海外市场。火车票的指标平台旨在为业务人员提供便捷的指标查询服务,让业务人员能够快速灵活地获得这些业务和品牌相关的指标数据。
一、早期 OLAP 架构与痛点
火车票事业群的业务涵盖了火车票、国际火车票、汽车票(含船票)等产品,错综复杂的业务也产生了多种多样订单和行为数据,通过对这些数据的分析可以揭示当前业务的发展现状,也可以为未来的发展提供方向指引。
早些时候事业群开发过一套指标平台,根据不同的指标类型使用了 3 套数据库引擎,分别是 ClickHouse,Apache Kylin (以下简称 Kylin)和 Presto,如下图所示。
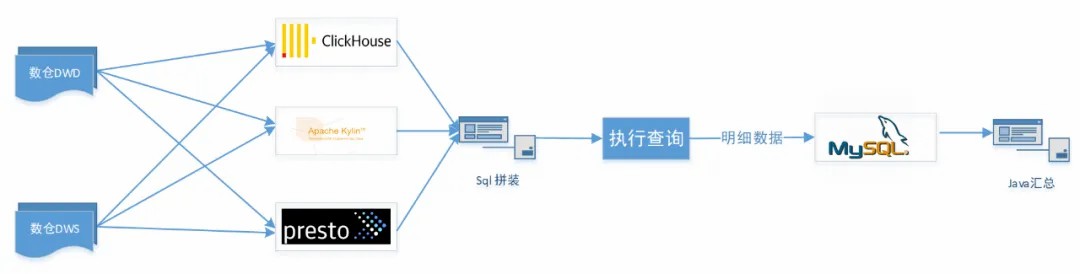
在旧版的指标平台中,为了提升查询性能使用了 ClickHouse、 Kylin 和 Presto 等多种存储和查询引擎,数据层混合使用了明细层和轻度汇总层,由此带来的问题有:
-
指标数据源混乱,容易造成口径不一致,维护成本大。
-
学习成本高,BI 同学录入指标不仅需要了解不同存储的区别,还需要掌握不同引擎的数据同步方法。
-
架构不合理,指标平台将查询的中间结果通过 jdbc 写入 mysql 后再到服务端用 java 做汇总计算,处理链路过长,整体性能非常差,导致部分指标查询需要半小时以上的等待时间。
-
鉴于这些原因,无论是用户(运营人员)还是指标开发人员,都面临着使用极差的问题。在这种情况下,我们决定使用基于一种查询速度快和使用简单的分布式数据库来重构指标平台。
二、指标平台重构整体设计
首先,重构指标平台我们首先考虑的是将多套存储合并成一套,虽说 ClickHouse 和 Kylin 已经足够强大,但是不足也很明显。
比如 ClickHouse 的 join 性能不尽如人意,并发性能差,SQL 语法是非标准的,使用起来不方便,大量的查询很容易将 CPU 打满;
Kylin 是一个分析引擎,不支持增删改操作,修改数据需要重新导入,修改 schema 需要重建 Cube(ETL成本很高),其次 Kylin 需要预先创建模型加载数据到 Cube 后才可进行查询,使用上需要具备一定的数仓知识。
于是我们将目光投向 StarRocks,StarRocks 是一款全场景的 MPP 数据库,相比 ClickHouse 等具有以下优点:
-
性能强悍:查询速度快,多张亿级表 join 也能秒级响应;
-
使用简单:兼容 MySQL 协议,用户使用门槛低;
-
支持高并发:满足大量用户同时查询;
-
支持多种数据模型:明细、聚合、更新和主键模型,可灵活配置 ETL 任务;
-
支持物化视图:可以自动路由到命中的物化视图,用户无感知;
-
支持多种导入方式:StreamLoad、SparkLoad、RoutineLoad,便于实时离线快速导入 StarRocks,流批一体。

因此,重构后的结构如下:

重构后的指标平台只有一个数据库,查询时利用 StarRocks 内部 ETL 将明细数据转存到临时表,后续的汇总从临时表查询,避免了反复扫描大表。
1.指标查询过程
当一个指标查询请求发起时,由于指标属性和用户想查看的信息不同,我们根据查询参数将查询拆解成若干子查询,子查询分为明细和汇总两类。
1)明细类子查询
-
可累加的指标查询时间范围内的明细数据,以及去年和 2019 年同期的明细数据,这部分的明细会存储到临时表,后续查询都从这张表扫描,以避免对大表的频繁扫描;该表每天生成 T+1 分区,防止增加分区失败导致当天的指标查询无法进行。
-tarpresqls "ALTER TABLE ${table} ADD PARTITION if not exists p${partition}VALUES [('${zdt.addDay(1).format("yyyy-MM-dd")}'),('${zdt.addDay(2).format("yyyy-MM-dd")}'));" \
-
如果指标不可累加或 count(distinct)类,仅存储查询时间范围内的明细,不存储用户计算同环比的明细;
-
当多个指标同时对相同维度进行查询时,将多个指标的数据 join 后以宽表模式存储。
2)汇总类子查询
这一类 sql 主要在明细的基础上根据用户的需要做相应的计算,相比旧版本在服务内部用 java 做汇总计算,这里全部借助了 StarRocks,主要的汇总功能有:
-
指标卡汇总和同环比;
-
折线图和维度下钻。
3) “缓存”
多维度特别是包含出发/到达城市组合的查询数据量非常大,耗时较长,同时避免相同的查询反复访问大表,我们增加了“缓存”功能,实现原理如下:
-
记录初次查询的指标信息,主要包括维度和维度值,时间范围,指标原始计算 sql 的 MD5 值,以及是否查询成功;
-
新的查询进入后,我们会在当天的记录中查找是否存在相同的查询。如果存在相同的查询,我们使用唯一的查询标识(groupkey)将当前查询指向上次已经执行过的查询。这样,我们可以直接读取上次查询的详细数据和汇总结果,从而提高查询效率。
-
因此这里的缓存非真实意义上的缓存,而是直接调用相同查询的结果。
2.数据同步
首先我们梳理了旧平台的数据源,从 300+ 指标的逻辑 sql 中提取了公共的 dwd 和 dim 表 51 张,并将这些数据统一同步至 StarRocks,但是对于一些指标使用的 dwd 表只出现一次的,依然将 dws 同步过来。
对于不同的 hive 表,我们使用了不同的 StarRocks 建表模型和同步方式,有以下几种:
-
全量同步:主要针对一些数据量小的表,
例如 shareout_trn.dim_ibu_alliance,大小为 608k;
-
增量分区同步:每天同步 hive 表中 T-1 的分区,各分区之间独立;
-
更新同步:火车票 BU 的一些订单数据由于涉及到预售和订单状态的变更,变更的数据时间跨度比较大,将跨度范围内的数据全部更新代价比较高,因此使用更新模型。
数据导入更新模型直接需要计算 T-1 和 T-2 分区有差异的数据,这里将所有字段使用 concat_ws('|',***)拼接后取 hash 值,之后 join 找到 hash 值不一致的数据。
模型KEY设置:UNIQUE KEY(`order_id`)取两天有差异的数据:selectt1.*from(select … where d='${cur_day}') as t1left join(select … where d=’${pre_day}’) as t2on t1.business_pk_id=t2.business_pk_idwhere t1.hash_code!=t2.hash_code or t2.order_id is null
-
每天同步当月数据:如国际火车的访问数据量较小,每天一个分区会导致 StarRocks 集群有很多小的 bucket,分桶数太多会导致元数据压力比较大,数据导入导出时也会受到一些影响,因此我们按月设置分区,每天同步当月的数据。
时间范围:startdate='${zdt.format("yyyy-MM-01")}'endDate='${zdt.add(2,1).format("yyyy-MM-01")}'表设计:PARTITION BY RANGE(dt)(Start("2019-01-01") End("2023-03-01") Every(Interval 1 month))DISTRIBUTED BY HASH(分桶字段) BUCKETS 桶的数量PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.prefix" = "p","dynamic_partition.time_unit" = "month","dynamic_partition.end" = "1");datax配置:-temporary_partitions "tp${partition}" \-tarpresqls "ALTER TABLE ${table} DROP TEMPORARY PARTITION if exists tp${partition};ALTER TABLE ${table} ADD PARTITION if not exists p${partition} VALUES [('${startdate}'),('${endDate}'));ALTER TABLE ${table} ADD TEMPORARY PARTITION tp${partition} VALUES [('${startdate}'),('${endDate}'));" \-tarpostsqls "ALTER TABLE ${table} REPLACE PARTITION (p${partition}) WITH TEMPORARY PARTITION (tp${partition});"
此外,对于 UBT 类数据,数据量级非常大,并且常见用于查询 PV,UV 和停留时长等比较固定的场景,于是我们从中抽取出三张表:
-
ubt_for_pv:每天按维度汇总 count(uid),每天数据大小只有几十 K;
-
ubt_for_duration:每天按维度汇总 sum(duration),如需要计算平均停留时长除以对应的 pv 即可;
-
ubt_for_uv:每天按维度去重,尽最大可能减少数据量。
最后,鉴于上游表的迭代可能带来的数据的不稳定,我们对需要同步的表的数据量做了监控,若发现当天的数据量波动超过 3sigma,监控任务自动发出邮件告警,这些 job 的同步都在 15 分钟内完成。
三、Starrocks使用经验分享
在指标平台重构的过程中我们也遇到了一些问题,与数据和查询相关的有以下几个:
1.建表经验
首先是 buckets 设置不合理,多数是设置过多,通常一个桶的数据量在 500MB~1GB 为好,个别表设置的桶数量太少,导致查询时间长;其次是分区不合理,有些表没有设置分区,有些设置的分区后每个分区数据量很小,优化建议是将不常访问的数据按月分区,经常访问的数据按日分区。
2.数据查询
由于指标的查询sql之前是针对不同引擎编写,很多引擎是没有索引的,比如 Presto。StarRocks 有丰富的索引功能,统一至 StarRocks 希望利用索引加速查询,因此过滤条件中最好不要加函数,比如 select c1 from t1 where upper(employeeid) = upper(' s1')修改成select c1 from t1 where employeeid in(upper(' s1'), lower(' s1'))。
另外很多 sql 没有使用分区,在 StarRocks 中将会全表扫描造成资源浪费。
3.函数问题
StarRocks 的 split 函数结果的下标从 1 开始,而 sparksql 等引擎对应的是从 0 开始,导致 sql 在 StarRocks 执行查询的时候不报错但是结果错误。
select split('a,b,c',',')[0] StarRocks查询结果为空,其他引擎查询结果为‘a’select split('a,b,c',',')[1] StarRocks查询结果为‘a’,其他引擎查询结果为‘b’
四、查询性能大幅提升
指标平台的重构主要是为了解决查询性能的问题,并且重构后也基本达到了预期。重构之前,复杂查询需要数分钟的时间才能完成。特别对于火车票相关指标,诸如出票票量指标,如果带上出发和到达城市查询,可能需要等待 30 分钟以上,并且查询失败率较高。
而在重构后,查询时间大大缩短,复杂查询在 10s 左右,并且 P99 在 2 秒之内,因此整体体验得到显著提升,用户查询次数相比改造前也有了翻倍的增长。
此外,现在新指标系统还丰富了更多功能,比如同环比和维度下钻计算。得益于 StarRocks 的并发能力,我们可以在生成子查询 SQL 后并发提交,从而大幅度减少响应时间,使得用户在进行维度下钻时几乎无需等待即可快速获取所需数据。
五、 后续优化方向
目前,UV 类的 Count Distinct 查询是基于存储了大量明细数据的方式进行的。然而,对于部分指标,我们可以尝试使用 Bitmap 来减少不必要的明细数据存储空间,并且更重要的是可以提高查询速度。在接下来的工作中,我们计划尝试这种方案,以进一步优化 UV 类指标的查询性能。
对于全量或增量更新的表使用聚合模型,聚合模型会对导入后具有相同维度的数据做预聚合,查询的时候减少扫描数据的行数达到提升查询速度的目的。
当前的指标平台计算过程将所需的数据写入临时表,后续改成使用物化视图,在达到同样效果的情况下减少了复杂度。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK