

算法之「恶」:如何挣脱推荐系统的「囚禁」?
source link: https://www.woshipm.com/pd/5758766.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
你是不是也有过这样的经历或感受:只要刷起短视频软件,不花上一定时间消磨在其中,你滑动的手指好像就停不下来?而在这现象背后,可能是“推荐系统”和“算法”在让你“上瘾”。具体如何解读推荐系统的存在和作用?一起来看看作者的分析。

不知道你是不是跟我一样,特别喜欢刷抖音,经常一天要刷个把小时,无论是通勤路上,还是工作间隙,一有时间就会刷起来,在自己不间断发出的「哈哈」和「卧槽」声中逐渐沉迷,无法自拔。
不过可能不只你我,截至2022年第四季度,抖音日活用户超7亿,人均日使用时长高达140分钟,换句话说,每天有7亿人,平均刷2个多小时短视频,这还不算快手、微信视频号等其它平台。短视频到底有什么魔力,能够让我们如此「上瘾沉迷」?
本文将从推荐系统实现原理的角度剖析短视频「上瘾」原因和不良影响,以及对我们该如何应对。
一、为什么会对短视频「上瘾」?
短视频让我们上瘾的魔力归根结底就是:太好看了!非常符合我们每个人的观看内容偏好,就像预言家一样,总能精准的知道,我们会喜欢什么样的内容。
能达到这样的精准效果,短视频平台靠的主要是:海量的UGC视频内容供给,巨量的用户及行为数据,智能推荐算法。这三者组成一套内容推荐系统,做到对内容和人的充分理解,为我们提供精准的内容消费预测和候选推荐。
这就像你的朋友们给你推荐电影,朋友A自身看过很多电影,同时也大概知道你喜欢或者讨厌什么类型的电影;另一个朋友B没怎么看过电影,跟你也不太熟悉。那么朋友A更大概率能给你推荐符合你口味的电影。
这套推荐系统也像是你的一个「朋友」,只不过他看过数百亿乃至千亿数量的短视频,同时也了解你几乎所有的画像信息(年龄/性别/收入/位置/兴趣等)和此前你对视频做过的所有行为数据(完播/点赞/评论/关注/转发等),到今天为止,这个「朋友」找到符合你口味短视频的概率非常吓人,接近100%,并且几乎是在任何你打开短视频app的时候。这个「朋友」具体是怎么工作的呢,能有如此恐怖的效果?
内容推荐系统的工作流程大概如下图所示:
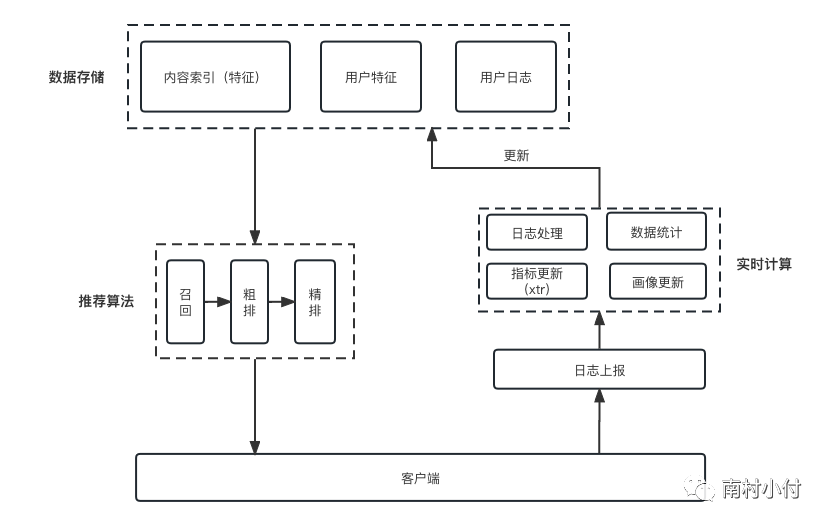
推荐算法的流程,简单理解可以分为召回,粗排(序)和精排(序)三个步骤。召回就是从我们的海量内容库中,按照各种理由找到部分作品进入用户的候选作品池,这些召回理由有很多,比如当前最热的作品,比如你的朋友点赞过的作品,等等。
粗排主要是做一些简单粗略的排序,用于在召回后减少候选池的内容量级,比如各个召回源的TOPK排序,粗排会将候选池截断到一个可控的量级(一般到千的量级),不然精排阶段会非常耗时,精排一般都采用模型进行排序,比如LR(线性回归),LR+GBDT(线性回归+树模型),FM(因子分解模型),DNN(深度学习模型)等,排序后候选内容池会到百量级。
这些排序策略和模型的输入都是用户的各种静态和行为特征(也就是图中的用户特征和用户行为日志,比如你的地理位置信息、你对内容的点赞、评论等行为)以及内容的特征(比如,内容的标题、分类、基于画面理解提取的特征向量等),输出就是你对某一个候选视频的各种行为目标的预测,比如,多大概率会看完、多大概率会点赞等等。
基于这些目标预测,最终会综合成一个唯一排序分值,决定最终推荐你的候选视频的顺序。然后会下发到你的手机App上,让你能刷到,你刷到之后的所有后续对于视频的行为,也会通过日志实时上报和进行计算,再更新相关的所有数据,用于迭代下一刷视频的推荐。
想必到这里你会发现,推荐系统是一个动态循环,不停的基于内容的更新,用户的行为反馈进行迭代和更新,保证最终预测准确的概率逼近100%。(更详细的推荐系统介绍,感兴趣的可以看我之前写的一篇文章运营必知「推荐」二三事)这套系统,可以很好地提升你消费内容的体验,让你对每个候选视频都很满意的看完,甚至产生互动行为(点赞评论),不停的刷下去,因为这套系统优化的目标就是让你做这些。
有没有突然感觉后背发凉,表面上看,推荐系统似乎为我们消费内容提供便捷的服务,但从推荐系统的角度看,我们的行为似乎是被「他」掌控的。
推荐系统比我们自己都更了解自己,当我们对短视频「上瘾」后,我们的那些自由的意志,我们对世界的认知和各种决策是不是也会被这套机器系统所左右?如果有人恶意的使用这套系统,我们会不会被潜移默化的植入某些想法(洗脑),进而影响我们在现实世界的行为?
答案是肯定的!而这一切的原因都是来自算法的系统性偏差。
二、算法的系统性偏差(Bias)
通过前面的介绍,我们知道推荐系统的工作流程,是「用户」通过与内容的交互,产生了「数据」,这些数据再被推荐「模型」用于训练和预测用户后续的内容偏好,「模型」预测的结果再推荐给「用户」,进一步影响用户未来的行为和决策。由此可见,推荐系统是由用户(User)、数据(Data)、模型(Model),三者相互作用产生的一个动态的反馈闭环。如下图所示:
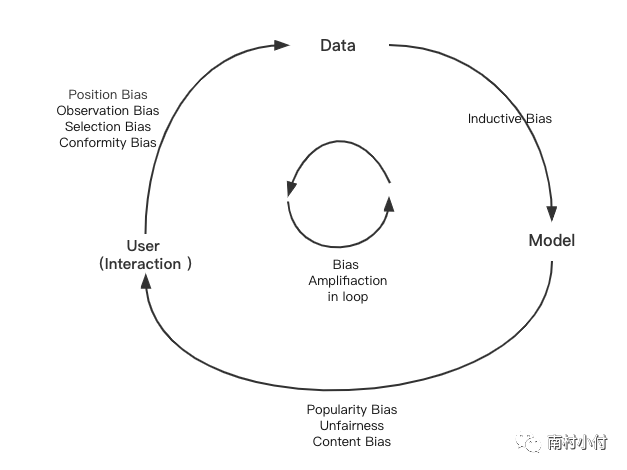
在这个循环中,每一步推荐系统都会产生一定的偏差(Bias)。在用户(User)和内容交互产生数据(Data)的过程中会产生如下Bias:
- 位置偏差(Position Bias):位置偏差在搜索系统中是一个经典并持续存在的偏差,同样在推荐系统中也会存在,用户更倾向于和位置靠前的内容进行互动。尤其会对“用户点击行为”作为正例信号进行学习的模型,位置偏差会在训练、评估阶段产生错误影响。
- 观测/曝光偏差(Observation Bias/Exposure Bias):因为仅有一部分特定内容曝光给了用户,没有曝光的内容却也不能直接认为是用户不感兴趣,用户用户自身的喜好(比如主动搜索,点击等)或者所处的地理位置,兴趣圈层,都会导致部分内容更容易曝光。
- 选择偏差(Selection Bias):用户倾向于给自己喜欢或者不喜欢的内容进行反馈,那些喜恶程度不高的一般就不会有反馈,这就会导致,可观测到的互动反馈数据并不是所有内容的代表性样本。换而言之,这部分数据是“非随机缺失”,这就会导致后续的内容更偏向两个极端,完全不给讨厌的内容,只给超级喜欢的。
- 从众偏差(Conformity Bias):用户对于内容的评价和反馈会和大众趋同,比如一个几万赞的视频,比一个没有赞的视频更容易让用户点赞。
在数据进入模型的阶段,因为模型有各种假设,用于提升模型的泛化能力,例如我们常用的奥卡姆剃刀原理、CNN的局部性假设、RNN的时间依赖假设、注意力机制假设等等,通常这些是有利的,但是也会造成也会造成归纳偏差(Inductive Bias)。
模型输出结果给到用户的过程中,推荐结果常见的偏差有:
- 热门偏差(Popularity Bias):热门的内容获得了比预期更高的热度,长尾物品得不到足够曝光、马太效应严重。
- 不公平性(Unfairness):这个偏差的本质原因是数据的有偏,会带来社会性问题(年龄、性别、种族、社交关系多少等歧视)。不公平性更多是由于系统数据分布不平衡造成的,例如某个基本由年轻用户组成的内容平台较难对于老年用户的行为进行建模,系统推荐出的视频会更倾向于有年轻化。
- 内容偏差(Content Bias):内容本身也存在巨大的偏差,虽然当前短视频平台有着海量的内容,但这些内容中,品类和主题分布上一定是不均匀的,而且会存在各种导向的内容,有的甚至是欺骗性的内容,比如我们经常看到的标题党,夸大性内容和谣言,这些内容上的偏差对于推荐系统来说是很难甄别的。
上述的这些偏差,在推荐系统的反馈循环中会不断被加剧(Bias Amplification in Loop),模型在存在偏差的历史数据中,通过不断的迭代学习,让偏差进一步加深,导致推荐生态逐步恶化。有些偏差目前是有办法解决的,比如位置偏差,但有些偏差,比如内容偏差,不公平性,这些都是固有数据导致的,难以完全解决。
值得注意的是,虽然偏差在不断加深,但用户的使用时长却随着明显增长,当我们尝试去解决一些偏差的时候(Debias),大概率都是会带来用户使用时长的下降,特别是在比较短的周期内,这像极了毒品上瘾后的戒断反应。造成这种「戒断反应」的本质原因是因为偏差的产生,基本是来自用户自身的偏见,而推荐系统在不断的强化这个偏见。
这种偏见的强化,会给我们的认知带来很多不良的影响:
- 推荐系统对于偏见的强化,会打破我们在强化现有想法和获取新想法之间的认知平衡,它使得我们周围充满着我们熟悉且认可得想法和观点,让我们对自己的想法过于自信,大家应该都有类似的例子,我们很容易在短视频上扎堆看到跟你想法一致的视频,很多内容创造者也在刻意的生产迎合大家的内容,会让你觉得自己十分的正确,使我们沉浸在同质化的信息和观点之中,导致人对不同的观点、文化和思想缺乏了解。
- 推荐系统会把我们的注意力限制在一个非常狭窄的领域内,也就是人们常说的「信息茧房」,限制我们探索到新内容的可能,甚至会带来意识形态的偏见,导致人的思想收到限制,有可能使人深陷分裂和对立的泥淖之中。大家看看相同的内容,在抖音下的评论和在twitter下的评论,就大概能理解这种对立。
- 在有偏的内容中,我们接触到的信息量有限,缺乏全面的信息支持,容易误导判断力,做出不准确的判断和决策。特别是很多虚假和错误的引导内容,更大概率的造成我们的判断错误。大家自己回想一下,那些广为流传的谣言。
推荐系统,仿佛在悄悄地编织一个「囚笼」,让我们在手机屏幕的方寸之地沉迷且享受,消磨着时间。幸运的是,我们还有自醒的可能,想必你也曾在刷了几个小时短视频后,陷入深深的不安和烦躁。那么我们如何才能挣脱推荐系统对我们的「囚禁」呢?
三、如何挣脱推荐系统的「囚禁」?
其实挣脱推荐系统最简单的方法就是,卸载掉这些个性化推荐的内容app。网信办在2021年8月份提出,并于2022年3月1日正式施行的《互联网信息服务算法推荐管理规定》中直指算法推荐功能,提出算法推荐服务提供者应当向用户提供不针对个人特征的选项,或者向用户提供便捷的关闭算法推荐服务的选项。我们可以看出来,国家也意识到了算法的不良影响,并在尝试帮我们解决这个问题。
但我觉得卸载或者关掉所谓的推荐系统,不是对抗算法「囚禁」的好方法。我们身处信息爆炸的时代,推荐系统本身是一个为我们筛选和过滤的工具,而让算法能「囚禁」我们的原因是我们丧失了自主思考的习惯,选择部分甚至无条件的相信他们提供的内容。
想要对抗推荐系统的「囚禁」,只能是我们自我觉醒,拿回信息选择的主动权。
- 多元化的信息源,不要只局限于特定的平台或者特定的社交圈子,可以通过关注不同的社交媒体账号、阅读不同领域的文章、参加不同类型的线下活动等方式获取多元化的信息。多主动寻找不同观点,善用搜索工具和一些信息聚合工具,不是一味的仅仅接受信息,这可以有效的帮助我们打破「信息茧房」,发现更大的世界。
- 培养批判性思维:对获取信息进行分析和评估,不要轻易相信和传播未经证实的消息。对于重要的信息,一定要查证信息的来源,并且比较不同来源的信息,要能够区分什么是事实,什么是观点,分析信息中的逻辑,从多个角度思考问题,避免受到单一思维模式的影响。有很多介绍批判性思维的书和文章,大家有兴趣可以看看。
最后,借用Neil Postman(尼尔·波兹曼)在《技术垄断:文化向技术投降》书中说的一句话作为结尾:「每一种新技术都既是包袱又是恩赐,不是非此即彼的结果,而是利弊同在的产物。」
我想推荐系统亦是如此。
主要参考资料:
- Bias and Debias in Recommender System: A Survey and Future Directions(https://dl.acm.org/doi/abs/10.1145/3564284)
- 《推荐系统实战》项亮
- 推荐生态中的bias和debias (https://zhuanlan.zhihu.com/p/342905546)
- 算法社会的“囚徒风险”(https://tisi.org/19332)
- Support byChatGPT
专栏作家
南村小付,微信公众号:南村小付,人人都是产品经理专栏作家。快手高级产品经理,曾任职阿里,欢聚时代,7年互联网产品设计运营经验。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK