

再聊聊分布式数据库,你知道了吗?
source link: https://www.51cto.com/article/755776.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
再聊聊分布式数据库,你知道了吗?
昨天的文章发了以后有朋友就怀疑这文章是给集中式数据库厂商打call的,实际上我只是从一个相对客观的角度把我对分布式数据库的个人见解写出来了。同样对于这个话题,分布式数据库的拥趸也可以写出一篇比较客观的文章,观点看上去完全不同。是不是很奇妙,怎么会存在两种截然不同的事实呢?如果你了解过阳明心学,从表象和物本质的理论来看这件事,就能理解了。实际上我们讲述的都不是事实,不是物本质。事实只有一个,我们所看到的只是表象,描述的只是观点,而不是事实本身。我们的描述可以十分接近事实,但永远也无法变成事实。基于此,一些看似矛盾的“较为正确的观点”就会存在了。实际上我们都是在盲人摸象,为分布式数据库打CALL的朋友可能摸到的是大象的耳朵,而我摸到的是大象的尾巴。
昨天文章的最后我说了,企业选择什么样的数据库取决于其应用场景,需求等,不过可能起决定作用的因素是领导的喜好。我写昨天这篇文章的目的是让大家不要盲目的去追星分布式数据库,对于企业IT来说,其实是要考虑整体成本的,从建设到使用,从建设到扩容升级,从研发到运维,如果从整体上考虑,盲目的选择相对复杂的分布式数据库,是后患无穷的。
不过确实也有一些场景,集中式数据库的能力不足,可能只能借助分布式数据库了。最近我们在帮客户做一个技术验证测试,为他们的最大的一套交易型数据库系统选择合适的替代品。这套OLTP加批处理特征的系统的数据库接近70TB,更大量的明细的时序特征的数据已经剥离到HBASE了。选择候选数据库的时候我们选择了两款分布式数据库和一款集中式数据库。在测试前的沟通中,集中式数据库厂商主动放弃了,他们觉得这个场景是他们的弱项。
所以我要表达的观点并不是一味的否定分布式数据库,而是提醒企业,企业数据库选型时保留一定的多样性,可能对今后企业的IT系统发展更有利。去年和一个客户交流的时候,他们的数据库替代方案是大量的中小型系统替代选择一款Oracle数据库兼容性较好的集中式数据库进行一对一迁移,较为重要的系统采用数据复制HA高可用架构,一般的系统仅仅通过备份保证数据级安全性。企业中的几个大型的核心系统具有较好的分区特性,因此都采用了分布式数据库进行替代。他们采用这种方式后,集中式数据库的运维主要采取自主运维的模式,而分布式数据库采用了相对成本较高的数据库原厂驻场服务的模式。通过这种二元制的模式,有效的控制了今后运维的成本。
谈到分布式数据库,还是免不了要谈谈分布式数据库的选型问题,分布式数据库的市场也很乱,特别是在我国,连分布式数据库的定义都十分模糊。按照信通院相关白皮书的定义,分布式数据库分为三大类。
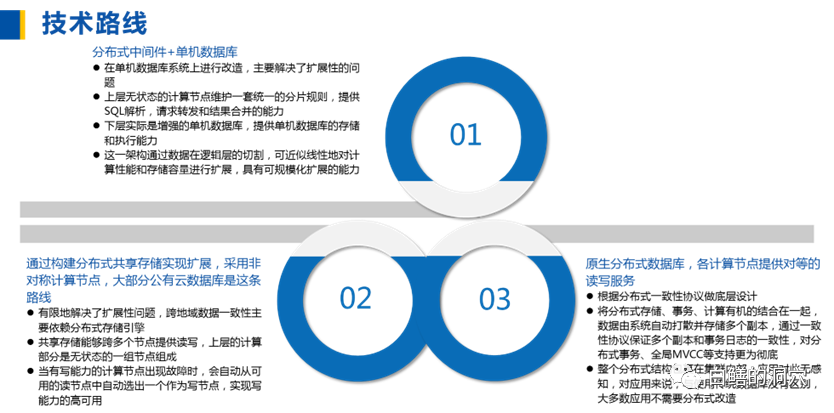
分布式中间件、原生分布式、共享存储读写分离都可以算分布式数据库。我习惯上还是把读写分离共享存储的模式看成是集中式数据库。剩下的两类分布式数据库的数量也是很庞大的。从墨天轮国产数据库热度排行榜往下数就有OceanBase、TiDB、GaussDB、TDSQL、GBase 8A、AnalyticDB、GoldenDB、AntDB等一大堆分布式关系型数据库了。
如果说集中式数据库天生就在扩展能力上有天花板,那么打破了这个天花板的分布式数据库其实也是有缺陷的。昨天这方面我已经谈了不少,今天就不再重复了。今天要谈的是这么多分布式数据库,到底我们该如何去选择呢?实际上数据库选型真的很难十分科学,一种比较科学的方法是为你的应用去选择数据库而不是为你的喜好去选择数据库。根据你的业务场景的特点去对这些数据库打分,最后选出能够满足你的业务系统中的一些比较有挑战性的场景的几个候选数据库,再根据你喜好去选择其中之一,相对会科学一些。
如果是要处理简单的物联网应用,那么大多数分布数据库都是能够胜任的,大并发写入,简单的查询是分布式数据库最擅长的场景。如果你的业务逻辑十分复杂,有很多比较复杂的查询,甚至还有一些较为复杂的大型批处理场景,那么数据库的SQL引擎的能力就十分重要了。分布式数据库是通过分布式执行的能力来弥补分布式在保证事务一致性上和分布式执行在网络延时上的开销的。如果算子不能有效的分解与下推,那么就像打群架一样,一堆流氓哪怕是群殴,战斗力也不强的。因此在做选择的时候,要十分注重SQL引擎的能力。最简单的方法是把各种以前在Oracle上也比较吃力的SQL拿出来,在这些数据库上跑一跑,看看效果如何。
对于研发能力很差,大量的SQL都是从老一辈程序员的代码里抠出来,自己也看不太懂,只能通过层层嵌套往上加业务的研发队伍开发的应用,那么就需要选择CBO优化器水平较高的数据库产品了。这种情况下,大部分SQL代理模式的分布式数据库产品就基本上不用考虑了。
数据库选型是个很复杂的事情,不过做起来也可以变得很简单。就像我本文中介绍的一个客户,大量的中小型的系统可以直接根据自己的喜好和商务上的考虑,选择一款和Oracle兼容性较好的集中式数据库进行替代了。如果应用能做一定的改造,直接上开源的集中式数据库就可以了。对于一些大型的核心系统,可以采用选型的方式,根据业务特点选择几个产品,使用自己的应用场景编制测试用例,做个及格测试。对于考核合格的产品,领导拍板就行了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK