

对大型语言模型的安全性能进行基准测试,谁更胜一筹?
source link: https://www.51cto.com/article/784351.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
对大型语言模型的安全性能进行基准测试,谁更胜一筹?
大型语言模型(LLM)机器学习技术正在迅速发展,催生了多个相互竞争的开源和专有架构。除了与ChatGPT等平台相关的生成式文本任务外,LLM还被证实在许多文本处理应用程序中具有实用价值,可以协助编写代码以及对内容进行分类。
SophosAI研究了许多在网络安全相关任务中使用LLM的方法。但考虑到LLM的多样性,研究人员面临着一个具有挑战性的问题:如何确定哪种模型最适合特定的机器学习问题。选择模型的一个好方法是创建基准任务,以便轻松快速地评估模型处理典型问题的能力。
目前,LLM是在某些基准上进行评估的,但这些测试只衡量了这些模型在基础自然语言处理(NLP)任务上的通用能力。Huggingface Open LLM排行榜使用了七个不同的基准来评估Huggingface上所有可访问的开源模型。
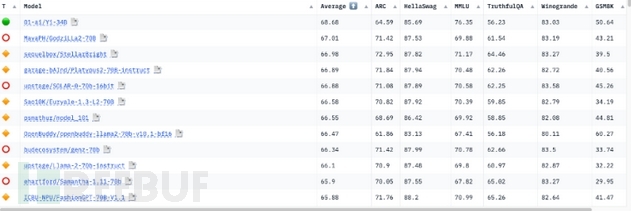
【图1:Huggingface Open LLM排行榜】
然而,这些基准任务的性能可能无法准确反映模型在网络安全环境中的工作性能。由于这些任务是通用化的,因此它们可能无法揭示由训练数据产生的模型在特定于安全的专业知识方面的差异。
为了克服这一点,SophosAI研究团队创建了下述三个基于任务的基准,在研究人员看来,这些任务是大多数基于LLM的防御性网络安全应用程序的基本先决条件:
- 通过将有关遥测的自然语言问题转换为SQL语句,充当事件调查助手;
- 从安全运营中心(SOC)数据生成事件摘要;
- 评定事件严重程度。
这些基准测试有两个目的:确定具有微调潜力的基础模型,然后评估这些模型的开箱即用(未调优)性能。研究人员根据模型大小、流行程度、上下文大小等标准选择了以下模型进行分析:
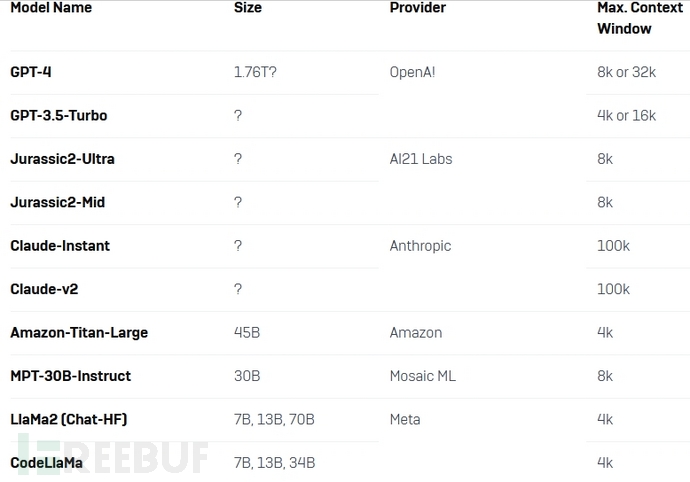
【接受基准测试的模型】
任务1:事件调查助手
在第一个基准测试任务中,主要目标是评估LLM作为SOC分析师助手的性能,通过基于自然语言查询检索相关信息来调查安全事件。在上下文模式知识的指导下,评估LLM将自然语言查询转换为SQL语句的能力,有助于确定它们是否适合此任务。
研究人员把这个任务看作是一个few-shot(一种提示技巧)提示问题。最初,他们向模型提供将请求转换为SQL所需的指令。然后,他们为这个问题创建的所有数据表提供模式信息。最后,他们提供了三对示例请求及其对应的SQL语句作为模型的示例,以及模型应该转换为SQL的第四对请求。
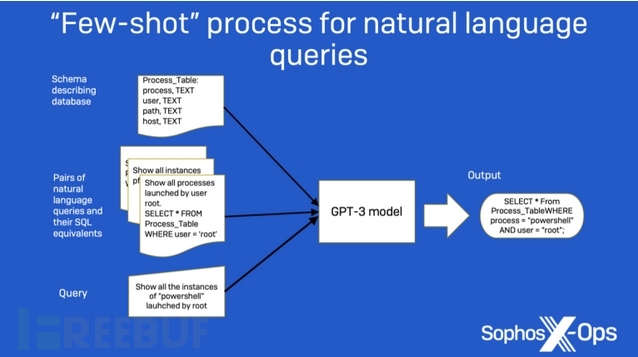
【图2:显示原始自然语言查询研究中使用的“few-shot”方法的图表】
这个任务的提示示例如下:
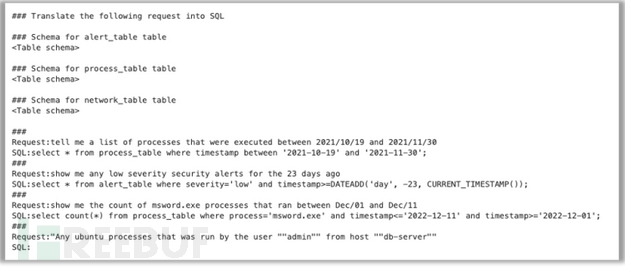
【图3:事件调查助手基准测试中使用的示例提示】
每个模型生成的查询的准确性是通过检查输出是否与预期的SQL语句完全匹配来衡量的。如果SQL不完全匹配,那么研究人员就会对创建的测试数据库运行查询,并将结果数据集与预期查询的结果进行比较。最后,研究人员将生成的查询和期望的查询传递给GPT-4,以评估查询的等效性。
测试结果:
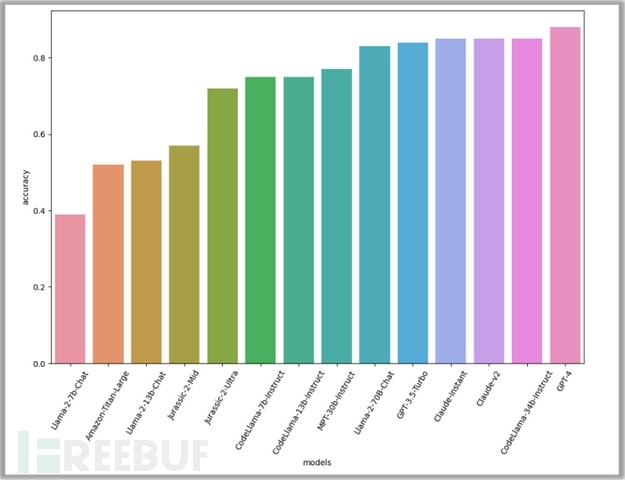
【图4:查询生成基准的结果为OpenAI的GPT -4最准确,Meta的CodeLlaMa 34b、Anthropic的Claude模型和OpenAI的GPT-3.5 Turbo紧随其后】
根据评估,GPT-4表现最好,准确率达到88%。紧随其后的是另外三个模型:CodeLlama-34B-Instruct和两个Claude模型,准确率均为85%。CodeLlama在这项任务中的出色表现是意料之中的,因为它专注于生成代码。
总体而言,较高的准确率分数表明该任务对模型来说很容易完成。这表明,这些模型的开箱即用性能可以有效地帮助威胁分析人员调查安全事件。
任务2:事件摘要
在安全运营中心,威胁分析人员每天需要调查大量的安全事故。通常,这些事故表现为发生在用户端点或网络上的一系列事件,且与已检测到的可疑活动相关。威胁分析人员可以利用这些信息进行进一步调查。然而,对于分析人员来说,这一系列的事件通常是异常繁杂的,并且需要花费大量时间来浏览,这使得识别关键事件变得困难。这就是LLM可能发挥作用的地方,因为它们可以帮助识别和组织基于特定模板的事件数据,使分析人员更容易理解正在发生的事情并确定下一步行动。
对于这个基准测试,研究人员使用来自托管检测和响应(MDR) SOC的310个事件的数据集,每个事件都格式化为一系列JSON事件,并根据捕获传感器不同分为不同的模式和属性。数据连同汇总数据的指令和用于汇总过程的预定义模板一起传递给模型。
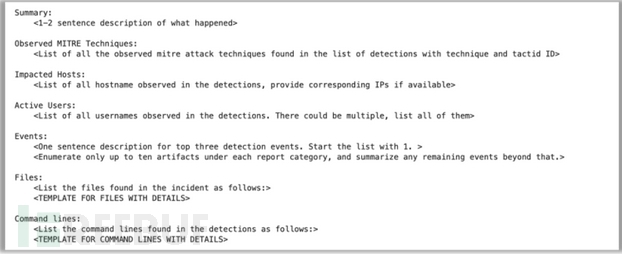
【图5:用于为事件摘要基准传递数据的模板】
研究人员使用了五个不同的指标来评估每个模型生成的摘要。首先,他们通过将生成的事件描述与“黄金标准”摘要(该摘要是Sophos分析师在GPT-4生成的最初版本基础上进行改进和纠正形成的)进行比较,来验证每个模型生成的事件描述是否成功地从原始事件数据中提取了所有相关细节。

【图6:“黄金标准”摘要最初由GPT-4生成,然后由威胁分析人员手动检查和修改,以确保准确性】
如果提取的数据不完全匹配,研究人员将通过计算从事件数据中提取的每个事实的最长公共子串(Longest Common Subsequence)和Levenshtein距离,来测量提取的所有细节与人类生成的报告的差距,并为每个模型计算平均分数。他们还使用BERTScore指标以及METEOR评估指标来评估摘要描述。
测试结果:
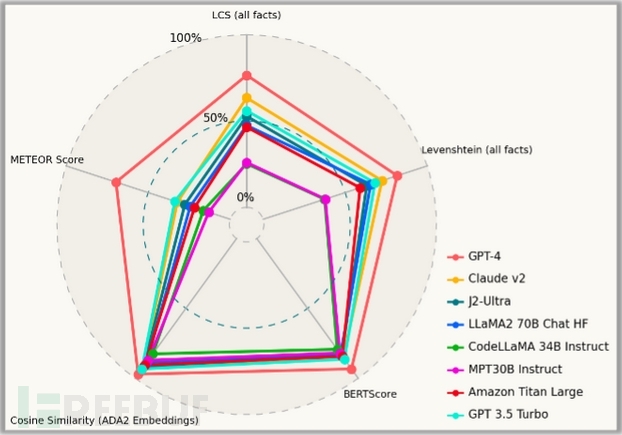
【图7:事件摘要基准测试前8名模型】
在此次测试中,GPT-4再次脱颖而出,成为优势明显的赢家,在各方面的表现都显著优于其他模型。但是GPT-4在一些定性指标上存在不公平的优势,尤其是基于嵌入的指标,因为用于评估的“黄金标准”是在GPT-4本身的帮助下开发的。
在其他模型中,Claude-v2模型和GPT 3.5 Turbo在专有模型领域表现优异;Llama-70B型号是性能最好的开源模型。然而,研究人员也观察到MPT-30B-Instruct模型和CodeLlama-34B-Instruct模型在产出良好的描述方面存在困难。
这些数字并不一定能完全说明这些模型对事件的总结有多好。为了更好地掌握每个模型发生了什么,研究人员仔细查看了由它们生成的描述,并对它们进行了定性评估。(为了保护客户信息,这里将只显示生成的事件摘要的前两个部分。)
GPT-4在总结方面做得不错;摘要虽然有点啰嗦,但很准确。GPT-4还正确提取了事件数据中的MITRE技术。然而,它忽略了区分MITRE技术与战术的首行缩进细节。

【图8:在人工审阅之前,GPT-4的后续版本自动生成的摘要】
Llama-70B也正确地提取了所有的细节。然而,它忽略了摘要中的一个事实(该帐户被锁定)。在总结中也未能将MITRE技术与战术区分开来。

【图9:Llama-70B生成的摘要】
另一方面,J2-Ultra表现不佳。它重复了三次MITRE技术,完全遗漏了战术。不过,好在摘要似乎非常简明扼要。
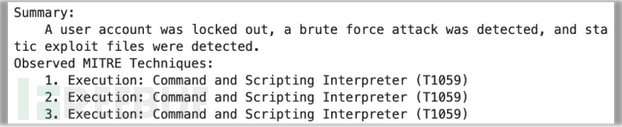
【图10:J2-Ultra生成的摘要】
MPT-30B-Instruct表现完全失败,只是生成了一个段落,总结了它在原始数据中看到的内容。

【图11:MPT-30B的(编辑过的)摘要输出】
同样地,CodeLlaMa-34B的输出也是完全不可用的。它反刍了事件数据而非摘要,甚至部分“幻觉”了一些数据。
任务3:事件严重性评估
研究人员评估的第三个基准测试任务是传统ML-Sec问题的改进版本:确定观察到的事件是无害活动的一部分还是攻击的一部分。
这项任务的目标是确定LLM是否可以检查一系列安全事件并评估其严重程度。为此,研究人员指示模型从五个选项中分配严重性等级:关键、高危、中危、低危和信息性。下面是研究人员为该任务提供给模型的提示格式:

【图12:用于事件严重性评估的提示结构】
该提示解释了每个严重级别的含义,并提供了与前一个任务相同的JSON检测数据。由于事件数据来源于实际事件,研究人员拥有每个案例的初始严重性评估和最终严重性级别。
测试结果:
研究人员针对3300多个案例评估了每个模型的性能并测量了结果,结果显示它们都没有表现出比随机猜测更好的性能。研究人员使用最近邻进行了zero-shot设置(蓝色)和3-shot设置(黄色)实验,但两个实验都没有达到30%的准确率阈值。
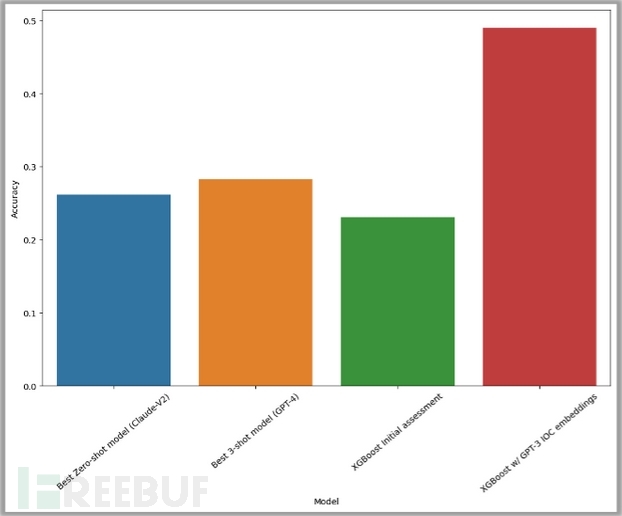
【图13:严重性分类测试的最佳结果】
作为基线比较,研究人员使用了XGBoost模型进行初始评估,这个性能用绿色条表示。
此外,研究人员还尝试将GPT-3生成的嵌入应用于警报数据(用红色条表示)。结果观察到其性能显著提高,准确率达到50%。
总的来说,大多数模型都不具备执行这种任务的能力。在此过程中,研究人员也观察到了一些有趣的失败行为,包括生成额外的提示指令、反刍检测数据,或是编写生成严重性标签作为输出的代码,而不是仅仅生成一个标签。
为安全应用程序使用哪种模型是一个微妙的问题,涉及许多不同的因素。这些基准测试为起点提供了一些需要考虑的信息,但不一定能解决每个潜在的问题集。
大型语言模型在协助威胁搜索和事件调查方面还是有效的。然而,它们仍然需要一些限制和指导。我们相信这个潜在的应用可以使用开箱即用LLM,通过精心的提示工程来实现。
当涉及到从原始数据总结事件信息时,大多数LLM整体表现良好。然而,评估单个工件或工件组对于预先训练和公开可用的LLM来说仍然是一项具有挑战性的任务。为了解决这个问题,可能需要一个专门接受过网络安全数据培训的LLM。
就纯粹的性能而言,我们可以看到GPT-4和Claude v2在所有基准测试中表现最好。然而,CodeLlama-34B模型在第一个基准测试任务中表现出色,获得了荣誉提名,我们认为它是可以作为SOC助手部署的有竞争力的模型。
原文链接:https://news.sophos.com/en-us/2024/03/18/benchmarking-the-security-capabilities-of-large-language-models/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK