

QLoRa:在消费级GPU上微调大型语言模型
source link: https://www.51cto.com/article/756587.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
QLoRa:在消费级GPU上微调大型语言模型
大多数大型语言模型(LLM)都无法在消费者硬件上进行微调。例如,650亿个参数模型需要超过780 Gb的GPU内存。这相当于10个A100 80gb的gpu。就算我们使用云服务器,花费的开销也不是所有人都能够承担的。
大多数大型语言模型(LLM)都无法在消费者硬件上进行微调。例如,650亿个参数模型需要超过780 Gb的GPU内存。这相当于10个A100 80gb的gpu。就算我们使用云服务器,花费的开销也不是所有人都能够承担的。
而QLoRa (Dettmers et al., 2023),只需使用一个A100即可完成此操作。
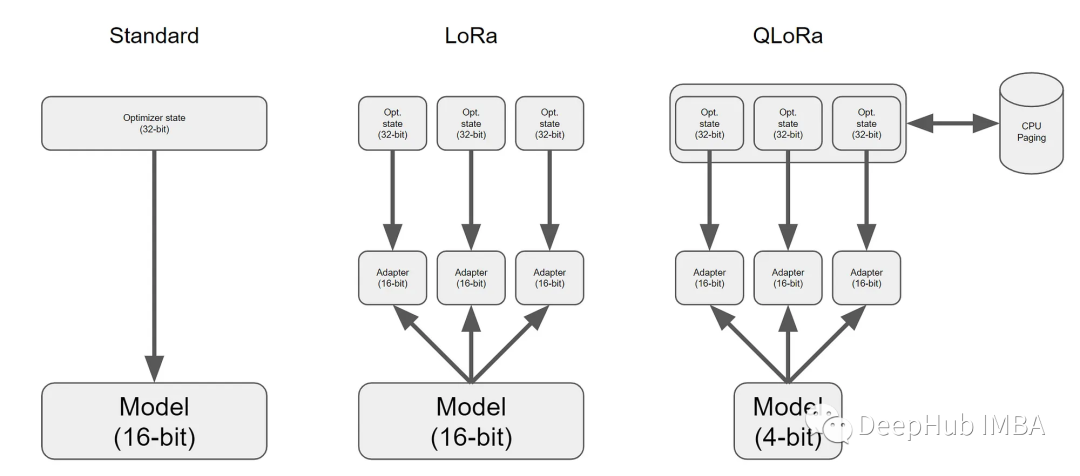
在这篇文章中将介绍QLoRa。包括描述它是如何工作的,以及如何使用它在GPU上微调具有200亿个参数的GPT模型。
为了进行演示,本文使用nVidia RTX 3060 12 GB来运行本文中的所有命令。这样可以保证小显存的要求,并且也保证可以使用免费的Google Colab实例来实现相同的结果。但是,如果你只有较小内存的GPU,则必须使用较小的LLM。
QLoRa: Quantized LLMs with Low-Rank Adapters
2021年6月,发布的LoRa让我们的微调变得简单,我也在以前的文章中也有过介绍。
LoRa为LLM的每一层添加了少量的可训练参数(适配器),并冻结了所有原始参数。这样对于微调,只需要更新适配器权重,这可以显著减少内存占用。
而QLoRa更进一步,引入了4位量化、双量化和利用nVidia统一内存进行分页。
简而言之,QLoRa工作原理如下:
- 4位NormalFloat量化:这是一种改进量化的方法。它确保每个量化仓中有相同数量的值。这避免了计算问题和异常值的错误。
- 双量化:QLoRa的作者将其定义如下“对量化常量再次量化以节省额外内存的过程。”
- 统一内存分页:它依赖于NVIDIA统一内存管理,自动处理CPU和GPU之间的页到页传输。它可以保证GPU处理无错,特别是在GPU可能耗尽内存的情况下。
所有这些步骤都大大减少了微调所需的内存,同时性能几乎与标准微调相当。
使用QLoRa对GPT模型进行微调
硬件要求:
下面的演示工作在具有12gb VRAM的GPU上,用于参数少于200亿个模型,例如GPT-J。
如果你有一个更大的卡,比如24gb的VRAM,则可以用一个200亿个参数的模型,例如GPT-NeoX-20b。
内存建议至少6 Gb,这个条件现在都能满足对吧。
GPT-J和GPT-NeoX-20b都是非常大的模型。所以硬盘议至少有100gb的可用空间。
如果你的机器不满足这些要求,可以使用Google Colab的免费实例,因为它就足够使用了。
软件要求:
必须要CUDA。这是肯定的。然后还需要一些依赖:
- bitsandbytes:包含量化LLM所需的所有库。
- Hugging Face的Transformers和Accelerate:这些是标准库,用于训练模型。
- PEFT:提供了各种微调方法的实现,我们只需要里面的LoRa。
- 数据集:自己的数据集,这里安装了Hugging Face的datasets,这个是备选,装不装无所谓,因为这玩意挺难用的
PIP安装命令如下:
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
pip install -q datasets下面就是Python代码
1、GPT模型的加载与量化
我们需要以下导入来加载和量化LLM。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig我们将对EleutherAI预训练的GPT NeoX模型进行微调。这是一个有200亿个参数的模型。注意:GPT NeoX具有允许商业使用的宽松许可证(Apache 2.0)。
可以从hug Face Hub获得这个模型和相关的标记器:
model_name = "EleutherAI/gpt-neox-20b"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)然后配置量化器,如下所示:
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)- load_in_4bit:模型将以4位精度加载到内存中。
- bnb_4bit_use_double_quant:QLoRa提出的双量化。
- bnb_4bit_quant_type:这是量化的类型。“nf4”代表4位的NormalFloat。
- bnb_4bit_compute_dtype:当以4位加载和存储模型时,在需要时对其进行部分量化,并以16位精度(bfloat16)进行所有计算。
然后就可以加载4位模型:
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=quant_config, device_map={"":0})下一步启用梯度检查点,这样可以减少内存占用,但是速度会稍微降低一些:
model.gradient_checkpointing_enable()2、LoRa的GPT模型预处理
为LoRa准备模型,为每一层添加可训练的适配器。
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)在LoraConfig中,可以使用r、alpha和dropout来获得更好的任务结果。具体内容可以在PEFT文档中找到更多选项和详细信息。
使用LoRa,我们只添加了800万个参数。并且只训练这些参数,这样使得微调很快。
3、数据集
对于这个演示,我们使用“english_quotes”数据集。这是一个由名言组成的数据集,在CC BY 4.0许可下发布。我们为了方便使用datasets直接加载。
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)微调的代码非常标准
import transformers
tokenizer.pad_token = tokenizer.eos_token
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
warmup_steps=2,
max_steps=20,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()要记住optim=”paged_adamw_8bit”。它将使用分页实现更好的内存管理。没有它可能会出现内存不足错误。
在Google Colab上运行这个微调只需要5分钟。VRAM消耗的峰值是15gb。
它有用吗?让我们试试推理。
基于QLoRa推理
微调的QLoRa模型可以直接与标准的Transformers的推理一起使用,如下所示:
text = "Ask not what your country"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))你应该得到这样的输出:
Ask not what your country can do for you, ask what you can do for your country.”
– John F.5分钟的微调效果还可以吧。
LoRa让我们的微调变得简单,而QLoRa可以让我们使用消费级的GPU对具有10亿个参数的模型进行微调,并且根据QLoRa论文,性能不会显著下降。
如果你对QLoRa感兴趣,看看他的代码吧:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK