

全网最详细解读《GIN-HOW POWERFUL ARE GRAPH NEURAL NETWORKS》!!! - emo98
source link: https://www.cnblogs.com/akaman98/p/17355702.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Abstract + Introduction
GNNs 大都遵循一个递归邻居聚合的方法,经过 k 次迭代聚合,一个节点所表征的特征向量能够捕捉到距离其 k-hop 邻域的邻居节点的特征,然后还可以通过 pooling 获取到整个图的表征(比如将所有节点的表征向量相加后用于表示一个图表征向量)。
关于邻居聚合策略以及池化策略都有很多相关的研究,并且这些 GNNs 已经达到了目前最先进的性能,然而对于 GNNs 的各种性质以及性能上限我们并没有一个理论性的认识,也没有对 GNN 表征能力的形式化分析。言下之意:这些 GNNs 模型的研究虽然效果很好,但并没有系统理论的支撑,并不知道是基于什么导致了更好的性能,而是基于经验主义的。
本文提出了一个理论框架以分析 GNNs 表征的能力,正式描述了不同 GNNs 变体在学习表征以及区分不同图结构时的性能。该理论框架由 GNN 与 WL-test 之间的密切联系所启发。与 GNN 类似,WL-test 也会递归地聚合节点的邻居特征。也是因为 WL-test 聚合更新的性质使其性能强大。既然二者在操作上都非常相似,那么从理论上看 GNN 也能够具备跟 WL-test 一样强大的判别能力。
为了在数学上形式化上述见解,理论框架首先会将给定节点的邻居节点特征向量表示为一个 multiset,即一个可能包含重复元素的集合。GNNs 的邻居聚合就能够被看作是对 multiset 进行处理的聚合函数。
作者研究了 multiset 聚合函数的多种变体,并从理论上分析了聚合函数对于区分不同 multiset 的判别能力。为了具备强大的表征能力,GNN 必须将不同的 multiset 聚合成不同的表示。只要聚合函数能够达到跟 hash 散列一样的单射性,那么理论上是能够达到跟 WL-test 一样的判别能力的。因此,聚合函数的单射性越强,GNN 的表征能力就越强。
该篇论文的研究成果总结如下:
- 展示了 GNNs 在区分图结构时,理论上能够达到与 WL-test 相似的性能。
- 在上述条件下,建立了邻居聚合以及 Graph readout 的 condition。
- 识别了当下流行的 GNN 变体(GCN,GraphSAGE)无法区分的图结构,并精确表征了其能够成功捕捉的图结构类型。
- 开发了一个简单的神经网络架构 GIN,并且证明了它在表征能力上与 WL-test 性能相当。
作者通过图数据集的分类任务验证了理论,其中 GNN 的表征能力对于捕获图结构的信息至关重要。研究比较了基于不同聚合函数 GNNs,结果证明性能最强大的 GIN 模型从经验的角度来看也具备高表征能力,几乎能够完美拟合训练数据,而一些较弱的 GNN 变体则通常欠拟合训练数据。此外,表征能力更强的 GNNs 在测试集精度上比其他模型性能更优,主要表现在图分类任务上达到了目前最优的性能。
PRELIMINARIES
我们用 G=(V,E)G=(V,E) 表示一个图,节点特征向量表示为 XvXv。我们主要考虑两个任务:
- 节点分类任务:每个节点 v∈Vv∈V 都有一个关联的标签 yvyv 并且我们的目标是去学习每个节点 vv 的表征向量 hvhv,每个节点 vv 的标签预测过程能够被表示为 yv=f(hv)yv=f(hv)
- 图分类任务:给定图集合 {G1,G2,...,Gn}∈G{G1,G2,...,Gn}∈G 并且其标签集合为 {y1,y2,...,yn}∈Y{y1,y2,...,yn}∈Y,目标是学习每个图的表征向量 hGhG 以预测图的标签,整个过程可以被表示为 yG=g(hG)yG=g(hG)
Graph Neural Networks. GNNs 利用图的结构和节点特征 XvXv 去学习一个节点表征向量 hvhv(或是整个图的表征向量 hGhG)。当前 GNNs 都采用了邻居聚合策略,通过聚合策略迭代更新每个节点的表征向量。经过 k 次聚合迭代后,一个节点的表征能够捕捉 k-hop 邻居节点的特征信息。形式上,第 k 层 GNN 可表示为:
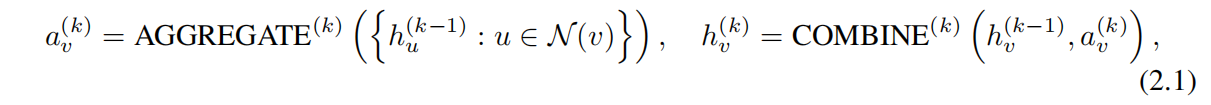
其中 hv(k)hv(k) 表示节点 vv 在第 k 次迭代的特征向量。我们初始化 h(0)=Xvh(0)=Xv,并且 N(v)N(v) 是节点 V 的邻居节点集合。
公式表达的意思即:先聚合节点 vv 的邻居节点表征,得到 av(k)av(k),然后结合 av(k)av(k) 与节点自身的表征 hv(k−1)hv(k−1) 生成节点 vv 新的表征 hv(k)hv(k)。
对于 Aggregate 以及 combine 的选择对于 GNN 的性能有着至关重要的影响,并且也有很多相关的研究,比如 GraphSAGE 的 Aggregate 则表示为如下:
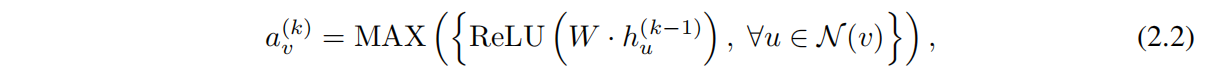
其中 WW 是可学习的参数矩阵,MaxMax 表示为 element-wise max-pooling。Combine 则表示为一个线性映射 W⋅[hv(k−1),av(k)]W·[hv(k−1),av(k)]。
即:GraphSAGE 会将所有的邻居节点进行一个线性投影,然后通过 ReLU 激活,再取出其中的最大值作为邻居聚合后的表征向量。这个邻居节点 multiset 的表征向量会跟节点自身的表征向量拼在一起作线性投影。
而在 GCN 中 则是采用了 element-wise mean-poolinig,并且 Aggregate 和 Combine 过程结合到了一起:
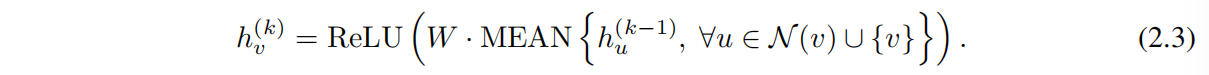
即:GCN 会先对邻居节点以及节点自身取平均,然后对结果线性投影,然后通过 ReLU 激活,结果作为最终的节点表征向量。
而许多其他的 GNNs 聚合/Combine 过程都能够被公式 2.1 表示。
对于节点分类任务,最后一次迭代的节点的表征 hv(K)hv(K) 则会被用于预测。对于图分类任务,READOUTREADOUT 函数则会聚合最后一次迭代的节点特征得到一个图表征向量 hGhG:
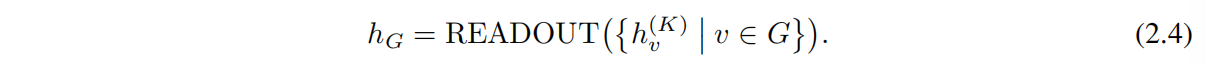
READOUT 可以是简单的排列不变函数,比如对所有图节点特征求和,也可以是更加复杂的图级别池化函数。
Weisfeiler-Lehman test. 图同构问题是指 判别两个图是否具备拓扑相同性。而 WL-test 则是针对图同构问题的一个高效的算法,它的判别操作过程类似于 GNN 中的邻居聚合,wL-test 迭代地聚合节点与邻居节点的标签,将聚合的标签进行一次 hash 散列为一个新的唯一标签。如果在某次迭代中,两个图之间的节点标签不同,则可以判定两个图是非同构的。
下图是图同构问题的一个简单判别流程,从上至下的 3 个图中,2 和 3 为同构图,1 则是与二者为异构图。相同的颜色表示相同的节点特征,邻居聚合散列后会生成一个新的特征。若经过若干次迭代后,若对应节点的颜色不同,则能够断言二者互为异构图。
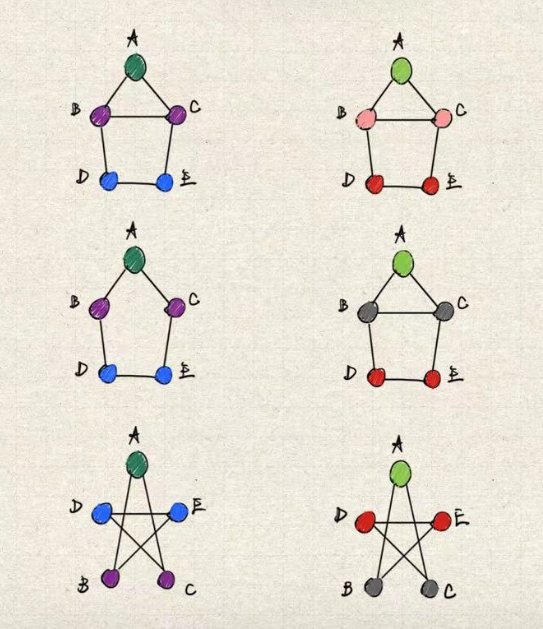
WL-test 只能够判别两个图不是同构图,但并不能判定两个图一定是同构图。
而 Shervashidze et al. 又基于 WL-test 提出了 WL subtree kernel 算法,该算法能够评估两个图的相似性。
作者并没有详细解释 WL subtree kernel 的具体计算过程,这里我们也不必过于纠结具体的算法,只需要知道 WL WL subtree kernel 能够高效地判定两个图结构的相似性。
如果我们能够在图分类任务中,精确而高效地判定出两个图的相似性,那么在预测任务中,就更容易确定两个图是否属于一个类别。而 GNN 的聚合操作与 WL-test 高度相似,因此我们可以合理怀疑:GNN 能够在图相似性评估的过程(图表征学习)中达到 WL-test 的性能水平。只要聚合函数能起到跟 hash 函数一样的单射性,那么理论上二者是能够达到同级别的性能水平的。
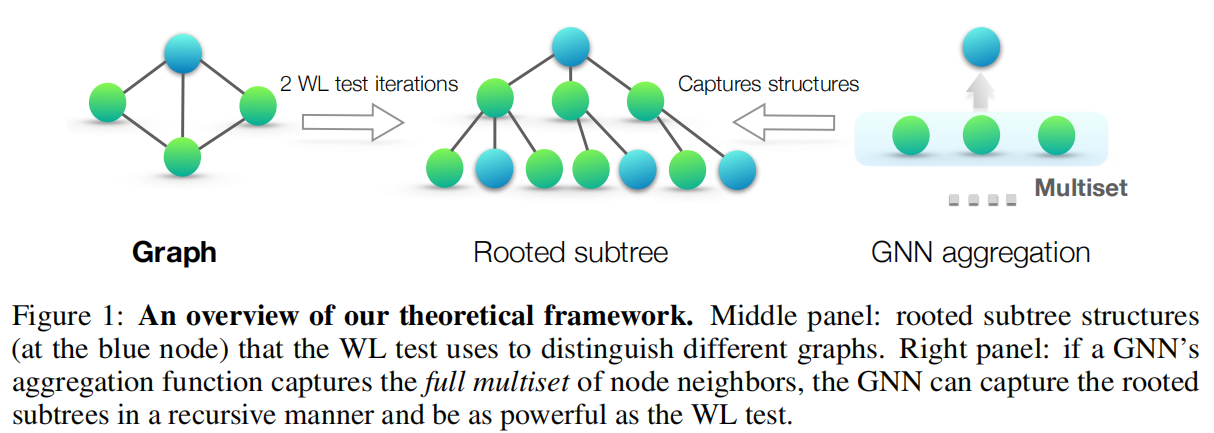
Figure 1. 简单表述了经过 2 次 WL-test 迭代后,每个节点聚合的邻居信息。这个过程是跟 GNN agreegation 高度相似的。
3 THEORETICAL FRAMEWORK: OVERVIEW
整个论文中,作者假设节点的特征向量是离散的(毕竟特征向量值连续的情况下,99.9999% 都不会聚合出一个相同的嵌入,作者也就没牛逼可吹了)。作者将这样的图称为有限图。对于有限图,更深卷积层的特征向量也同样是离散的。

作者这里给出了 Multiset 的定义,但我们不用太关注这个概念,直接将其理解为节点的邻居即可。
为了研究 GNN 的表征能力,作者分析了 GNN 什么情况下会将两个节点映射到嵌入空间中的相同位置。直观地说,一个最强大的 GNN 只有在两个节点具备相同的邻居子树结构时才会将它们映射到同一个嵌入空间的位置。我们也可以将问题简化为:GNN是否映射两个相同的邻域特征(multiset)映射到相同的嵌入表示。毕竟最强大的 GNN 永远不会将两个不同的邻域特征映射到同一个嵌入,即聚合函数必须是单射 injective 的。因此,我们将 GNN 的聚合函数抽象为一种可以由 neural network 表示的 multiset function,并分析该函数是否能够表示为 injective multiset function。
只要 multiset function 能表示为单射函数,这就意味着在 GNN 的聚合邻居操作中,对于不同邻域的特征,聚合后能够获取到一个唯一的输出表征,这样就能够捕捉到更多的图结构信息以及邻居节点的特征信息。GNN 就能够获得非常强大的表征能力。
injective function,即单射函数,表示输入跟输出是一对一的关系,即对于不同的输入x,f(x) 永远不可能存在相同的输出。
接下来,我们将利用这个推论(injective multiset function)来开发一个最强大的 GNN。在 Section.5 我们研究了当下流行的 GNN variants 并且发现它们的聚合方式都本质上不满足 injective 的特性,因此其模型的表征能力都不太强,但这些模型也可以捕获到 Graph 的其他的有趣的属性。
4 BUILDING POWERFUL GRAPH NEURAL NETWORKS
首先我们给出了 GNN 模型的最大表征能力,即具备单射性的聚合策略。理想情况下,最强大的 GNN 可以通过将不同的图结构映射到不同的嵌入空间来区分它们。然而,这种将任意两个不同的 Graph 映射到不同的嵌入空间的能力意味着要解决一个困难的图同构问题。即:我们希望同构图映射到相同的嵌入空间,非同构图映射到不同的嵌入空间。但在我们的分析中,我们利用一个稍微弱一些的标准来定义 GNN 的表征能力 —— WL-test,它通常能够很好地区分非同构图,并且性能也较高,除了少数例外情况(比如正则图)。

引理2:只要图神经网络能够将任意两个异构图划分到两个不同的嵌入,那么 WL-test 也一定可以将这两个图判定为异构图。简单来说,图神经网络能做的,WL-test 一定能做;但图神经网络不能做的,WL-test 也能做。
因此,任何基于聚合的 GNN 在区分不同的图方面最多也就跟 WL-test 一样强大。那么是否存在与 WL-test 一样强大的 GNN 呢?
Theorem 3. 给出了肯定的答案:若邻居聚合函数与 Readout function 都是 injective function,那么这样的 GNN 与 WL-test 一样强大。

定理3:若对于任意两个非同构图 G1G1 and G2G2(由 WL-test 判定),那么只要 GNN 具备足够多层且满足下面两个条件,就能够将两图映射到不同的嵌入:
-
GNN 通过式子 hv(k)=φ(hv(k−1),f({hu(k−1):u∈N(v)}))hv(k)=φ(hv(k−1),f({hu(k−1):u∈N(v)})) 聚合并且递归更新节点特征
其中,函数 f(x)f(x) 的入参为 multisets,φ(x)φ(x) 表示一个 combination 操作,且满足 injective。
-
GNN 的 graph-level readout 入参也是 multisets(即节点特征 {hv(k)}{hv(k)}),并且 readout 满足 injective。
作者已经在附录中给出了定理3的证明。对于有限图,单射性能够很好地描述一个函数是否能够维持输入信息的独特性。但对于无限图,由于其中的节点特征是连续的,则需要进一步考虑。
此外,描述学习到的特征在函数图像中的亲密度也是一件非常有趣的事情。我们将把这些问题留到未来的工作,并且将重心放到输入节点特征来自可数集合的情况。

引理4:主要是告诉我们,只要特征空间是离散的,那么在聚合后依然能够得到一个离散的特征空间。本篇论文也是在特征离散的前提下讨论的。
除了区分不同的图以外,GNN 还有一个重要的优点,即能够捕获图结构的相似性。而 WL-test 是无法捕获图之间的相似性的,这也是为什么我们不直接采用 WL-test 到图数据任务处理中。
原因在于:WL-test 中节点的特征向量本质上是 one-hot encodings,即描述节点属于哪个类别的 one-hot 编码,且经过邻居聚合 hash 后得到的也只是 “代表新的节点类别的 one-hot”,无法得到一个具备节点特征与图结构信息的空间嵌入,因此不能捕获子树之间的相似性。
相比之下,满足 Theorem 3 的 GNN 通过学习将邻居节点特征聚合映射到一个向量空间,相隔较远距离的嵌入大概率不属于一个类别,而相隔较近的嵌入则同属一个类别。这使得 GNN 不仅可以区分不同的图结构,还可以将近似的图结构映射到相似的嵌入,并捕获图结构之间的依赖关系。捕获节点的结构相似性被证明是有助于泛化的,特别是当邻居的特征向量的是稀疏的,或者存在噪声边缘特征时。
4.1 GRAPH ISOMORPHISM NETWORK (GIN)
在确立了最强大的 GNN 的开发条件后(满足单射的聚合函数),我们接下来开发一个简单的架构,图同构网络 GIN,它能够被证明满足 Theorem 3. 中的条件。这个模型推广了 WL-test 从而实现了 GNNs 系模型的最强判别能力。
为了建模一个单射邻居聚合函数,作者提出了一种 “deep multisets” 理论,即:用神经网络参数化 “通用的单射邻居聚合函数”。下一个 Lemma 说明了 sum-aggregators 能够在邻居聚合函数上具备单射的性质。
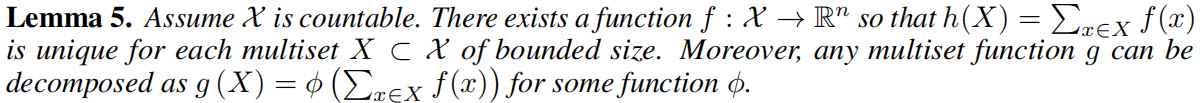
引理5:假设向量空间 XX 是离散的,那么一定存在函数 ff 将节点特征进行投影到一个 n 维嵌入的函数,使得 h(X)=∑x∈Xf(x)h(X)=∑x∈Xf(x) 的值对于每一个位于向量空间 XX 的 multiset XX 都能取到一个唯一的值。此外,任何一个 multiset function gg 都能被拆解为 g(X)=φ(∑x∈Xf(x))g(X)=φ(∑x∈Xf(x)),其中 φφ 是某个函数。
引理5,主要就是证明了 sum-aggregation 的单射性,我们明白这一点即可。
作者在论文附录中证明了 Lemma 5. 这里我们先不去管证明了。
Deep MultiSets 和 sets 最重要的一个区别是:是否满足单射的性质。比如 mean-aggregator 就不满足单射性质。(后面会解释 mean-aggregation 为什么不满足单射性)
“Deep MultiSets 和 sets 最重要的一个区别是:是否满足单射的性质。” 这句话我并不是看的很懂,个人的理解是:聚合函数的参数的丰富程度能够决定能否满足单射的性质,比如平均聚合的多集特征中,真正处理的只是整个特征集合中的一部分特征。
以 Lemma 5. 中的 “通用的单射邻居聚合函数” 建模机制作为构建模块,我们可以构想出一个聚合方案,该方案能够表示一个 “入参为节点以及其邻居 multiset” 的泛函数,因此满足 Theorem 3. 中的 injective condition。下一个推论给出了一个简单而具体的公式。
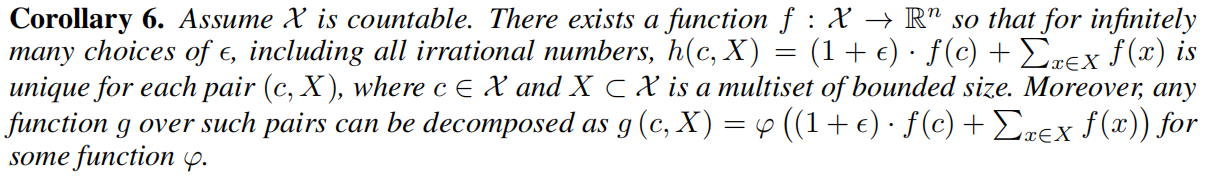
推论6:对于参数 ϵϵ,由无限种可能使得 h(c,X)=(1+ϵ)∗f(c)+∑x∈Xf(x)h(c,X)=(1+ϵ)∗f(c)+∑x∈Xf(x) 对于每一个元组 (c, X) 都能够拿得唯一的值。
其实跟引理5 差不太多,只需要把 c 理解为节点自身,X 理解为节点邻居多集即可。
鉴于普遍近似理论 universal approximation theorem (Hornik et al., 1989; Hornik, 1991),我们可以利用 MLPs 建模并学习 Corollary 6. 中的 ff and ϕϕ 函数。实际操作上,我们用单层感知机对 f(k+1)◦ϕ(k)f(k+1)◦ϕ(k) 进行建模,因为 MLPs 能够表示函数的组合。
在第一次迭代聚合时,若输入的特征是 one-hot encodings,那么我们在进行 sum 聚合之前并不需要 MLPs,因为这些特征的求和操作已经满足单射性质。我们可以让 ϵϵ 作为一个可学习参数或是固定参数。那么此时 GIN 的聚合操作可以由如下公式表示:
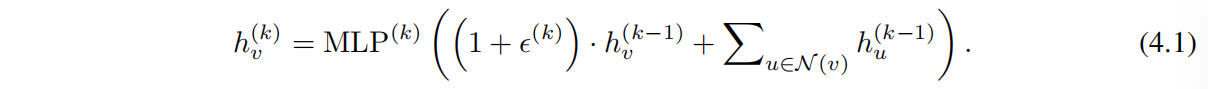
一般来说,可能存在许多其他强大的 GNNs。但 GIN 是最强大的 GNNs 之一,同时也很简单。
4.2 GRAPH-LEVEL READOUT OF GIN
通过 GIN 学习的节点嵌入可以直接用于节点分类问题以及链路预测问题,但对于图分类问题,我们提出了以下方法:通过节点的嵌入构造整个图的嵌入。一般我们会把这个过程称为 Graph Readout。
Graph Readout 的一个重要因素是:随着迭代(聚合)次数增加,对应于子树结构的节点表征会变得更加精细以及覆盖范围更广。因此足够的迭代次数是获得良好判别能力的关键。然而,有时较少迭代的特征也可能会带来更好的泛化能力,所以并不是一味的增加聚合次数就能够让性能变得更好。
因此,作者利用到了每一次迭代聚合的节点表征信息,通过类似 Jumping Knowledge Networks (Xu et al., 2018) 的架构来实现,并用下列 Readout concat 方案替换 Eq 2.4:
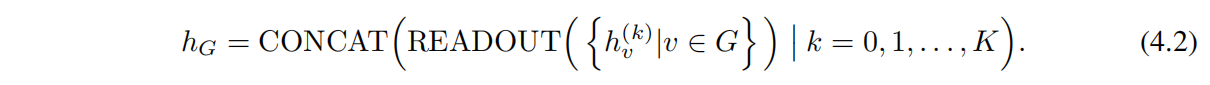
即,把每一次迭代聚合得到的表征进行一个 concat。
基于 Theorem 3. 和 Corollary 6. GNN 能够很好地推广 WL-test 和 WL subtree kernel(在求和之前,我们不需要额外的 MLP,原因跟 Eq 4.1 的相同,此时的 sum 已经满足了单射性质)
5 LESS POWERFUL BUT STILL INTERESTING GNNS
接下来,我们研究一下不满足 Theorem 3 (单射)条件的 GNNs,包括 GCN,GraphSAGE。再从两个方面开展关于聚合函数 Eq4.1 的消融实验
- 用 1-layer 的感知机而不采用 MLPs(单纯邻域节点线性求和作为聚合策略是否可行)
- 均值池化或最大池化,而不采用 sum(不采用求和而是采用 mean or max 的聚合策略是否可行)
我们将会惊讶地发现,这些 GNN 变体会无法识别一些简单的图,并且性能也不如 wL-test 强大。但尽管如此,采用 mean aggregators 的模型(如 GCN)在节点分类任务中还是会得到不错的结果。为了更便于理解,我们将精确地描述不同 GNN 变体能或不能捕捉到的图,并且讨论有关 “图学习” 的含义。
5.1 1-LAYER PERCEPTRONS ARE NOT SUFFICIENT
Lemma 5 中的函数 ff 能够将截然不同的 multisets 映射到一个唯一的 Embeddings 上。基于普遍近似理论,函数 ff 能够被 MLP 参数化。尽管如此,许多现有的 GNNs 都采用的是单层的感知机,然后通过 Relu 进行非线性激活。这样的单层映射属于广义线性模型的例子。因此我们感兴趣的是:单层感知机是否能够用于图学习。但 Lemma 7 表明,确实存在单层感知机永远无法区分的 multisets。
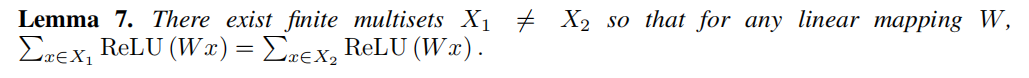
引理7:确实存在不同的多集 X1≠X2X1≠X2,但对于任何映射 WW 二者映射后的嵌入都是相等的。单层感知机可以是某种线性映射,此时 GNN 层会退化为简单的邻域特征求和。但引理7是建立在线性映射中缺乏偏置项 bias 的基础上的。
虽然有了偏置项和足够大的输出维度,单层感知机大概率能够区分不同的 multisets,但尽管如此,与采用多层感知机的模型不同,单层感知机即便是带有偏置项,也不属于 multisets function 的通用逼近函数。因此,即便 1-layer GNN 能够将不同的图嵌入到不同的表征,但这种嵌入可能无法充分捕获两个图的相似性,并且对于简单分类器(比如线性分类器)来说很难拟合。在 Section 7 中我们将会看到,1-layer GNN 在应用图分类任务时,会导致严重的欠拟合,并且在 test Accuracy 方面也通常比 MLPs GNN 表现差。
5.2 STRUCTURES THAT CONFUSE MEAN AND MAX-POOLING
如果我们在聚合操作中,将 h(X)=∑x∈Xf(x)h(X)=∑x∈Xf(x) 替换为 GCN 中的 mean pooling 或者 GraphSAGE 中的 max pooling 可能会发生什么?
平均池化聚合以及最大池化聚合都仍然属于 well-defined 的多集函数,因为它们都是排列不变的。但它们都不满足单射性。图2根据聚合器的表征能力对三种聚合器进行了排名,并且图3阐述了 max-pooling 和 mean-pooling 无法区分的结构。节点颜色表明了不同的节点特征,并且我们假设 GNNs 会在 combine 操作之前先执行 Aggregation。
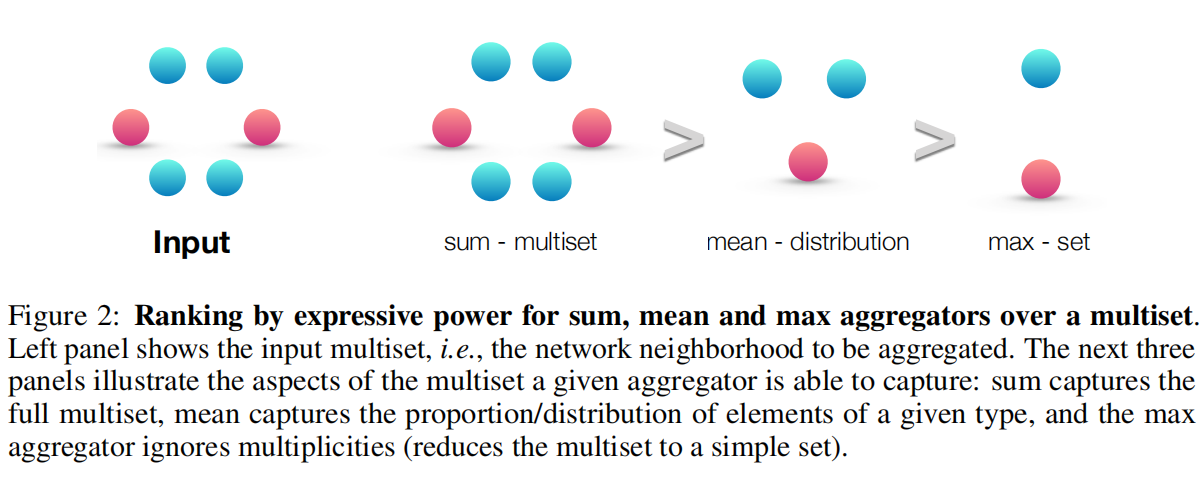
对于 sum 聚合来说,能够捕捉 multiset 中所有特征的信息,而 mean 聚合能捕捉部分比例特征的信息,而 max 聚合则忽略了特征信息的多样性。
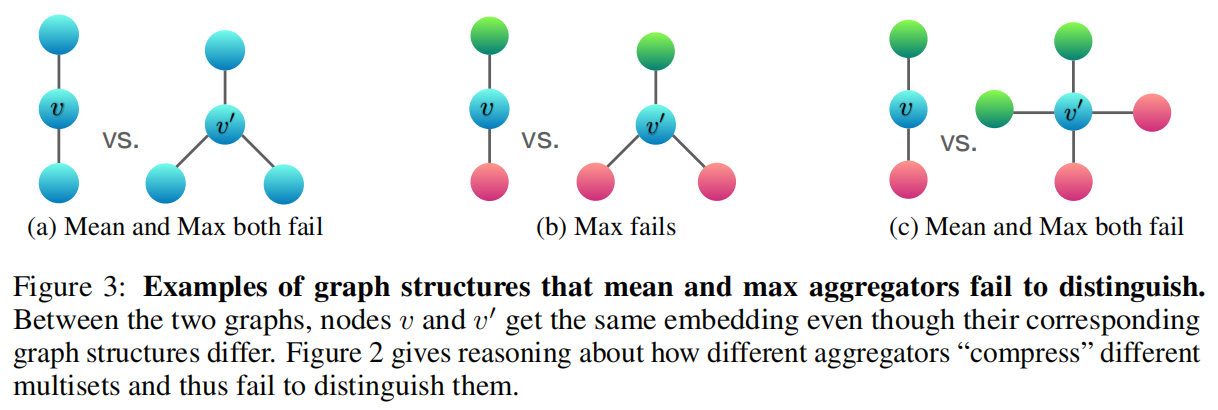
在 Figure 3a 中,所有的节点都具备相同的特征,因此对于 mean 和 max 聚合都会得到相同的结果,不具备单射性。即便两个图从结构上来看并不相同,但 mean and max 聚合却能够取到相同的值,也就意味着在这种情况下,mean and max 聚合无法捕获到任何图结构的信息。但对于 sum pooling aggregators 能够给出不同的值,也就意味着 sum aggregator 能够区分这两种图结构(但单纯的线性求和可能无法获取到图结构信息)。同样的参数也可以应用于任何无标记的图。如果使用节点度而不是常量值作为节点输入特征,原则上,mean 聚合可以起到类似 sum 聚合的作用,但最大池化不能。
Fig.3a 表明,平均和最大池化对于区分具备重复特征的节点是困难的。我们定义 hcolorhcolor 为节点特征的映射结果(相同特征会映射到相同的颜色)。Fig.3b 表明,对于两个不同结构的图,最大池化聚合 max(hg,hr)max(hg,hr) and max(hg,hr,hr)max(hg,hr,hr) 能够取到相同的表征。因此最大池化聚合并不能区分这两张图。但 sum aggregator 仍然能够区分。同样地,对于 Fig.3c,mean and max pooling 同样会无法区分,因为 12(hg+hr)=14(hg+hg+hr+hr)12(hg+hr)=14(hg+hg+hr+hr)
5.3 MEAN LEARNS DISTRIBUTIONS
为了描述 mean aggregator 能够区分的 multisets 类别,我们考虑一个例子:X1=(S,m)X1=(S,m) and X2=(S,k⋅m)X2=(S,k·m),其中 X1X1 and X2X2 拥有相同元素但个数不同(但成比例)的集合,任何平均聚合器都将 X1X1 和 X2X2 映射到相同的嵌入,因为它只是对 XiXi 的特征取平均值。
若在 graph 任务中,若 提取统计信息以及信息分布 比 提取特定结构信息 更加重要,那么 mean aggregator 的效果还不错。此外,若节点特征多样且重复性较少时,mean aggregator 跟 sum aggregator 的效果一样好。或许这能够被解释为什么平均存在一定的局限性,但平均聚合 GNNs 对节点分类的任务依然很有效,比如文章主题分类,社群检测这类任务,它们都属于节点特征丰富,且邻域特征分布为分类任务提供了更明显的信息。
5.4 MAX-POOLING LEARNS SETS WITH DISTINCT ELEMENTS
Fig.3 的例子表明:最大池化会将多个具备相同特征的节点视为单个节点(即,将 multiset 看作为单个 set)。最大池化捕捉特征的并非确切的图结构信息,也不是图节点的分布信息。最大池化适用于识别 “代表性骨架”,Qi et al. 的工作从经验上表明,最大池化聚合学习适合识别 3D 点云的 “骨架”,并且对噪声和异常值具有更强的鲁棒性。为了完整性起见,下一个推论表明,最大池化聚合器捕获了 multiset 的底层集合。
可以将 3D 点云理解为三维图像,一般会应用于建筑安全隐患识别,城市管理等。

推论9:可以简单理解为,max 聚合能够捕捉到结构相似的底层结构信息。其实跟最大池化的特性比较相似,具备更好的鲁棒性以及抗噪性,但缺点是会丢失一些信息。但即便如此,依然能够捕获到底层结构相同的类别。
5.5 REMARKS ON OTHER AGGREGATORS
还有一些其他的非标准邻居聚合方式,但本篇论文并未提及,比如:weighted average via attention (Velickovic et al., 2018),LSTM pooling (Hamilton et al., 2017a; Murphy et al., 2018). 本文强调的是:该理论框架足够普适去描述基于聚合方式的 GNNs 的表征性能。未来会考虑应用框架去分析和理解其他的聚合方式。
6 OTHER RELATED WORK
尽管 GNNs 取得了成功(从经验主义的角度来看),但用数学方法研究其性质的工作相对较少。一个例外是Scarselli et.al(2009a)的工作,他认为:最早的 GNN 模型(Scarselli et.al,2009b)可以在概率上近似于 measurable functions。Lei et.al(2017)表明,他们提出的架构位于图核的 RKHS(abbr. reproducing kernel Hilbert space 再生式原子核希尔伯特空间) 中,但没有明确研究它可以区分哪些图。这些作品都侧重于一个特定的体系结构,并不容易推广到多个体系结构。
相比之下,上述结论为分析和描述一个广泛类别的 GNN 的表达能力提供了一个更一般的理论框架。最近,许多基于 GNN 的架构被提出,包括和聚合和 MLP(巴塔格利亚等人,2016;斯卡塞利等人,2009b;Duvenaud等人,2015),而大多数没有理论推导。与许多先前的 GNN 架构相比,我们的图同构网络(GIN)在理论上更加充分,并且简单而强大。
measurable functions: 不太理解这个概念具体是什么函数,我个人暂且理解为可以通过公式表达的函数(或者能够通过最大近似理论去利用 MLPs 逼近的函数)
7 EXPERIMENTS
在实验部分比较了 GIN 于其他较弱的 GNN 变体在测试集,训练集上的表现。训练集能够去评估模型的表征能力,且测试集能评估模型的泛化能力。
Datasets. 我们采用 9 个图分类 benchmarks:4个生物信息学数据集(MUTAG,PTC,NCI1,PROTEINS)以及5个社交网络数据集(COLLAB,IMDB-BINARY,IMDB-MULTI,REDDIT-BINARY,REDDIT-MULTI5K)。重要的是,我们实验目的并不是让模型依赖于输入节点的特征,而是主要让模型从网络结构中学习。因此,在生物信息学 Graph 中,节点具有分类输入特征;但在社交网络中,节点没有特征。
对于社交网络数据集,我们创建节点特征如下:对于 REDDIT 数据集,我们将所有的节点特征向量设置为统一(因此,这里的特征是不具备信息的);对于其他的社交网络 Graphs,我们基于节点 degrees 去生成 one-hot encodings 以表示节点特征。数据集统计汇总于 table.1 更多的数据细节可以在 Appendix.I 中找到。
Models and configurations. 我们评估了 GINs(Eqs.4.1 and 4.2)以及其他 less powerful GNN 变体。而针对 GIN 框架,我们考虑它的两个变体:
- 基于 Eq.4.1 进行梯度下降学习参数 ϵϵ 的 GIN-ϵϵ
- 一个更简单的 GIN-0,其中 Eq.4.1 的参数 ϵϵ 固定为0。
实验表明 GIN-0 有更强大的性能:GIN-0 不仅与 GIN-ϵϵ 同样拟合训练数据,而且具备良好的泛化性能,而在测试精度方面略微但始终优于GIN-ϵϵ。对于其他较弱的 GNN 变体 我们考虑替换 GIN-0 的 sum 聚合,采用 mean or max-pooling,或者替换多层感知机为单层感知机。
在 Fig.4 以及 Table.1 中,模型会根据 其采用的聚合方式/感知机的层数 来命名,例如 mean-1-layer 和 max-1-layer 分别对应了 GCN 和 GraphSAGE,并且会在此基础上进行较小的修改。我们对 GINs 以及 GNN 变体都采用相同的 Graph Readout(Eq.4.2),为了更好的测试性能,生物学信息数据集上采用 sum readout,社交网络数据集采用 mean readout。
实验采用十折交叉验证,并且报告了交叉验证中,10次验证精度的平均值和标准差。对于所有的模型配置,采用5个 GNN 层(包括输入层),并且 MLPs 采用2层。Batch Normalization 应用于每一个 hidden layer。采用 Adam optimizer 并且初始化学习率为 0.01 并且以每 50 次 epochs 进行一次衰减率为 0.5 的权重衰减。我们对于每个数据集都需要调整的超参为:
- hidden units number:对于生物信息学 Graph 采用 {16, 32},社交网络 Graph 采用 64
- batch size:
- dropout ratio:{0, 0.5} after dense layer
- epochs number:调整为 10 次平均交叉验证精度最好的 single epoch
注意,由于数据集size较小,使用验证集进行超参调整时非常不稳定的,比如 MUTAG 验证集只包含 18 条数据。
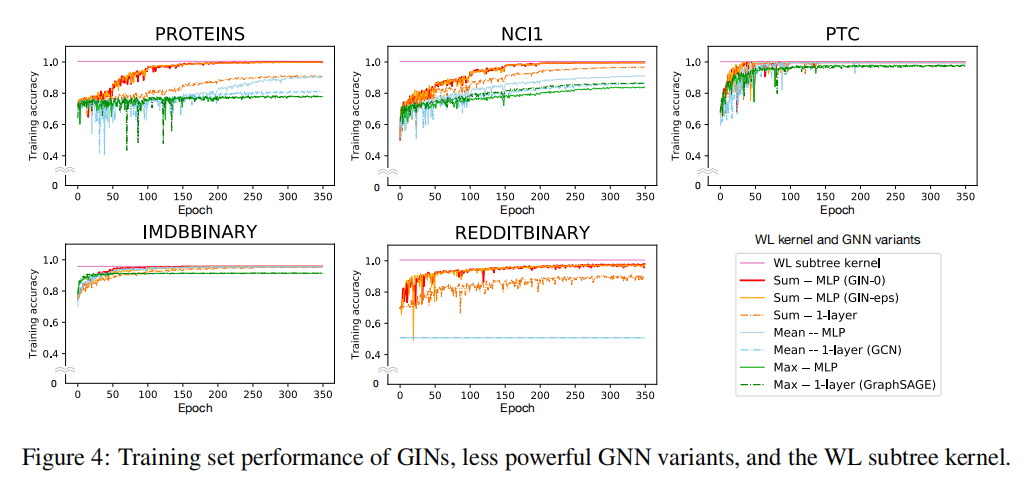
我们还报告了对于不同 GNNs 的训练精度,所有的模型超参都是固定的:
- 5 GNN layers(include input layer)
- hidden units of size 64
- minibatch of size 128
- dropout ratio 0.5
为了比较,WL subtree kernel 的训练精度也会被报告,其中我们将迭代次数设置为4,对比 5 GNN layers。
Baselines. 我们将上述 GNNs 与最先进的图分类基准进行比较:
- WL subtree kernel,采用 C-SVM 作为分类器,我们调整的超参为 SVM 的 C;WL iterations number ∈{1,2,...,6}∈{1,2,...,6}
- 最先进的深度学习架构 —— DCNN,PATCHY-SAN,DGCNN
- Anonymous Walk Embeddings
对于深度学习方法和 AWL,我们报告了原始论文中报告的准确度。
7.1 RESULTS
Training set performance. 我们通过比较 GNNs 的训练精度来验证之前对 GNN 模型表征能力的理论分析。具备较高表征能力的模型应该具备较高的训练准确度。Fig.4 展示了具备相同超参的 GINs 和较弱的 GNN 变体的训练曲线。首先,理论上最强大的 GNN,即 GIN-ϵϵ 和 GIN-0 都能够完美地拟合所有的训练集。
而在实验中,对比 GIN-0 可以发现,GIN-ϵϵ 针对参数 ϵϵ 的学习并没有在拟合训练数据中获得收益;采用 mean/max pooling 或单层感知机的 GNN 变体在许多数据集上都产生了严重的过拟合。可以发现,这些模型的训练精度水平与之前分析的 模型表征能力进行的排名 一致,在训练精度方面
- MLPs 大于 1-layer perceptions
- sum aggregators 大于 mean / max aggregators
在我们的数据集上,GNN 的训练精度从未超过 WL subtree kernel 的训练精度,这是意料之中的,因为 GNN 通常比 WL-test 的判别能力低。例如在 IMDBBINARY 上,没有任何一个模型能够完美地拟合训练集,GNN 最多也只能够达到与 wL kernel 相同的训练精度。这种实验结果与论文得出的结论一致,即 WL-test 是基于聚合的 GNN 的表征能力上限。然而 WL kernel 无法学习如何组合节点特征(即不能具备泛化能力),这对于预测任务来说是非常关键的,接下来将说明这个部分。
Test set performance.
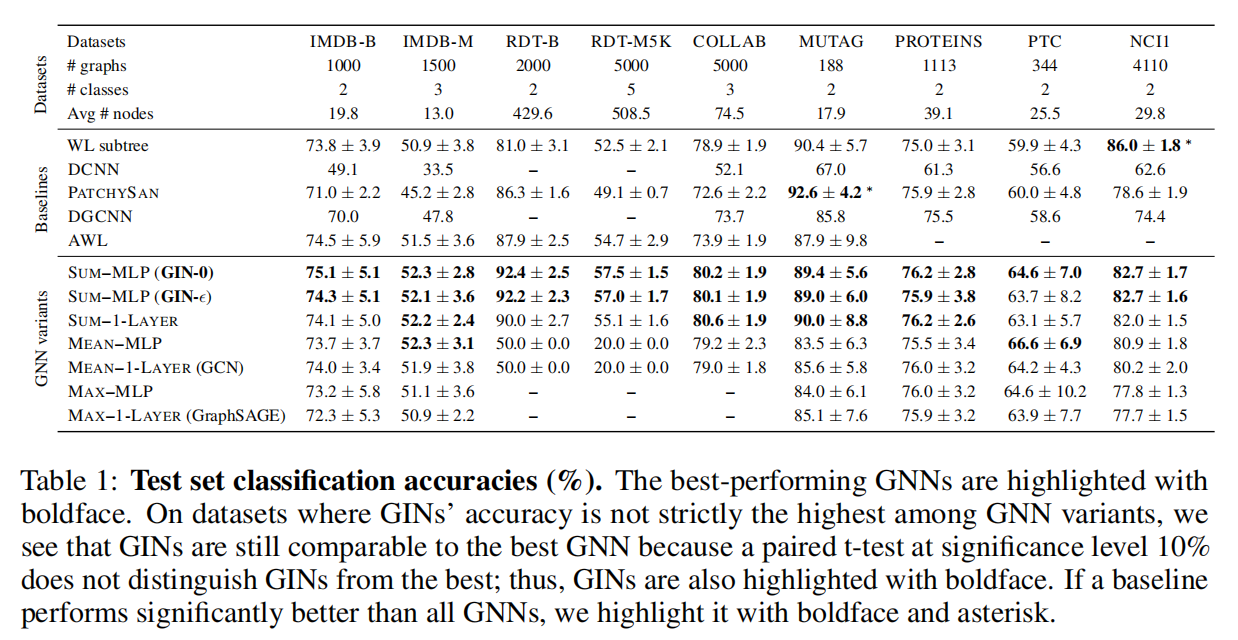
接下来,我们比较 test accuracies。虽然我们的理论结果并没有直接谈到 GNNs 的泛化能力,但我们有理由去期待具备强大表征能力的 GNNs 能够准确捕捉感兴趣的图结构,从而能够很好地泛化。Table.1 比较了 GINs(Sum-MLP),其他 GNN 变体以及一些最先进的 test accuracy baselines。
首先,对于 GINs,尤其是 GIN-0,在 9 个数据集上都比较弱的 GNN 变体表现都好。GINs 在社交网络数据集上表现更好,这种类型的数据包含了大量的训练图数据。
而对于 Reddit 数据集,所有节点都共享相同的标量作为节点特征。GINs 以及 sum-aggregation GNNs 都准确地捕获了图结构,并且显著优于其他模型。然而,mean-aggregation GNNs 无法捕获未标记图的任何结构(如 Section 5.2 所预测的一样),并且表现甚至不如随机预测。
即使提供节点的 degree 作为输入特征,基于 mean-aggregation GNNs 也远远不如 sum-aggregation GNNs(在 REDDIT-BINARY 数据集上,mean-mlp aggregation 准确率为 71.2±4.6%,在REDDIT-MULTI5K 准确率为 41.3±2.1%)
比较 GINs(GIN-0 以及 GIN-ϵϵ),我们观察到 GIN-0 的性能略优于 GIN-ϵϵ。由于两种模型都能够很好地拟合训练数据,GIN-0 可能是因为比 GIN-ϵϵ 更简单因此获得了更好的泛化能力。
8 CONCLUSION
在本文中,我们开发了一个关于 GNNs 表征能力推到的理论基础,并证明了当下流行的 GNN variants 的表征能力上限。我们还基于邻域聚合设计了一个可证明的性能最强大的 GNN。未来工作的一个有趣方向是超越邻域聚合(或消息传递),以追求更强大的图学习架构。为了完成这个愿景,理解和改进 GNN 的泛化特性以及更好地理解它们的优化前景也会很有趣。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK