

MySQL 如何执行一条 SQL
source link: https://yangxikun.com/mysql/2023/05/17/mysql-sql-execute.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
MySQL 如何执行一条 SQL
词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为记号(token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
MySQL 的词法分析器并没有直接使用开源的 flex ,而是自己手动实现了词法分析的函数:
int MYSQLlex(YYSTYPE *yylval, YYLTYPE *yylloc, THD *thd)
输入参数为
- yylval:存储解析到的 token 的一些信息:
- yylval->lex_str:记录解析到的 token 字符串
- yylval->charset:记录指定 token 的字符编码,Character Set Introducers
- yylval->optimizer_hints:记录解析到的查询优化器 hint
- yylval->symbol:如果 token 是 MySQL 关键字的话,会记录到这个字段
- yylloc:记录解析到的 token 在原始字符串和分析过程中用到的预处理缓冲中的位置
- thd:处理当前请求的线程
- m_parser_state:
- m_input:解析器参数
- m_lip:字符输入流
- m_yacc:语法解析器内部状态
- m_parser_state:
MYSQLlex(yylval, yylloc, thd) 调用 lex_one_token(yylval, thd) 从 thd->m_parser_state->m_lip 读取字符流解析为一个个 token 返回给语法分析器 yyparse。token 用一个整型值表示,在 sql_yacc.h 中通过 #define 定义:
词法分析器的核心实现逻辑都在 lex_one_token,通过有限状态机实现分词。
/* Tokens. */
#define ABORT_SYM 258
#define ACCESSIBLE_SYM 259
#define ACCOUNT_SYM 260
......
#define ZEROFILL 907
#define JSON_OBJECTAGG 908
#define JSON_ARRAYAGG 909
以 select uid from table1 为例,会被解析为 token 序列:SELECT_SYM IDENT_QUOTED FROM IDENT_QUOTED END_OF_INPUT。
语法分析(英语:syntactic analysis,也叫 parsing)是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。
词法分析器和语法分析器工作流程大致如下:
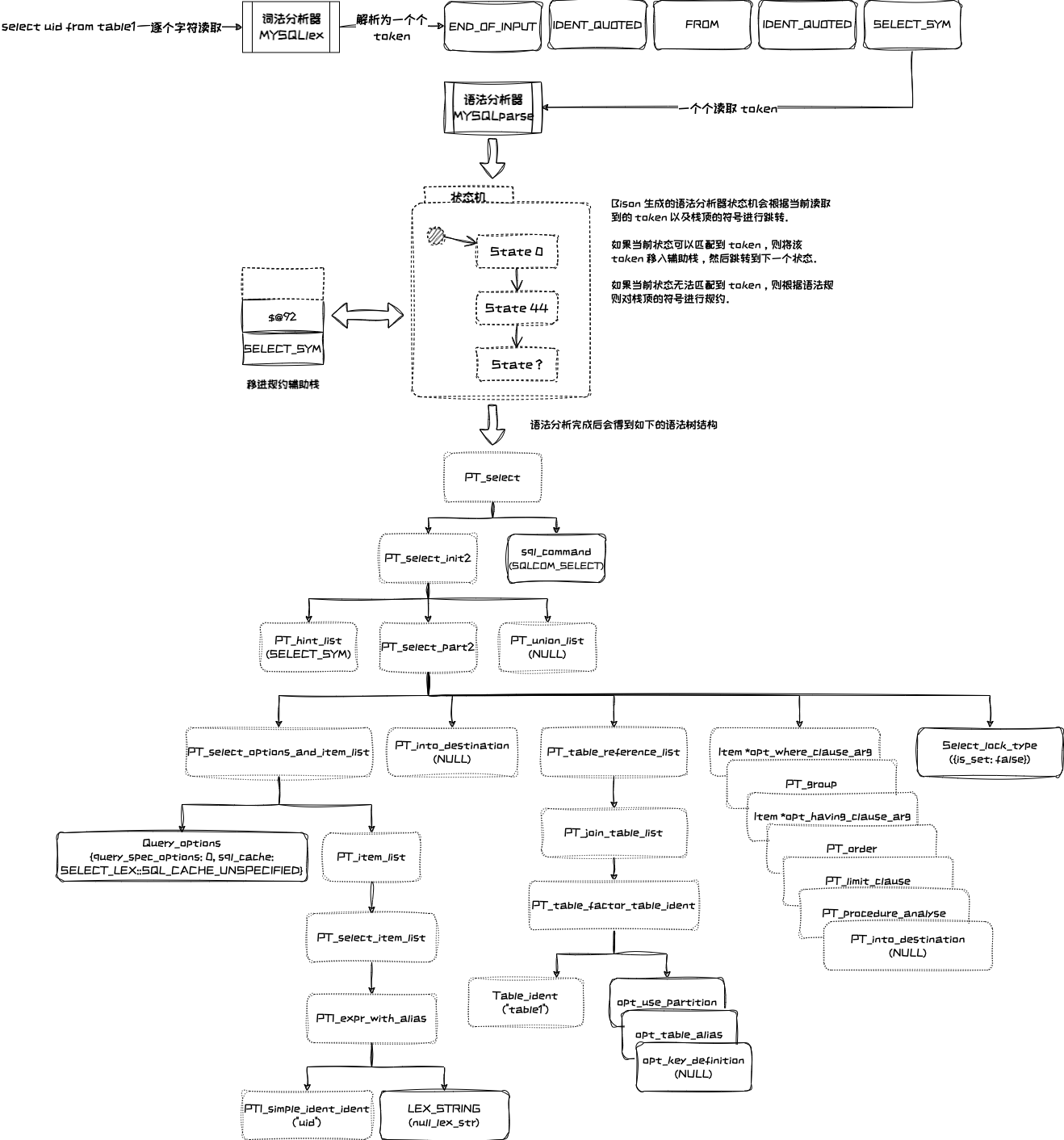
MySQL 使用的是 bison 生成的语法分析器,会调用 MYSQLlex 逐个获取 token 进行语法分析。
MySQL 的 SQL 语法定义在 sql_yacc.yy 中,该文件的主要内容为:
%{
/* 这一部分是 C 代码:#define、#include、函数的声明和定义,会被复制到 bison 生成的 C 文件中 */
}%
%yacc
%parse-param { class THD *YYTHD } /* yyparse 额外的参数 */
%lex-param { class THD *YYTHD } /* yylex 额外的参数 */
%pure-parser /* 生成可重入的语法解析函数 */
%expect 155 /* 告诉 bison 存在 155 个移进/规约冲突 */
/* 终结符定义,对应词法分析的 token */
%token ABORT_SYM /* INTERNAL (used in lex) */
%token ACCESSIBLE_SYM
%token ACCOUNT_SYM
...
%token ZEROFILL
%token JSON_OBJECTAGG /* SQL-2015-R */
%token JSON_ARRAYAGG /* SQL-2015-R */
/* 操作符结合性定义 */
%right UNIQUE_SYM KEY_SYM
...
%left INTERVAL_SYM
/* 终结符和非终结符的类型定义,比如下面这个定义会把右侧符号的值存储到 YYSTYPE.lex_str */
%type <lex_str>
IDENT IDENT_QUOTED TEXT_STRING DECIMAL_NUM FLOAT_NUM NUM LONG_NUM HEX_NUM
LEX_HOSTNAME ULONGLONG_NUM field_ident select_alias ident ident_or_text
IDENT_sys TEXT_STRING_sys TEXT_STRING_literal
NCHAR_STRING opt_component key_cache_name
sp_opt_label BIN_NUM label_ident TEXT_STRING_filesystem ident_or_empty
opt_constraint constraint opt_ident TEXT_STRING_sys_nonewline
filter_wild_db_table_string
......
%type <alter_instance_action> alter_instance_action
/* 语法规则定义 */
/* 冒号左边是非终结符,它可以表示为冒号右边的终结符、非终结符、以及动作组成的语法 */
/* 第一条规则 query 是语法起始符号,整个 SQL 输入必须被它匹配 */
%%
query: /* 语法分析的起点 */
END_OF_INPUT /* END_OF_INPUT 是终结符,词法分析返回的第一个 token 是 END_OF_INPUT,说明是空查询 */
{ /* 匹配到空查询时,执行的动作(代码) */
THD *thd= YYTHD;
if (!thd->bootstrap &&
!thd->m_parser_state->has_comment())
{
my_message(ER_EMPTY_QUERY, ER(ER_EMPTY_QUERY), MYF(0));
MYSQL_YYABORT;
}
thd->lex->sql_command= SQLCOM_EMPTY_QUERY;
YYLIP->found_semicolon= NULL;
}
| verb_clause /* verb_clause 是非终结符,需要根据其规定义进行深度优先搜索匹配 */
{
......
通过 MySQL 启动参数 --debug=d,parser_debug 可以让语法分析器将语法分析过程中的调试日志打印出来,如下是 select uid from table1 语法解析的调试日志:
- Reading a token: select,这里的 select 是笔者加了日志打印出来的
- bison 会根据 sql_yacc.yy 定义的规则,生成语法分析器的状态机代码,我们可以通过
bison --name-prefix=MYSQL --yacc --warnings=all,no-yacc,no-empty-rule,no-precedence,no-deprecated --defines=sql_yacc.h -v sql_yacc.yy获取状态机的文本描述文件 y.output- 日志中的
Entering state 44,44 为状态编号,可在 y.output 中根据正则^State 44\b搜索到,状态描述的第一部分是规则,第二部分是状态流转的条件,以及需要执行的动作Reducing stack by rule XXX (line YYY)将栈顶的部分符号进行规约,XXX 规则的编号,在 y.output 开头的语法下面定义,YYY 对应的 sql_yacc.yy 中所在行定义的动作nterm XXX完成某一非终结符 XXX 的规约
帮我把如下的文本中的双斜线的内容对齐下:
Starting parse
Entering state 0 // 进入语法分析的状态机 0
Reading a token: select
Next token is token SELECT_SYM (: ) // select 被词法分析转换为 token:SELECT_SYM
Shifting token SELECT_SYM (: ) // 根据 sql_yacc.yy 的语法规则定义,DFS 匹配到 query->verb_clause->statement->select->select_init->SELECT_SYM select_part2 opt_union_clause
// 将 SELECT_SYM 压栈
Entering state 44 // 进入语法分析的状态机 44,即尝试规约到 select_init
Reducing stack by rule 1225 (line 9135): // 继续 DFS 匹配到 select_init->select_part2->select_options_and_item_list->%empty
// select_options_and_item_list 的规则定义首先是匹配空,然后执行一个空动作
-> $$ = nterm $@92 (: ) // 匹配到空字符串,$@92: %empty,把 %empty 压栈
Stack now 0 44
Entering state 620 // 进入语法分析的状态机 620,即尝试规约到 select_options_and_item_list
Reading a token: uid // 读取下一个 token
Next token is token IDENT_QUOTED (: ) // uid 被词法分析转换为 token:IDENT_QUOTED
Reducing stack by rule 1233 (line 9185): // 继续 DFS 匹配到 select_init->select_part2->select_options_and_item_list->select_options->%empty
// select_options 的第一个规则是空匹配
-> $$ = nterm select_options (: ) // 完成 select_options 的匹配,把 select_options 压栈
Stack now 0 44 620
Entering state 952 // 进入语法分析的状态机 952,继续尝试规约到 select_options_and_item_list
Next token is token IDENT_QUOTED (: ) // 当前 token 还是 uid
Shifting token IDENT_QUOTED (: ) // 继续 DFS 匹配到 select_init->select_part2->select_options_and_item_list->select_item_list->select_item->expr->bool_pri->predicate->bit_expr->simple_expr->simple_ident->ident->IDENT_sys->IDENT_QUOTED
// IDENT_QUOTED 压栈
// uid 已经被匹配到了,将 IDENT_QUOTED 压栈
Entering state 274 // 进入语法分析的状态机 274,继续尝试规约到 IDENT_sys
Reducing stack by rule 2020 (line 13154): // 执行 IDENT_sys: IDENT_QUOTED {...} 的动作
$1 = token IDENT_QUOTED (: ) // $1 用于引用 uid 这个 IDENT_QUOTED token 的值
-> $$ = nterm IDENT_sys (: ) // 完成 IDENT_sys 的匹配,栈顶的 IDENT_QUOTED 规约为 IDENT_sys
Stack now 0 44 620 952
Entering state 873 // 进入语法分析的状态机 873,继续尝试规约到 ident
Reading a token: from // 读取下一个 token
Next token is token FROM (: ) // from 被词法分析转换为 token:FROM
Reducing stack by rule 2026 (line 13259): // 执行 ident: IDENT_sys {...} 的动作
$1 = nterm IDENT_sys (: ) // $1 用于引用上面匹配完成的 IDENT_sys 的值
-> $$ = nterm ident (: ) // 完成 ident 的匹配,栈顶的 IDENT_sys 规约为 ident
Stack now 0 44 620 952
Entering state 874 // 进入语法分析的状态机 874,继续尝试规约到 simple_ident
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 2002 (line 13034): // 执行 simple_ident: ident {...} 的动作
$1 = nterm ident (: )
-> $$ = nterm simple_ident (: ) // 完成 simple_ident 的匹配,栈顶的 ident 规约为 simple_ident
Stack now 0 44 620 952
Entering state 871 // 进入语法分析的状态机 871,继续尝试规约到 simple_expr
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 1317 (line 9535): // 执行 simple_expr: simple_ident 默认动作 $$ = $1
$1 = nterm simple_ident (: )
-> $$ = nterm simple_expr (: ) // 完成 simple_expr 匹配,栈顶的 simple_ident 规约为 simple_expr
Stack now 0 44 620 952
Entering state 857 // 进入语法分析的状态机 857,继续尝试规约到 bit_expr
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 1299 (line 9496): // 执行 bit_expr: simple_expr {...} 默认动作 $$ = $1
$1 = nterm simple_expr (: )
-> $$ = nterm bit_expr (: ) // 完成 bit_expr 匹配,栈顶的 simple_expr 规约为 bit_expr
Stack now 0 44 620 952
Entering state 855
Next token is token FROM (: )
Reducing stack by rule 1284 (line 9436):
$1 = nterm bit_expr (: )
-> $$ = nterm predicate (: ) // 完成 predicate 匹配,栈顶的 bit_expr 规约为 predicate
Stack now 0 44 620 952
Entering state 854
Reducing stack by rule 1270 (line 9365):
$1 = nterm predicate (: )
-> $$ = nterm bool_pri (: ) // 完成 bool_pri 匹配,栈顶的 predicate 规约为 bool_pri
Stack now 0 44 620 952
Entering state 853
Next token is token FROM (: )
Reducing stack by rule 1265 (line 9336):
$1 = nterm bool_pri (: )
-> $$ = nterm expr (: ) // 完成 expr 匹配,栈顶的 bool_pri 规约为 expr
Stack now 0 44 620 952
Entering state 852 // 进入语法分析的状态机 852,继续尝试规约到 select_item
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 1248 (line 9277): // 执行 select_alias: /* empty */ { $$=null_lex_str;} 动作
-> $$ = nterm select_alias (: ) // 完成 select_alias 匹配,压栈 select_alias
Stack now 0 44 620 952 852
Entering state 1289
Reducing stack by rule 1247 (line 9269): // 完成 select_item 匹配,栈顶的 expr select_alias 规约为 select_item
$1 = nterm expr (: )
$2 = nterm select_alias (: )
-> $$ = nterm select_item (: )
Stack now 0 44 620 952
Entering state 851 // 进入语法分析的状态机 851,继续尝试规约到 select_item_list
Reducing stack by rule 1244 (line 9252): // 执行 select_item_list: select_item {...} 动作
$1 = nterm select_item (: )
-> $$ = nterm select_item_list (: ) // 完成 select_item_list 的匹配,栈顶的 select_item 规约为 select_item_list
Stack now 0 44 620 952
Entering state 1481 // 进入语法分析的状态机 1481,继续尝试规约到 select_options_and_item_list
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 1226 (line 9135): // 执行 select_options_and_item_list: select_options select_item_list {...} 动作
$1 = nterm $@92 (: )
$2 = nterm select_options (: )
$3 = nterm select_item_list (: )
-> $$ = nterm select_options_and_item_list (: ) // 完成 select_options_and_item_list 的匹配,栈顶的 $@92 select_options select_item_list 规约为 select_options_and_item_list
Stack now 0 44
Entering state 619 // 进入语法分析的状态机 619,继续尝试规约到 select_part2
Next token is token FROM (: ) // 当前 token 还是 FROM
Reducing stack by rule 1663 (line 11134): // 执行 opt_into: /* empty */ { $$= NULL; } 的动作
-> $$ = nterm opt_into (: ) // 完成 opt_into 匹配,压栈 opt_into
Stack now 0 44 619
Entering state 940 // 进入语法分析的状态机 940,继续尝试规约到 select_part2,搜索 from_clause
Next token is token FROM (: ) // 当前 token 还是 FROM
Shifting token FROM (: ) // 匹配到 FROM,将 FROM 压栈
Entering state 1476 // 进入语法分析的状态机 1476,继续尝试规约到 from_clause
Reading a token: table1 // 读取下一个 token
Next token is token IDENT_QUOTED (: ) // table1 被词法分析转换为 token:IDENT_QUOTED
Shifting token IDENT_QUOTED (: ) // 继续 DFS 匹配到 select_part2->from_clause->table_reference_list->join_table_list->derived_table_list->esc_table_ref->table_ref->table_factor->table_ident->ident->IDENT_sys->IDENT_QUOTED
Entering state 274
Reducing stack by rule 2020 (line 13154):
$1 = token IDENT_QUOTED (: )
-> $$ = nterm IDENT_sys (: ) // 完成 IDENT_sys 的匹配,栈顶的 IDENT_QUOTED 规约为 IDENT_sys
Stack now 0 44 619 940 1476
Entering state 524
Reducing stack by rule 2026 (line 13259):
$1 = nterm IDENT_sys (: )
-> $$ = nterm ident (: ) // 完成 ident 的匹配,栈顶的 IDENT_sys 规约为 ident
Stack now 0 44 619 940 1476
Entering state 683 // 进入语法分析的状态机 683,继续尝试规约到 table_ident
Reading a token: // 读取下一个 token,table_ident 有多个规则具有相同的第一个字符,所以需要往前看一个字符来确定匹配哪一条规则
Next token is token END_OF_INPUT (: ) // 当前 token 是输入结束的记号
Reducing stack by rule 2013 (line 13102): // 执行 table_ident: ident {...} 动作
$1 = nterm ident (: )
-> $$ = nterm table_ident (: ) // 完成 table_ident 的匹配,栈顶的 ident 规约为 table_ident
Stack now 0 44 619 940 1476
Entering state 1590 // 进入语法分析的状态机 1590,继续尝试规约到 table_factor
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1525 (line 10548):
-> $$ = nterm opt_use_partition (: ) // 完成 opt_use_partition 的匹配,压栈 opt_use_partition
Stack now 0 44 619 940 1476 1590
Entering state 2214
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1587 (line 10811):
-> $$ = nterm opt_table_alias (: ) // 完成 opt_table_alias 的匹配,压栈 opt_table_alias
Stack now 0 44 619 940 1476 1590 2214
Entering state 2795
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1548 (line 10698):
-> $$ = nterm opt_index_hints_list (: ) // 完成 opt_index_hints_list 的匹配,压栈 opt_index_hints_list
Stack now 0 44 619 940 1476 1590 2214 2795
Entering state 3267
Reducing stack by rule 1550 (line 10703):
$1 = nterm opt_index_hints_list (: )
-> $$ = nterm opt_key_definition (: ) // 完成 opt_key_definition 的匹配,压栈 opt_key_definition
Stack now 0 44 619 940 1476 1590 2214 2795
Entering state 3268
Reducing stack by rule 1528 (line 10568):
$1 = nterm table_ident (: )
$2 = nterm opt_use_partition (: )
$3 = nterm opt_table_alias (: )
$4 = nterm opt_key_definition (: )
-> $$ = nterm table_factor (: ) // 完成 table_factor 的匹配,栈顶的 table_ident opt_use_partition opt_table_alias opt_key_definition 规约为 table_factor
Stack now 0 44 619 940 1476
Entering state 1589
Reducing stack by rule 1503 (line 10421):
$1 = nterm table_factor (: )
-> $$ = nterm table_ref (: ) // 完成 table_ref 的匹配,栈顶的 table_factor 规约为 table_ref
Stack now 0 44 619 940 1476
Entering state 1584
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1506 (line 10443):
$1 = nterm table_ref (: )
-> $$ = nterm esc_table_ref (: ) // 完成 esc_table_ref 的匹配,栈顶的 table_ref 规约为 esc_table_ref
Stack now 0 44 619 940 1476
Entering state 1586
Reducing stack by rule 1508 (line 10450):
$1 = nterm esc_table_ref (: )
-> $$ = nterm derived_table_list (: ) // 完成 derived_table_list 的匹配,栈顶的 esc_table_ref 规约为 derived_table_list
Stack now 0 44 619 940 1476
Entering state 1587
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1505 (line 10429):
$1 = nterm derived_table_list (: )
-> $$ = nterm join_table_list (: ) // 完成 join_table_list 的匹配,栈顶的 derived_table_list 规约为 join_table_list
Stack now 0 44 619 940 1476
Entering state 2127
Reducing stack by rule 1231 (line 9172):
$1 = nterm join_table_list (: )
-> $$ = nterm table_reference_list (: ) // 完成 table_reference_list 的匹配,栈顶的 join_table_list 规约为 table_reference_list
Stack now 0 44 619 940 1476
Entering state 2126
Reducing stack by rule 1228 (line 9163):
$1 = token FROM (: )
$2 = nterm table_reference_list (: )
-> $$ = nterm from_clause (: ) // 完成 from_clause 的匹配,栈顶的 FROM table_reference_list 规约为 from_clause
Stack now 0 44 619 940
Entering state 1477 // 进入语法分析的状态机 1477,继续尝试规约 select_part2 剩余的部分
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1591 (line 10826):
-> $$ = nterm opt_where_clause (: )
Stack now 0 44 619 940 1477
Entering state 2129
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1597 (line 10851):
-> $$ = nterm opt_group_clause (: )
Stack now 0 44 619 940 1477 2129
Entering state 2746
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1593 (line 10834):
-> $$ = nterm opt_having_clause (: )
Stack now 0 44 619 940 1477 2129 2746
Entering state 3233
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1608 (line 10927):
-> $$ = nterm opt_order_clause (: )
Stack now 0 44 619 940 1477 2129 2746 3233
Entering state 3636
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1617 (line 10964):
-> $$ = nterm opt_limit_clause (: )
Stack now 0 44 619 940 1477 2129 2746 3233 3636
Entering state 3906
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1653 (line 11067):
-> $$ = nterm opt_procedure_analyse_clause (: )
Stack now 0 44 619 940 1477 2129 2746 3233 3636 3906
Entering state 4086
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1663 (line 11134):
-> $$ = nterm opt_into (: )
Stack now 0 44 619 940 1477 2129 2746 3233 3636 3906 4086
Entering state 4180
Next token is token END_OF_INPUT (: )
Reducing stack by rule 1240 (line 9230):
-> $$ = nterm opt_select_lock_type (: )
Stack now 0 44 619 940 1477 2129 2746 3233 3636 3906 4086 4180
Entering state 4302
Reducing stack by rule 1224 (line 9105):
$1 = nterm select_options_and_item_list (: )
$2 = nterm opt_into (: )
$3 = nterm from_clause (: )
$4 = nterm opt_where_clause (: )
$5 = nterm opt_group_clause (: )
$6 = nterm opt_having_clause (: )
$7 = nterm opt_order_clause (: )
$8 = nterm opt_limit_clause (: )
$9 = nterm opt_procedure_analyse_clause (: )
$10 = nterm opt_into (: )
$11 = nterm opt_select_lock_type (: )
-> $$ = nterm select_part2 (: ) // 完成 select_part2 的匹配
Stack now 0 44
Entering state 618 // 进入语法分析的状态机 618,继续尝试规约 select_init 剩余的部分 opt_union_clause
Next token is token END_OF_INPUT (: )
Reducing stack by rule 2619 (line 14778):
-> $$ = nterm opt_union_clause (: ) // 完成 opt_union_clause 的匹配,压站 opt_union_clause
Stack now 0 44 618
Entering state 934
Reducing stack by rule 1216 (line 9059):
$1 = token SELECT_SYM (: )
$2 = nterm select_part2 (: )
$3 = nterm opt_union_clause (: )
-> $$ = nterm select_init (: ) // 完成 select_init 的匹配,栈顶的 SELECT_SYM select_part2 opt_union_clause 规约为 select_init
Stack now 0
Entering state 90
Reducing stack by rule 1215 (line 9051):
$1 = nterm select_init (: )
-> $$ = nterm select (: ) // 完成 select 的匹配,栈顶的 select_init 规约为 select
Stack now 0
Entering state 89
Reducing stack by rule 51 (line 1706):
$1 = nterm select (: )
-> $$ = nterm statement (: ) // 完成 statement 的匹配,栈顶的 select 规约为 statement
Stack now 0
Entering state 60
Reducing stack by rule 7 (line 1658):
$1 = nterm statement (: )
-> $$ = nterm verb_clause (: ) // 完成 verb_clause 的匹配,栈顶的 statement 规约为 verb_clause
Stack now 0
Entering state 59 // 进入语法分析的状态机 59,继续尝试规约 query 剩余的部分
Next token is token END_OF_INPUT (: ) // 匹配到 END_OF_INPUT
Shifting token END_OF_INPUT (: ) // 将 END_OF_INPUT 压栈
Entering state 662
Reducing stack by rule 4 (line 1645):
$1 = nterm verb_clause (: )
$2 = token END_OF_INPUT (: )
-> $$ = nterm query (: ) // 完成 query 的匹配,栈顶的 verb_clause END_OF_INPUT 规约为 query
Stack now 0
Entering state 58
Reading a token: Now at end of input. // 读取下一个 token
Shifting token $end (: ) // 词法分析器返回了结束的记号,将 $end 压栈
Entering state 661 // 进入语法分析的状态机 661,规约到了 $accept,说明当前输入的 SQL 语法解析完成,没有错误
Stack now 0 58 661
Cleanup: popping token $end (: ) // 出栈 $end
Cleanup: popping nterm query (: ) // 出栈 query,整个 SQL 解析后的 token 都规约到了 query
当语法分析器规约到 statement: select { CONTEXTUALIZE($1); } 时,执行动作 CONTEXTUALIZE((yyvsp[0].select));,将 CONTEXTUALIZE 宏展开为:
Parse_context pc(YYTHD, Select);
if (YYTHD->is_error() || (yyvsp[0].select)->contextualize(&pc))
MYSQL_YYABORT;
即从语法解析树根节点开始 PT_select::contextualize(Parse_context *pc),调用各个语法树节点的 contextualize 方法,每个节点会把自己从 SQL 语法解析中获得的信息更新到 THD->lex->current_select(),即 LEX 类的私有字段 SELECT_LEX *m_current_select;,SELECT_LEX 是 st_select_lex 类的别名,该类承载了 SQL 执行所需要的信息(查询的字段、条件、表连接等),每个语法树节点大致会更新如下字段信息:
PT_select:
pc->thd->lex->sql_command= sql_command // 设置查询命令 SQLCOM_SELECT
PT_select_init2:
PT_select_part2:
PT_select_options_and_item_list:
Query_options:
pc->select->sql_cache= ? // 查询缓存策略:SELECT_LEX::SQL_CACHE_UNSPECIFIED, SELECT_LEX::SQL_NO_CACHE, SELECT_LEX::SQL_CACHE
pc->select->set_base_options(options) // 查询选项:HIGH_PRIORITY|STRAIGHT_JOIN|SQL_SMALL_RESULT|...
st_select_lex->m_base_options = options
st_select_lex->m_active_options = options
PT_select_item_list:
pc->select->item_list= value // 设置查询字段,例如 "uid"
PT_table_reference_list:
PT_join_table_list:
PT_table_ref_join_table:
PT_join_table_on:
PT_join_table: // 设置连接方式,右连接转换为左连接
PTI_comp_op::itemize // 创建 on 条件的 Item_bool_func
设置内表的 on 条件
st_select_lex::nest_last_join
pc->select->context.table_list = pc->select->context.first_name_resolution_table = pc->select->table_list.first // 设置查询涉及到的表
PTI_context<CTX_WHERE>
PTI_comp_op::itemize // 创建 where 条件的 Item_bool_func
PT_group:
PT_order_list:
PT_order_expr:
Item->itemize
pc->select->group_list= group_list->value // 设置 group 字段
pc->select->olap= ? // UNSPECIFIED_OLAP_TYPE, CUBE_TYPE, ROLLUP_TYPE
PTI_context<CTX_HAVING>
PTI_comp_op::itemize // 创建 having 条件的 Item_bool_func
pc->select->set_where_cond(opt_where_clause) // 设置 st_select_lex->m_where_cond
pc->select->set_having_cond(opt_having_clause) // 设置 st_select_lex->m_having_cond
PT_order:
PT_order_list:
PT_order_expr:
Item->itemize // 字段解析
pc->select->order_list= order_list->value // 设置排序字段
PT_limit_clause:
Limit_options: // 字段解析
opt_offset->itemize
limit->itemize
// 设置 offset 和 limit
pc->select->select_limit= limit_options.limit
pc->select->offset_limit= limit_options.opt_offset
pc->select->explicit_limit= true
pc->select->set_lock_for_tables(opt_select_lock_type.lock_type) // FOR UPDATE | LOCK IN SHARE MODE
PT_hint_list:
pc->select->opt_hints_qb // 设置优化器 hints https://dev.mysql.com/doc/refman/5.7/en/optimizer-hints.html
PT_union_list:
// 另外一个查询进行 contextualize
优化器和执行
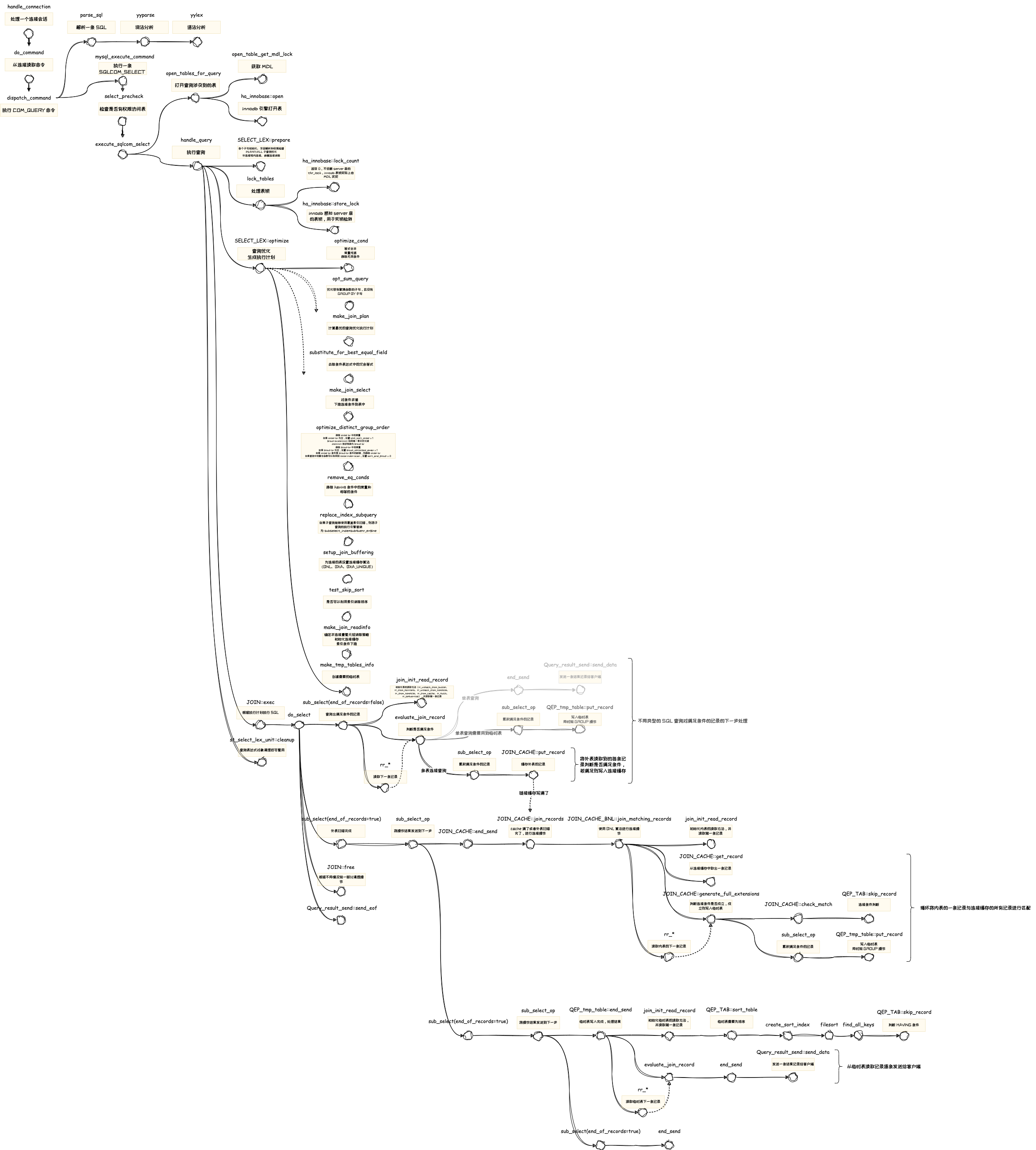
语法解析完成后,由查询优化器对 SQL 进行优化后,生成执行计划,每张表会生成 QEP_TAB(即这张表对应的执行计划),然后开始执行查询。想要深入了解优化器的实现原理,可以阅读《数据库查询优化器的艺术》李海翔 著。
下图是一条 SQL 被优化器优化和执行时会涉及到的一些关键函数节点:
执行流程的函数节点是跟踪这样的 SQL 得到的: select a.uid, count(b.oid) as total from table1 as a left join table2 as b on a.uid=b.uid where a.name=’mike’ group by a.uid having count(b.oid)<2 order by total desc;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK