

从0到1的ChatGPT - 进阶篇(五)- Embeddings
source link: https://lorexxar.cn/2023/05/25/chatgpt5/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在前面的文章中,无论是各种prompt技巧,又或者是对话技巧,更或者是各种数据集训练,都逃不开两个致命的问题。
1、ChatGPT只能处理文字
2、无论是上下文参考,还是单条对话都有token限制
所以在ChatGPT中,很多应用方向遇到的第一个问题就是如何把问题用文字的方式描述出来,其中最典型的场景就是代码分析。
所以ChatGPT也鼓励使用Embeddings来做类似搜索、分类或者异常检测的分析,这篇文章就讲讲这个。
Embeddings
Embeddings是拓扑学中的一个概念,这个词被普遍提出来是在深度学习领域。抛开复杂的理论不谈,简单来说就是通过数学的方式把一个内容给向量化,用一些非常复杂的向量来代替内容本身。这是一种试图通过数学理论解读问题的方案。
这里我拿一个特别简单的例子来解释一下Embeddings。这里这个例子参考了一个知乎的帖子。
假设我们需要招聘一个程序员,那么我们可以把招聘需求抽象成5个维度,比如会python,写过项目,名校学历,带过团队,性格特点,在5个维度的基础上,我们可以把候选人的能力抽象为数字。
比如说[1,1,0,0,1],当然用0和1是精度比较低的,你可以用0.几来替代每个向量中对预期的符合度。在这个5维的向量标准下,我们可以把多个候选人的简历抽象为多个5维向量组,并且通过对多个5维向量组做一定的数学计算,这样就可以得出最合适的候选人。
当然,这只是一个简单的例子。在深度学习的领域,Embeddings的计算还涉及到核函数的优化过程。对于使用者来说,我们不需要刨开黑盒讨论这些。
在ChatGPT中,openai提供了官方的计算Embeddings的API,当然这是收费的。
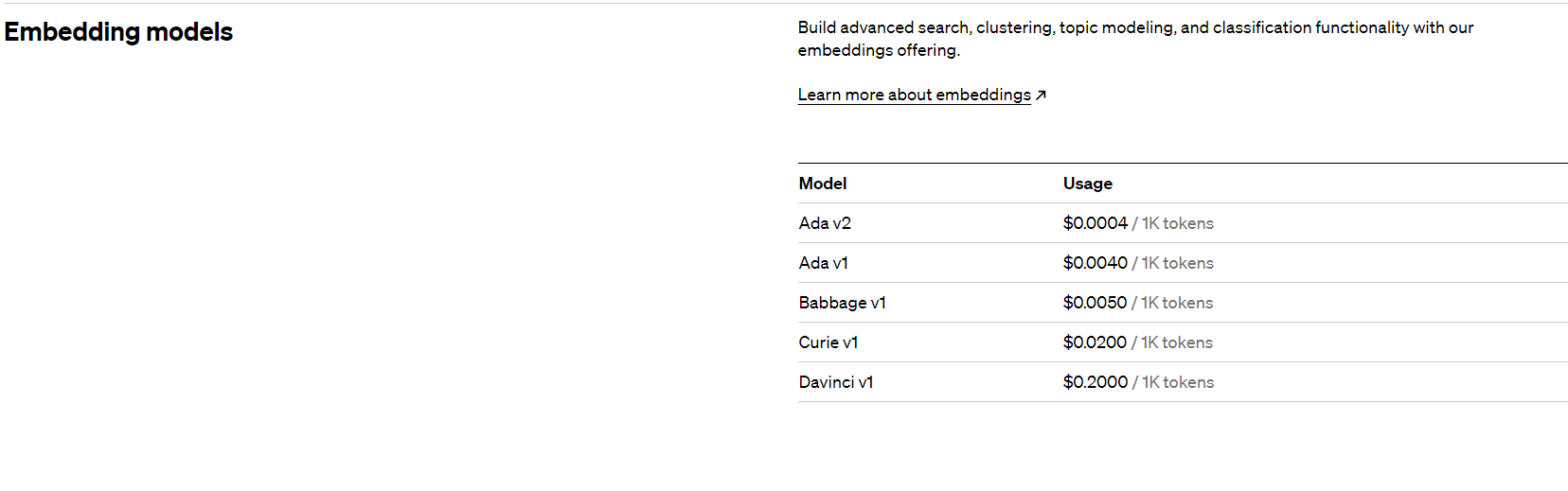
通过openai的api,我们就可以把信息转化为Embeddings向量。在Openai的文档中,我们可以看到每个模型的核方案对应的要求以及价格。

其中 text-embedding-ada-002这个模型整体表现最好而且还便宜,更适用于Embeddings。
这里我们还是拿上篇文章的例子来聊,拿我的博客内容来进一步处理。在上篇文章中我们准备数据集的时候就遇到了几个问题。
1、博客内容普遍超过2000token,并且更普遍的是,文章内容中有大量的代码,甚至图片内容
2、可能是由于博客内容分割严重,也可能是由于GPT3本身的学习能力有限,学习的结果很差。
这种情况下,我们就可以尝试用Embeddings把内容向量化,再做进一步的处理。
我们通过把文章本身向量化,然后再把问题向量化,在对比两部分的余弦相似度,最终返回相似度最高的文章。
当然,对比文章相似度这种信息颗粒度还是太低了,理论上来说,你可以选择把文章按照自然段划分并分别处理,当然如何关联多个自然段也是一个问题。
这里我用一个比较简单的例子,把文章按照#划分自然段,然后标上标题,并通过openai的api来计算embeddings.
import pandas as pd
import tiktoken
import codecs
import re
from openai.embeddings_utils import get_embedding
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base"
max_tokens = 8000
file = "chatgpt1.md"
f = codecs.open(file, 'r', encoding='utf-8', errors='ignore')
text = f.read()
m1 = re.search(r'title: (.+)\n', text)
title = m1.group(1)
matchs = re.findall(r'\#+[^\#]*', text) # 匹配标题和内容
for match in matchs:
m2 = re.search(r'\#+.*', match)
t2 = m2.group(0)
r = "Title: {} - {}\nContent:{}".format(title, t2, match)
# print(r)
em = get_embedding(r, engine=embedding_model)
print(em)
运行就可以查看到结果
然后我们在这个基础上对上述的向量化数据存档,然后一一对比相似度。
import pandas as pd
import tiktoken
import codecs
import re
from openai.embeddings_utils import get_embedding, cosine_similarity
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base"
max_tokens = 8000
textlist = []
search_text = "ip被封了怎么办?"
file = "chatgpt1.md"
f = codecs.open(file, 'r', encoding='utf-8', errors='ignore')
text = f.read()
m1 = re.search(r'title: (.+)\n', text)
title = m1.group(1)
matchs = re.findall(r'\#+[^\#]*', text) # 匹配标题和内容
for match in matchs:
m2 = re.search(r'\#+.*', match)
t2 = m2.group(0)
r = "Title: {} - {}\nContent:{}".format(title, t2, match)
# print(r)
em = get_embedding(r, engine=embedding_model)
search_embedding = get_embedding(
search_text,
engine="text-embedding-ada-002"
)
similarity = cosine_similarity(em, search_embedding)
c = {
"content": r,
"similarity": similarity
}
textlist.append(c)
sorted_list = sorted(textlist, key=lambda k: k['similarity'])
print(sorted_list[-1])
通过这段代码我们在文章中搜索和”ip被封了怎么办?”这个问题相似度最高的段落,最终我们得到答案。

关于Embeddings
其实说了这么多Embeddings的各种信息,仔细想想,Embeddings是一种把问题抽象化成数学问题的一种手段。其实近几年很多圈子都流行过用数学解决问题,就比如早几年区块链流行用形式化验证做代码分析,大数据流行用相似性验证来做搜索。
但他们大多都遇到了一个类似的问题,就是当你试图用数学抽象问题,会不可避免的让问题本身变得跑偏。如果说原本的程序设计是为了解决问题而不断优化。当你换数学方案来解决问题的后,问题就变成了,如何用数学更准确的描述问题。
Embeddings就是一个很典型的例子,这只是一个比较泛的概念,具体Embeddings的技术方案有很多,无论是基本的热独编码到 PCA 降维,从 Word2Vec 到 Item2Vec,从矩阵分解到基于深度学习的协同过滤。每种概念以及技术方案,都是为了更准确的找到描述问题的维度,更准确计算。
也正是因此,Embeddings虽然是大数据乃至AICG中非常关键的技术之一,但在ChatGPT这个场景中,Embeddings应用的主要作用就是节省tokens。但显然,Embeddings虽然被广泛应用于信息分类和聚合,但在代码分析的场景,Embeddings的表现并不好,在后面的文章中会讲到这些。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK