

PAI-ChatLearn :灵活易用、大规模 RLHF 高效训练框架(阿里云最新实践)
source link: https://www.51cto.com/article/780646.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

PAI-ChatLearn 是阿里云机器学习平台 PAI 团队自主研发的,灵活易用、大规模模型 RLHF 高效训练框架,支持大模型进行 SFT(有监督指令微调)、RM(奖励模型)、RLHF(基于人类反馈的强化学习)完整训练流程。PAI-ChatLearn 支持训练和推理组合使用不同的 backend,可对各个模型配置不同并行策略和灵活的资源分配,支持大规模(175B + 175B)模型的 RLHF 高效训练,性能比业界框架有较大提升,有助于用户专注于模型效果调优。
一、大模型训练方式演进
随着大模型的快速发展,推动了模型训练方式(特别是深度学习和人工智能领域)不断演进。随着模型规模的增长,单个设备(如 GPU 或 CPU)的内存和计算能力已经不足以处理整个模型,因此需要采用并行化策略来分配任务和计算负载。下面分别介绍模型训练的数据并行、模型并行和任务并行。
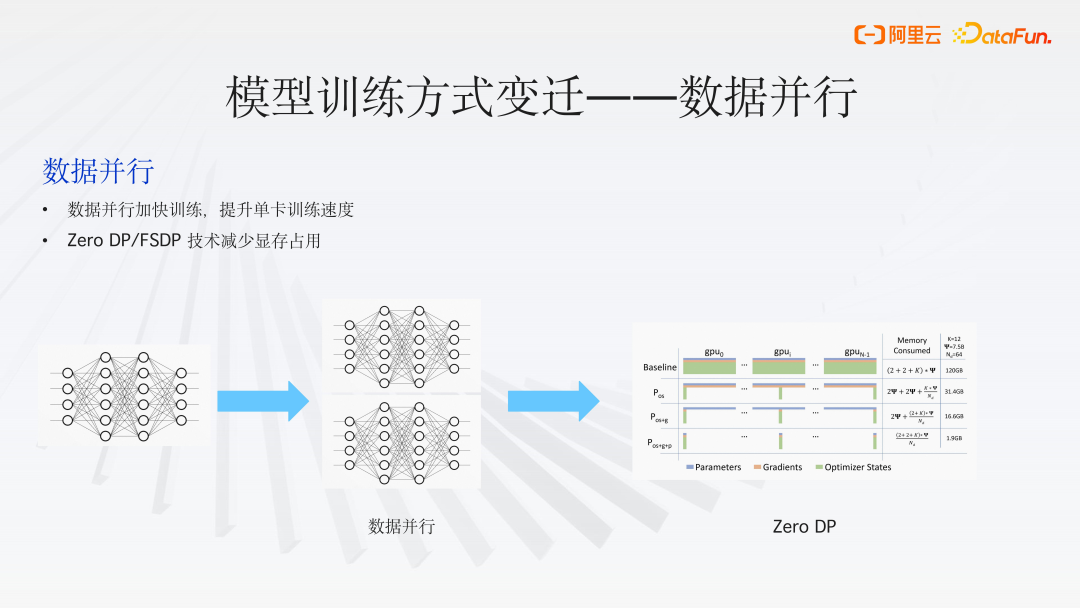
1、数据并行(Data Parallelism)
早期的深度学习模型相对较小,如经典的卷积神经网络模型 AlexNet 和 ResNet,可在单个 GPU 上顺利运行。然而,随着图像数据量的激增,单 GPU 的训练性能逐渐无法满足需求。为了应对这一挑战,模型训练开始采用数据并行策略来加速。
数据并行(Data Parallelism)是将训练数据集分割成多个小批次,并在多个处理器或设备上同时训练模型的副本。每个设备都有模型的一个完整副本,并且在每个训练步骤结束时,通过某种形式的通信(如梯度平均或参数服务器)来同步模型参数。
数据并行(Data Parallelism)策略本身也经历了一系列的演进。例如,Zero Redundancy Optimizer (ZeRO) 和 Fully Sharded Data Parallel (FSDP) 等概念的出现,它们的核心思想是在训练过程中将状态信息、梯度或模型参数分散存储,而计算过程仍然遵循数据并行的原则。将训练数据集分割成多个小批次,并在多个处理器或设备上同时训练模型的副本。每个设备都有模型的一个完整副本,并且在每个训练步骤结束时,通过某种形式的通信(如梯度平均或参数服务器)来同步模型参数。
这种方法可以显著减轻每个 GPU 上的显存压力,使得我们能够训练更大的模型。但随着模型规模的增加,数据并行策略需要更高效的通信机制和更大的带宽来处理增加的同步负载。
2、模型并行
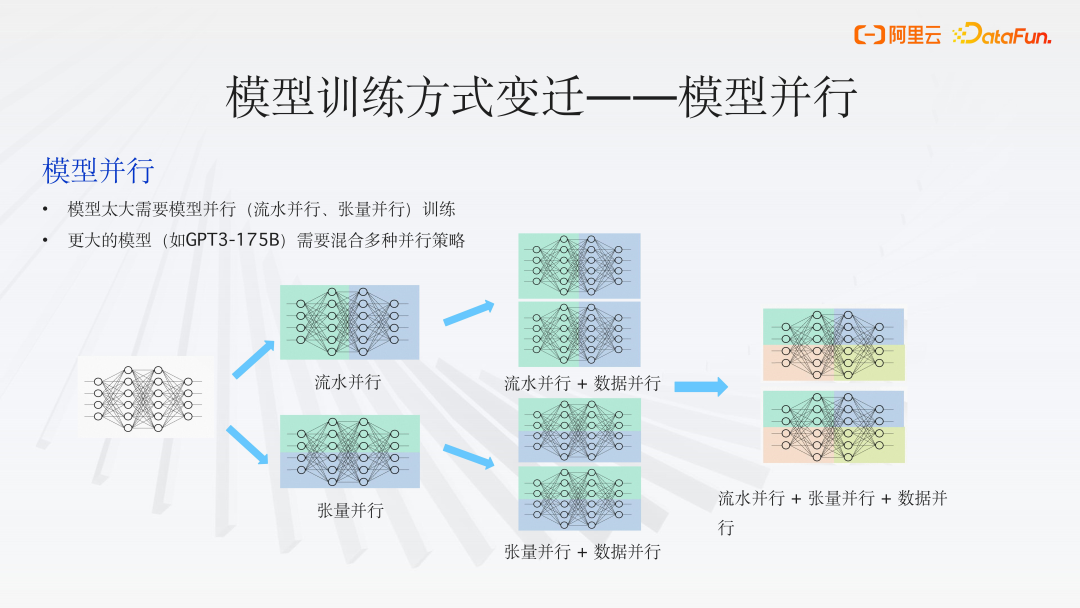
随着模型规模的进一步扩大,纯粹的数据并行已不足以满足训练需求。我们面临的挑战不仅是显存容量不足,还包括计算能力的限制。因此,模型并行(Model Parallelism)成为了一种大规模深度学习模型训练的常用解决方案。
模型并行依据模型切分方法主要分为两种形式:流水并行(Pipeline Parallelism)和张量并行(Tensor Parallelism):
- 张量并行
将模型的张量(Tensor)切分成多个片段,每个计算单元(如GPU)负责存储和计算其中的一部分。这种方法可以有效地减少每个计算单元上的内存占用,从而支持更大模型的训练。
缺点:可能会导致大量的跨设备通信,因此它更适合于具有高带宽的内部机器通信,如使用 NVLink 的场景。 - 流水并行(Pipeline Parallelism)
将模型按照层(Layer)进行切分,每个计算单元负责模型中一部分层的计算。这种方式同样可以减轻单个计算单元的内存负担,并且有助于支持更大规模的模型训练。通信需求相对较小,适合于基础设施较弱、带宽较低的环境。
缺点:可能会引入大量的空闲时间(Bubbles),需精心设计流水线以避免产生大量的等待时间。 - 其他模型并行变体
Mixture of Experts (MoE) 中的专家并行(Expert Parallelism)会将专家模块分布到不同的计算单元上。
序列并行(Sequence Parallelism)会在训练过程中将激活函数的输出(Activation)分散存储,以此减少显存占用。
单一的模型并行往往难以高效地支持模型训练。更大的模型(如GPT3-175B)需要混合多种并行策略。混合并行(Hybrid Parallelism)结合了数据并行、模型并行和任务并行的优点,以实现更高效的训练。如,可以在多个设备上使用数据并行来训练模型的不同副本,同时在每个设备内部使用模型并行来处理模型的不同部分。
3、任务并行
随着模型的不断演进,模型训练方式出现了一些新的趋势。任务并行不是直接针对模型或数据的并行化,而是将不同的任务分配给不同的处理器或设备。在大模型训练中,任务并行可以用来同时执行多个不同的训练过程,例如,同时进行超参数搜索、模型评估或不同模型的训练。任务并行可以提高资源利用率和训练效率,但需要有效的任务调度和管理机制。
- 多任务/多模态模型训练
需要在任务维度进行并行训练,如谷歌提出的 Pathways 架构,不同任务之间可能会共享参数。又如 GPT-4v,是多模态模型,能处理语音、文本等不同类型的数据。 - 大模型结合 RLHF 来提升模型效果,如 ChatGPT、GPT4 等都进行了 RLHF。
- 从单程序多数据(SPMD)模式向多程序多数据(MPMD)模式转变。

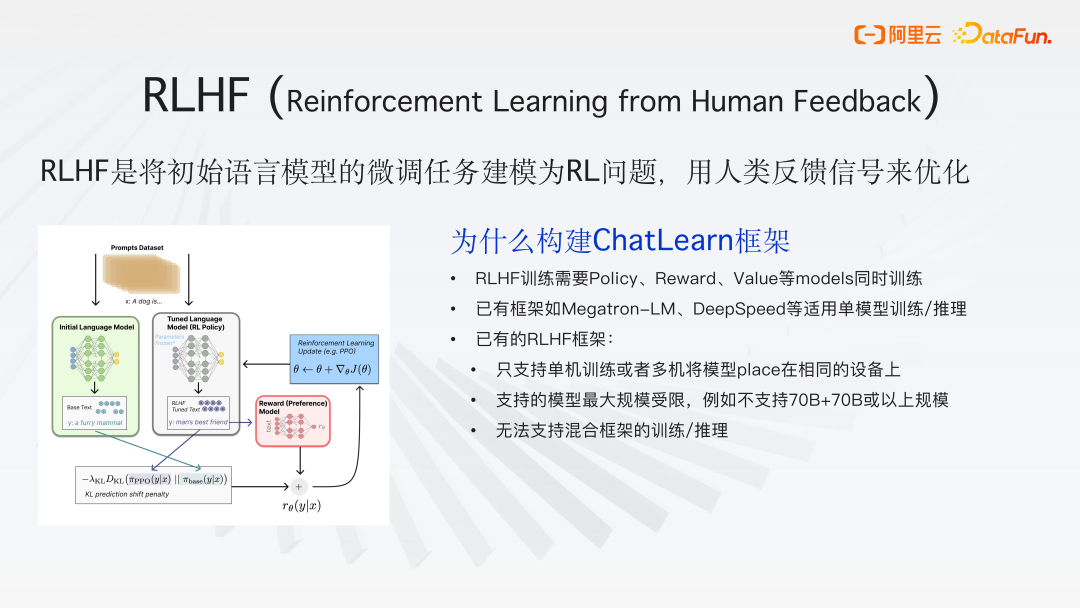
(1)RLHF
RLHF (Reinforcement Learning from Human Feedback)是将初始语言模型的微调任务建模为 RL 强化学习问题,用人类反馈信号来优化,使生成更符合人类的期望,提高模型的性能和可靠性。
训练步骤:

- 步骤一:预训练语言模型
预训练语言模型,并进行 SFT(Supervised Fine-Tuning),在人工精心撰写的语料上进行微调。
开源的预训练模型:Qwen、LLaMA、Baichuan 等。 - 步骤二:训练奖励模型(RM)
训练奖励模型判断模型生成的文本是否符合人类偏好。
开源的奖励模型:Ziya-LLaMA-7B-Reward 等。 - 步骤三:使用强化学习进行微调
结合人类反馈信号,使用强化学习来微调模型。
社区模型:ChatGPT、GPT4、GPT4-Turbo 等。
(2)ChatLearn 框架构建必要性
RLHF训练需要Policy、Reward、Value 等 models 同时训练。已有框架如 Megatron-LM、DeepSpeed 等适用于单模型训练/推理。已有的 RLHF 框架只支持单机训练或者多机将模型 place 在相同的设备上,支持的模型最大规模受限,不支持 70B+70B 或以上规模,并且无法支持混合框架的训练/推理。
二、PAI-ChatLearn 框架介绍
本节主要介绍 PAI-ChatLearn 框架的底层实现细节、接口如何定义以及如何实现大规模高效的 RLHF 训练。
1、PAI-ChatLearn 框架
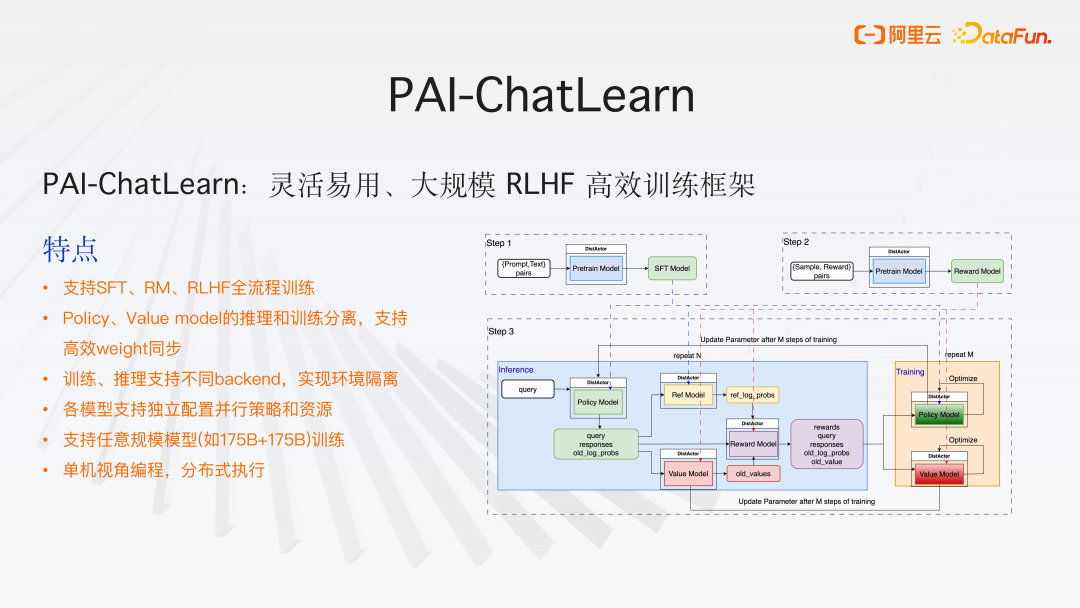
PAI_ChatLearn 是一个灵活且适用于大规模 RHF 训练的高效框架,其特点如下:
- 支持 SFT(有监督的微调)、RM(奖励模型)、RLHF 全流程训练
- Policy、Value model 的推理和训练分离,支持高效 weight 同步
由于训练和推理的特点不同,所需资源和并行策略也不尽相同。
HF 训练过程较复杂,(如策略模型(Policy Model)既参与生成(generation)也参与训练(training)),会对模型进行分割,如将推理(inference)和训练的模型分开,采用不同的并行策略,以实现高效的训练和推理。
实现了基于高速通道的参数同步机制,以确保模型参数的最终一致性,实现更高效的训练。 - 训练、推理支持不同 backend,实现环境隔离。如在训练中可以使用 Megatron 作为后端,而在推理中可以使用 VIM 框架,这样的组合可能会达到更好的效果。
- 各模型支持独立配置并行策略和资源,分布式 actor 的设计。
- 支持任意规模模型(如 175B+175B)训练
- 单机视角编程,分布式执行,用户在编写代码时不需要关心底层模型的分配和执行。
下图是在 PAI_ChatLearn 中实现的 RLHF 训练流程的图示。
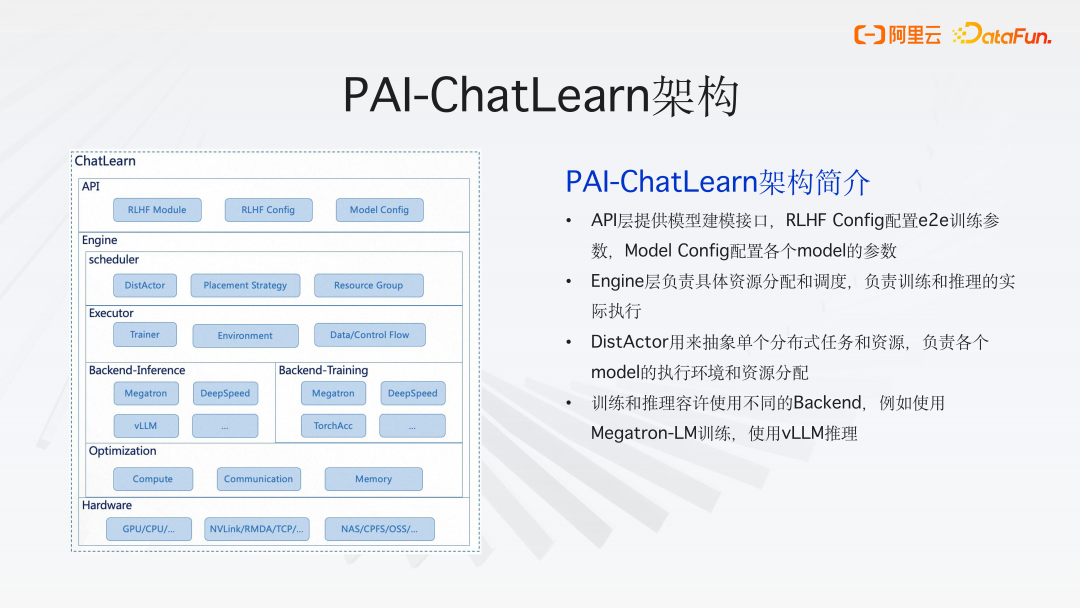
2、PAI-ChatLearn 架构简介
(1)API 层
API 层提供模型建模的接口
- RLHF Module 是一个通用的抽象 RLHF 模块接口。通过这个接口,用户只需实现一些方法的封装,就可以完成不同模型的构建。
- RLHF Config 配置 e2e 训练参数
- Model Config 配置各个 model 的参数
(2)引擎层
Engine 层负责具体资源分配和调度,以及训练和推理的实际执行。
- DistActor 用来抽象单个分布式任务和资源,负责各个 model 的执行环境和资源分配,可实现灵活扩展。
- 训练和推理容许使用不同的 Backend。如推理可以使用 PyTorch 或 vLLM 框架,训练后端可以选择 Megatron、DeepSpeed 或自研的框架。
- 还进行了各种优化,包括计算、通信和显存优化,以确保训练性能。
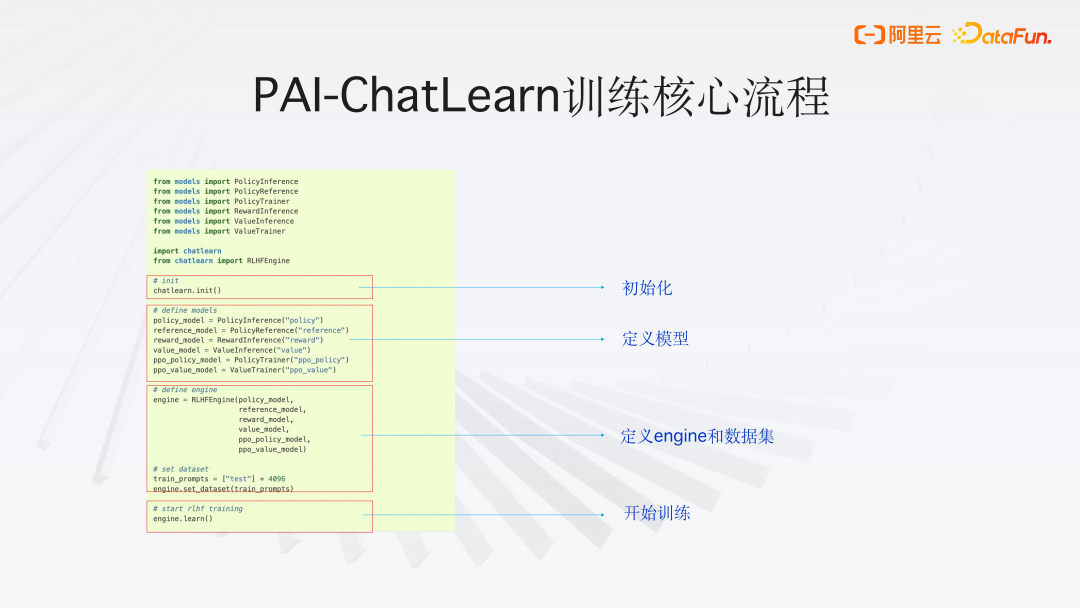
3、PAI-ChatLearn 训练核心流程
PAI-ChatLearn 训练核心流程如下,首先对 chatlearn 进行初始化,接着定义模型(RLHF 训练过程包含 2 个 training 模型,4 个模型做 inference),然后定义 Engine 和数据集,调用 engine.learn() 开始训练。
4、PAI-ChatLearn 训练配置
运行环境配置
PAI-ChatLearn 训练框架中,用户通过 YAML 文件来配置整个运行环境,无论是 PAI 的执行环境 DLC 还是本地 local 环境,都可灵活配置。
在任务分发过程中,采用了一种内部优化策略,即通过 'exclude' 功能,可以明确指定不需要分发的组件。从而有效减少不必要的通信开销,提高整体效率。
每个模型有独立的配置选项,允许用户根据需要自定义资源分配和策略。在 RLHF 中,支持六种不同的模型配置。
RLHF 训练配置
用户可以定义诸如实际运行的数量、训练批次大小、生成任务的基线大小等参数。此外,还可以设置定期保存检查点的时间间隔、数据存储路径以及评估模型性能的时间点。

PAI-ChatLearn 框架提供了清晰的配置流程,用户只需定义模型并添加相应的配置,即可轻松启动训练过程。
5、PAI-ChatLearn 接口-模型定义

为了加速模型构建过程,我们提供了一系列的子类,这些子类旨在简化和加快开发流程。无论是基于 PyTorch、Meta 还是 VIM 的框架,这些子类都能够提供强大的支持。同时,用户可以选择基于这些子类或者直接基于父类来构建 HF 模型。
在 PAI-ChatLearn 框架中,模型的封装变得很简单。用户只需关注模型的设置和构建过程,例如初始化(init)环节。封装层旨在屏蔽不同框架之间的接口差异,使得用户只需在我们的框架中进行一层封装。例如,如果用户需要实现前向传播(forward steps),无论是仅进行推理还是进行完整的训练周期,我们的封装都能够简化这一过程。用户只需将模型中已定义的训练模块进行整合,即可实现标准模型训练的流程。
此外,框架提供了底层接口的灵活选择,以适应不同的执行需求。用户可以选择 Megatron 作为执行引擎,VIM 作为后端,或者采用我们团队自研的高性能计算机 HC 作为后端资源。这种自由切换的能力确保了用户可以根据具体需求和偏好选择最合适的工具和资源。
三、PAI-ChatLearn 使用示例
本节基于开源模型示例讲解模型 RLHF 训练的具体流程及训练效果。
1、开源 transformers 模型示例
(1)镜像和模型准备
PAI-DLC 平台上提供已经准备好的镜像或参考 ChatLearn 提供的 Dockerfile 自定义镜像
下载开源模型,例如从 Huggingface 或 ModeScope 上下载。
如果是 HuggingFace transformers 的模型,调用 ChatLearn 提供的工具将 transformers 模型转成 Megatron-LM 格式,支持修改模型的并行策略。
(2)训练步骤
步骤一:训练 SFT 模型
准备 SFT 训练的数据:
格式:{'query':问题,'response':回复}。
训练方式:
转换好的模型,调用 ChatLearn 进行 SFT 训练。
训练好保存 SFT 模型
如果有训练好的SFT 模型,这个步骤可以跳过。
步骤二:训练奖励模型(RM)。
准备 RM 训练的数据:
格式:{'query':问题,'response':[回复1, 回复2, .....],'score':[score1,score2,.....]}。
训练方法:
定义 RM,一般主体结构复用 SFT,增加一个 head 层。
使用训练好的 SFT 模型参数初始化 RM。
调用 ChatLearn 进行 RM 训练。
保存训练好的模型。
步骤三:使用强化学习进行微调。
准备 RL 训练的数据:
格式:{"prompt":问题}。
训练方法:
定义 Policy/Reference Model,结构和 SFT 模型一致。
使用 SFT 模型参数初始化 Policy/Reference Model。
定义 Reward/Value model,结构和 Reward Model 一致。
使用 RM 模型参数初始化 Reward/Value model。
调用 ChatLearn 进行 RLHF 训练。
保存训练好的模型。
步骤四:Inference。
离线批量预测。
准备好需要预测的数据集合。
调用 ChatLearn 加载训练好的 RLHF 模型进行离线批量预测。
在线预测。
调用 ChatLearn 工具将训练好的 RLHF 模型转成 Transformer 格式。
调用 PAI-EAS 或 vLLM 部署模型进行在线预测。
2、Vicuna 13B+13B 训练效果
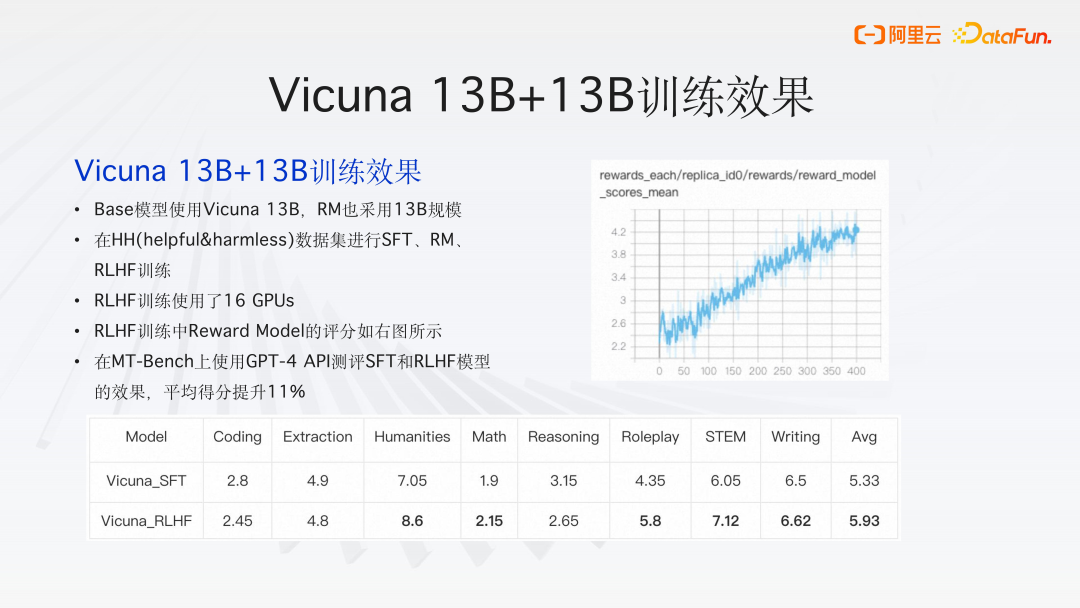
Base 模型使用 Vicuna 13B,RM 也采用 13B 规模。
在 HH(helpful&harmless)数据集进行 SFT、RM、RLHF 训练。
RLHF 训练使用了 16 GPUs。
RLHF 训练中 Reward Model 的评分如图所示。
在 MT-Bench 上使用 GPT-4 API 测评 SFT 和 RLHF 模型的效果,平均得分提升 11%。
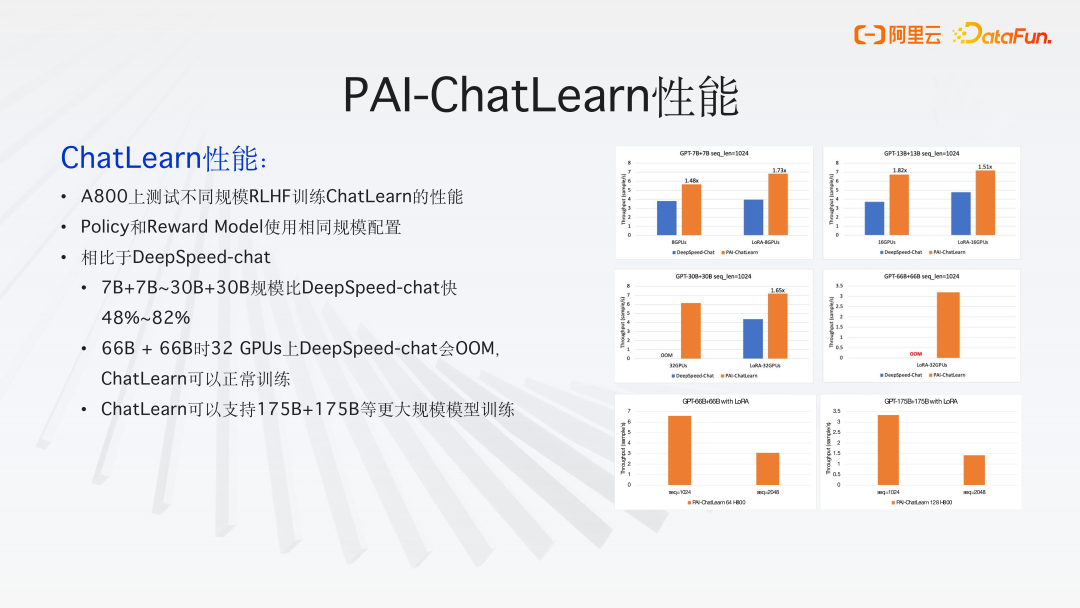
- ChatLearn 性能:
A800 上测试不同规模 RLHF 训练 ChatLearn 的性能。
Policy 和 Reward Model 使用相同规模配置。
相比于 DeepSpeed-chat,7B+7B~30B+30B 规模比 DeepSpeed-chat 快 48%~82%。
66B + 66B 时 32 GPUs 上 DeepSpeed-chat 会 OOM,ChatLearn 可以正常训练。
ChatLearn 可以支持 175B+175B 等更大规模模型训练。
3、PAI-ChatLearn 效果
- Qwen-14B 上的效果:
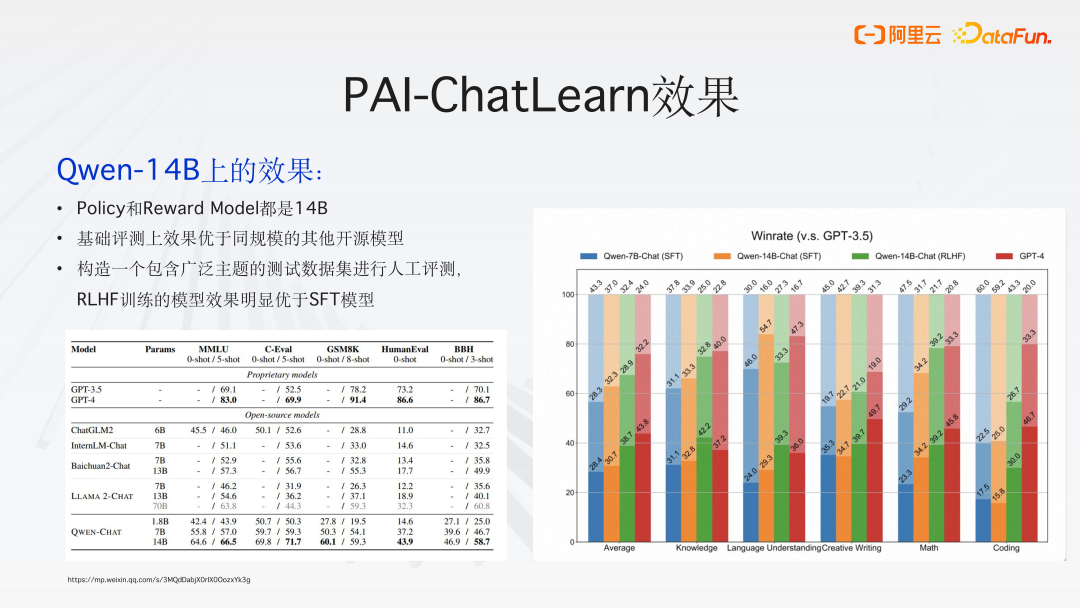
Policy 和 Reward Model 都是 14B;
基础评测上效果如上图所示,优于同规模的其他开源模型;
构造一个包含广泛主题的测试数据集进行人工评测,RLHF 训练的模型效果明显优于 SFT 模型。测试题包括知识类、语言理解类,创作类、数学类,编码类等能力。
四、问答环节
Q1:Reward 模型中有多种评分机制,如科学准确性、合规性以及人性化表达等,是否有多维度奖励模型评测的实际工程经验?
A1:百川 2 技术报告中提到模型中的 HF 训练,使用了不止一个奖励模型。如在数学领域,现有的奖励模型在数学评分方面可能不够精准,效果不理想,他们会专门采用一个单独的数学能力更强的模块来辅助奖励模型的训练。
一些开源框架,由于是平铺设计,会遇到显存不足等各种挑战,难以扩展。
而 PAI-ChatLearn 框架,其采用分离式架构设计,方便了在不同阶段进行各种扩展。只需在奖励模型部分添加一系列处理逻辑,即可实现多个奖励模型的结合。由于每个模型都被封装成一个独立的分布式 actor,所以只需添加一个新的分布式 actor,并将其结果串联起来,最后用KL散度或其他方法进行计算即可。
Q2:在使用 PAI 开发套件中,遇到从 Hugging Face 转 Megatron 模型进行 TP或 PP 切分后保存于磁盘会变大很多倍的问题,请问是什么原因,如何解决?
A2:对模型进行 TP 张量并行或者 PP 流水并行的切分是不会改变模型大小的。
老版本的 Megatron 上有个 bug,进行转换后会保存多份,最新版本已经没有这个问题了。
Q3:PAI_ChatLearn 中实现的 RLHF 训练流程图中有很多变量,是否可以任意进行配置?
A3:这个是一个标准的 PPO 实现,这些参数是必要的。
PAI-ChatLearn 会把这个 inference 和 training 分开,增加了参数同步,也即最上面的线的部分。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK