

Swift Regex Tutorial: Getting Started [FREE]
source link: https://www.kodeco.com/36182126-swift-regex-tutorial-getting-started
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Swift Regex Tutorial: Getting Started
Master the pattern-matching superpowers of Swift Regex. Learn to write regular expressions that are easy to understand, work with captures and try out RegexBuilder, all while making a Marvel Movies list app!
By Ehab Yosry Amer.
Searching within text doesn’t always mean searching for an exact word or sequence of characters.
Sometimes you want to search for a pattern. Perhaps you’re looking for words that are all uppercase, words that have numeric characters, or even a word that you may have misspelled in an article you’re writing and want to find to correct quickly.
For that, regular expressions are an ideal solution. Luckily, Apple has greatly simplified using them in Swift 5.7.
In this tutorial, you’ll learn:
- What a regular expression is and how you can use it.
- How Swift 5.7 made it easier to work with regular expressions.
- How to capture parts of the string you’re searching for.
- How to use
RegexBuilderto construct a complex expression that’s easy to understand. - How to load a text file that is poorly formatted into a data model.
- How to handle inconsistencies while loading data.
Getting Started
Download the starter project by clicking Download Materials at the top or bottom of the tutorial.
The app you’ll be working on here is MarvelProductions. It shows a list of movies and TV shows that Marvel has already published or announced.
Here’s what you’ll see when you first build and run:
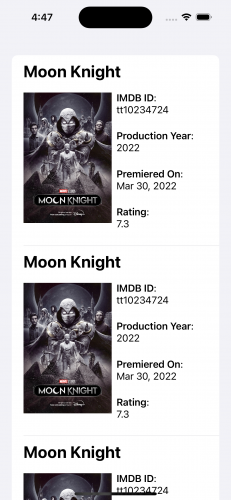
You’ll notice that there’s only one repeated entry, which is great for Moon Knight fans but a bit disheartening otherwise. That’s because the app’s data needs some work before it’s ready to display. You’ll use Swift Regex to accomplish this.
Understanding Regular Expressions
Before you get into the app directly, you need to understand what regular expressions, also known as regex, are and how to write them.
Most of the time, when you search for text, you know the word you want to look for. You use the search capability in your text editor and enter the word, then the editor highlights matches. If the word has a different spelling than your search criteria, the editor won’t highlight it.
Regex doesn’t work that way. It’s a way to describe sequences of characters that most text editors nowadays can interpret and find text that matches. The results found don’t need to be identical. You can search for words that have four characters and this can give you results like some and word.
To try things out, open MarvelProductions.xcodeproj file in the starter folder. Then select the MarvelMovies file in the Project navigator.

While having the text file focused in Xcode, press Command-F to open the search bar. Click on the dropdown with the word Contains and choose Regular Expression.

In the search text field, you can still enter a word to search for in the file like you normally would, but now you can do much more. Enter \d in the text field. This will select every digit available in the file.

Try to select numbers that aren’t part of the id values that start with tt. Enter the following into the Search field:
\b(?<!tt)\d+

The regex you just entered matches any digits in a word that don't start with tt. The breakdown of this regex is as follows:
- Word boundary:
\b. - Negative lookbehind for tt:
(?<!tt). - One or more digits:
\d+.
Swiftifying Regular Expressions
Swift 5.7 introduces a new Regex type that's a first-degree citizen in Swift. It isn't a bridge from Objective-C's NSRegularExpression.
Swift Regex allows you to define a regular expression in three different ways:
- As a literal:
let digitsRegex = /\d+/From a String:
let regexString = #"\d+"# let digitsRegex = try? Regex(regexString)Using RegexBuilder:
let digitsRegex = OneOrMore {
CharacterClass.digit
}
The first two use the standard regular expression syntax. What's different about the second approach is that it allows you to create Regex objects dynamically by reading the expressions from a file, server or user input. Because the Regex object is created at runtime, you can't rely on Xcode to check it, which is a handy advantage to the first approach.
The third is the most novel. Apple introduced a new way to define regular expressions using a result builder. You can see it's easier to understand what it's searching for in the text. An arguable drawback is that this approach is more verbose.
Now it's time to see Swift Regex in action. Open the Project navigator and select the file ProductionsDataProvider.swift.

Loading the Marvel Movies List
As you can see, the data provider only loads a few sample objects and isn't loading the data from the MarvelMovies file. You'll use regular expressions to find the values and load them into an array of MarvelProductionItem objects. You might wonder, "Why do I need to use regular expressions to load the file? It looks clear, and I can separate it with normal string operations."
The answer is "looks can be deceiving". The file looks organized to the human eye, but that doesn't mean the data itself is organized.
If you look closely, empty spaces separate the fields. This space can be two or more space characters, one or more tab characters or a collection of both of them together.
Using usual string splitting is possible if separators are explicit and unique, but in this case, the separator string varies. Also, spaces appear in the content, making it hard to use conventional means to break down each line to parse the values. Regex is ideal here!
Reading the Text File
The first thing you need to do is load the text file. Replace the existing implementation of loadData() in ProductionsDataProvider.swift with:
func loadData() -> [MarvelProductionItem] {
// 1
var marvelProductions: [MarvelProductionItem] = []
// 2
var content = ""
if let filePath = Bundle.main.path(
forResource: "MarvelMovies",
ofType: nil) {
let fileURL = URL(fileURLWithPath: filePath)
do {
content = try String(contentsOf: fileURL)
} catch {
return []
}
}
// TODO: Define Regex
// 3
return marvelProductions
}
This code does three things:
- Defines
marvelProductionsas an array of objects that you'll add items to later. - Reads the contents of the MarvelMovies file from the app's bundle and loads it into the property
content. - Returns the array at the end of the function.
You'll do all the work in the TODO part.
If you build and run now, you'll just see a blank screen. Fear not, you're about to get to work writing the regular expressions that find the data to fill this.
Defining the Separator
The first regular expression you'll define is the separator. For that, you need to define the pattern that represents what a separator can be. All of the below are valid separator strings for this data:
-
SpaceSpace -
SpaceTab Tab-
TabSpace
However, this is not a valid separator in the MarvelMovies file:
Space
A valid separator can be a single tab character, two or more space characters, or a mix of tabs and spaces but never a single space, because this would conflict with the actual content.
You can define the separator object with RegexBuilder. Add this code before the return marvelProductions:
let fieldSeparator = ChoiceOf { // 1
/[\s\t]{2,}/ // 2
/\t/ // 3
}
In regular expression syntax, \s matches any single whitespace character, so a space or a tab, whereas \t only matches a tab.
The new code has three parts:
-
ChoiceOfmeans only one of the expressions within it needs to match. - The square brackets define a set of characters to look for and will only match one of those characters, either a space or a tab character, in the set. The curly braces define a repetition to the expression before it, to run two or more times. This means the square brackets expression repeats two or more times.
- An expression of a tab character found once.
fieldSeparator defines a regex that can match two or more consecutive spaces with no tabs, a mix of spaces and tabs with no specific order or a single tab.
Sounds about right.
Now, for the remaining fields.
Defining the Fields
You can define the fields in MarvelProductionItem as follows:
- id: A string that starts with tt followed by several digits.
- title: A string of a different collection of characters.
- productionYear: A string that starts with ( and ends with ).
- premieredOn: A string that represents a date.
- posterURL: A string beginning with http and ends with jpg.
- imdbRating: A number with one decimal place or no decimal places at all.
You can define those fields using regular expressions as follows. Add this after the declaration of fieldSeparator before the function returns:
let idField = /tt\d+/ // 1
let titleField = OneOrMore { // 2
CharacterClass.any
}
let yearField = /\(.+\)/ // 3
let premieredOnField = OneOrMore { // 4
CharacterClass.any
}
let urlField = /http.+jpg/ // 5
let imdbRatingField = OneOrMore { // 6
CharacterClass.any
}
These regex instances are a mix between RegexBuilders and literals.
The objects you created are:
- idField: An expression that matches a string starting with tt followed by any number of digits.
- titleField: Any sequence of characters.
- yearField: A sequence of characters that starts with ( and ends with ).
- premieredOnField: Instead of looking for a date, you'll search for any sequence of characters, then convert it to a date.
- urlField: Similar to yearField, but starting with http and ending with jpg.
-
imdbRatingField: Similar to premieredOnField, you'll search for any sequence of characters then convert it to a
Float.
Matching a Row
Now that you have each row of the MarvelMovies file broken down into smaller pieces, it's time to put the pieces together and match a whole row with an expression.
Instead of doing it all in one go, break it down into iterations to ensure that each field is properly matched and nothing unexpected happens.
Add the following Regex object at the end of loadData(), just before return marvelProductions:
let recordMatcher = Regex { // 1
idField
fieldSeparator
}
let matches = content.matches(of: recordMatcher) // 2
print("Found \(matches.count) matches")
for match in matches { // 3
print(match.output + "|") // 4
}
This code does the following:
- Defines a new Regex object that consists of the idField regex followed by a fieldSeparator regex.
- Gets the collection of matches found in the string you loaded from the file earlier.
- Loops over the found matches.
- Prints the output of each match followed by the pipe character, |.
Build and run. Take a look at the output in the console window:
Found 49 matches tt10857160 | tt10648342 | tt13623148 | tt9419884 | tt10872600 | tt10857164 | tt9114286 | tt4154796 | tt10234724 | . . .
Notice the space between the text and pipe character. This means the match included the separator. So far, the expression is correct. Now, expand the definition of recordMatcher to include titleField:
let recordMatcher = Regex {
idField
fieldSeparator
titleField
fieldSeparator
}
Build and run, then take a look at the console output:
Found 1 matches tt10857160 She-Hulk: Attorney at Law ........|
What just happened? Adding the title expression caused the rest of the file to be included in the first match except for the final rating value.
Well... this unfortunately makes sense. The title expression covers any character type. This means that even separators, numbers, URLs and anything gets matched as part of the title. To fix this, you want to tell the expression to consider looking at the next part of the expression before continuing with a repetition.
Looking Ahead
To get the expression to look ahead, you want the operation called NegativeLookAhead. In regular expression syntax, it's denoted as (?!pattern), where pattern is the expression you want to look ahead for.
titleField should look ahead for fieldSeparator before resuming the repetition of its any-character expression.
Change the declaration of titleField to the following:
let titleField = OneOrMore {
NegativeLookahead { fieldSeparator }
CharacterClass.any
}
Build and run. Observe the output in the console log:
Found 49 matches tt10857160 She-Hulk: Attorney at Law | tt10648342 Thor: Love and Thunder | tt13623148 I Am Groot | tt9419884 Doctor Strange in the Multiverse of Madness | tt10872600 Spider-Man: No Way Home |
Excellent. You fixed the expression, and it's back to only picking up the fields you requested.
Before you add the remaining fields, update ones with an any-character-type expression to include a negative lookahead. Change the declaration of premieredOnField to:
let premieredOnField = OneOrMore {
NegativeLookahead { fieldSeparator }
CharacterClass.any
}
Then, change imdbRatingField to:
let imdbRatingField = OneOrMore {
NegativeLookahead { CharacterClass.newlineSequence }
CharacterClass.any
}
Since you expect the rating at the end of the line, the negative lookahead searches for a newline character instead of a field separator.
Update recordMatcher to include the remaining fields:
let recordMatcher = Regex {
idField
fieldSeparator
titleField
fieldSeparator
yearField
fieldSeparator
premieredOnField
fieldSeparator
urlField
fieldSeparator
imdbRatingField
}
Build and run. The console will show that it found 49 matches and will print all the rows correctly. Now, you want to hold or capture the relevant parts of the string that the expressions found so you can convert them to the proper objects.
Capturing Matches
Capturing data inside a Regex object is straightforward. Simply wrap the expressions you want to capture in a Capture block.
Change the declaration of recordMatcher to the following:
let recordMatcher = Regex {
Capture { idField }
fieldSeparator
Capture { titleField }
fieldSeparator
Capture { yearField }
fieldSeparator
Capture { premieredOnField }
fieldSeparator
Capture { urlField }
fieldSeparator
Capture { imdbRatingField }
/\n/
}
Then change the loop that goes over the matches to the following:
for match in matches {
print("Full Row: " + match.output.0)
print("ID: " + match.output.1)
print("Title: " + match.output.2)
print("Year: " + match.output.3)
print("Premiered On: " + match.output.4)
print("Image URL: " + match.output.5)
print("Rating: " + match.output.6)
print("---------------------------")
}
Build and run. The console log should output each row in full with a breakdown of each value underneath:
Found 49 matches Full Row: tt10857160 She-Hulk: Attorney at Law...... ID: tt10857160 Title: She-Hulk: Attorney at Law Year: (2022– ) Premiered On: Aug 18, 2022 Image URL: https://m.media-amazon.com/images/M/MV5BMjU4MTkxNz......jpg Rating: 5.7 --------------------------- Full Row: tt10648342 Thor: Love and Thunder..... ID: tt10648342 Title: Thor: Love and Thunder Year: (2022) Premiered On: July 6, 2022 Image URL: https://m.media-amazon.com/images/M/MV5BYmMxZWRiMT......jpg Rating: 6.7 ---------------------------
Before you added any captures, the output object contained the whole row. By adding captures, it became a tuple whose first value is the whole row. Each capture adds a value to that tuple. With six captures, your tuple has seven values.
Naming Captures
Depending on order isn't always a good idea for API design. If the raw data introduces a new column in an update that isn't at the end, this change will cause a propagation that goes beyond just updating the Regex. You'll need to revise what the captured objects are and make sure you're picking the right item.
A better way is to give a reference name to each value that matches its column name. That'll make your code more resilient and more readable.
You can do this by using Reference. Add the following at the top of loadData():
let idFieldRef = Reference(Substring.self) let titleFieldRef = Reference(Substring.self) let yearFieldRef = Reference(Substring.self) let premieredOnFieldRef = Reference(Substring.self) let urlFieldRef = Reference(Substring.self) let imdbRatingFieldRef = Reference(Substring.self)
You create a Reference object for each value field in the document using their data types. Since captures are of type Substring, all the References are with that type. Later, you'll see how to convert the captured values to a different type.
Next, change the declaration of recordMatcher to:
let recordMatcher = Regex {
Capture(as: idFieldRef) { idField }
fieldSeparator
Capture(as: titleFieldRef) { titleField }
fieldSeparator
Capture(as: yearFieldRef) { yearField }
fieldSeparator
Capture(as: premieredOnFieldRef) { premieredOnField }
fieldSeparator
Capture(as: urlFieldRef) { urlField }
fieldSeparator
Capture(as: imdbRatingFieldRef) { imdbRatingField }
/\n/
}
Notice the addition of the reference objects as the as parameter to each capture.
Finally, change the contents of the loop printing the values of data to:
print("Full Row: " + match.output.0)
print("ID: " + match[idFieldRef])
print("Title: " + match[titleFieldRef])
print("Year: " + match[yearFieldRef])
print("Premiered On: " + match[premieredOnFieldRef])
print("Image URL: " + match[urlFieldRef])
print("Rating: " + match[imdbRatingFieldRef])
print("---------------------------")
Notice how you are accessing the values with the reference objects. If any changes happen to the data, you'll just need to change the regex reading the values, and capture it with the proper references. The rest of your code won't need any updates.
Build and run to ensure everything is correct. You won't see any differences in the console log.
At this point, you're probably thinking that it would be nice to access the value like a property instead of a key path.
The good news is that you can! But you'll need to write the expression as a literal and not use RegexBuilder. You'll see how it's done soon. :]
Transforming Data
One great feature of Swift Regex is the ability to transform captured data into different types.
Currently, you capture all the data as Substring. There are two fields that are easy to convert:
- The image URL, which doesn't need to stay as a string — it's more convenient to convert it to a
URL - The rating, which works better as a number so you'll convert it to a Float
You'll change these now.
In ProductionsDataProvider.swift, change the declaration of urlFieldRef to:
let urlFieldRef = Reference(URL.self)
This changes the expected type to URL.
Then, change imdbRatingFieldRef to:
let imdbRatingFieldRef = Reference(Float.self)
Similarly, this changes the expected data type to Float.
Next, change the declaration of recordMatcher to the following:
let recordMatcher = Regex {
Capture(as: idFieldRef) { idField }
fieldSeparator
Capture(as: titleFieldRef) { titleField }
fieldSeparator
Capture(as: yearFieldRef) { yearField }
fieldSeparator
Capture(as: premieredOnFieldRef) { premieredOnField }
fieldSeparator
TryCapture(as: urlFieldRef) { // 1
urlField
} transform: {
URL(string: String($0))
}
fieldSeparator
TryCapture(as: imdbRatingFieldRef) { // 2
imdbRatingField
} transform: {
Float(String($0))
}
/\n/
}
Notice how you captured urlField and imdbRatingField changed from just Capture(as::) to TryCapture(as::transform:). If successful, the later attempts to capture the value will pass it to transform function to convert it to the desired type. In this case, you converted urlField to a URL and imdbRatingField to a Float.
Now that you have the proper types, it's time to populate the data source.
Replace the code you have inside the loop to print to the console with:
let production = MarvelProductionItem( imdbID: String(match[idFieldRef]), // 1 title: String(match[titleFieldRef]), productionYear: ProductionYearInfo.fromString(String(match[yearFieldRef])), // 2 premieredOn: PremieredOnInfo.fromString(String(match[premieredOnFieldRef])), // 3 posterURL: match[urlFieldRef], // 4 imdbRating: match[imdbRatingFieldRef]) // 5 marvelProductions.append(production)
This creates an instance of MarvelProductionItem and appends it to the array, but there's a little more happening:
- You convert the first two Substring parameters to strings.
-
ProductionYearInfo is an
enum. You're creating an instance from the string value. You'll implement this part in the next section. For now, the value is always ProductionYearInfo.unknown. -
PremieredOnInfo is also an
enumyou'll implement in the next section. The value for now is PremieredOnInfo.unknown. - The value provided for the poster is a URL and not a string.
- The rating value is already a Float.
Build and run. You should see the Movies and TV shows listed on the app.

Creating a Custom Type
Notice that Production Year displays Not Produced and Premiered On shows Not Announced, even for old movies and shows. This is because you haven't implemented the parsing of their data yet so .unknown is returned for their values.
The production year won't always be a single year:
- If it's a movie, the year will be just one value, for example: (2010).
- If it's a TV show, it can start in one year and finish in another: (2010-2012).
- It could be an ongoing TV show: (2010- ).
- Marvel Studios may not have announced a date yet, making it truly unknown: (I).
The value for PremieredOnInfo is similar:
- An exact date may have been set, such as: Oct 10, 2010.
- An exact date may not yet be set for a future movie or show, in which case only the year is defined: 2023.
- Dates may not yet be announced: -.
This means the data for these fields can have different forms or patterns. This is why you captured them as text and didn't specify what exactly to expect in the expression.
You'll create an expression for each possibility and compare it with the value provided. The option you'll set is the expression that matches the string as a whole.
For example, if the movie is in the future and only a year is mentioned in the Premiered On field, then the expression that's expecting a word and two numbers with a comma between them will not succeed. Only the expression that is expecting a single number will.
Conditional Transformation
Start breaking down what you'll do with the year field. The value in the three cases will be within parentheses:
- If it's a single year, the expression is:
\(\d+\). - If it's a range between two years, it's two numbers separated by a dash:
\(\d+-\d+\). - If it's an open range starting from a year, it's a digit, a dash then a space:
\(\d+-\s\).
Open ProductionYearInfo.swift and change the implementation of fromString(_:) to:
public static func fromString(_ value: String) -> Self {
if let match = value.wholeMatch(of: /\((?<startYear>\d+)\)/) { // 1
return .produced(year: Int(match.startYear) ?? 0) // 2
} else if let match = value.wholeMatch(
of: /\((?<startYear>\d+)-(?<endYear>\d+\))/) { // 3
return .finished(
startYear: Int(match.startYear) ?? 0,
endYear: Int(match.endYear) ?? 0) // 4
} else if let match = value.wholeMatch(of: /\((?<startYear>\d+)–\s\)/) { // 5
return .onGoing(startYear: Int(match.startYear) ?? 0) // 6
}
return .unknown
}
Earlier, you read that there is a different way to name captured values using the regex literal. Here is how.
To capture a value in a regex, wrap the expression in parentheses. Name it using the syntax (?<name>regex) where name is how you want to refer to the capture and regex is the regular expression to be matched.
Time to break down the code a little:
- You compare the value against an expression that expects one or more digits between parentheses. This is why you escaped one set of parentheses.
- If the expression is a full match, you capture just the digits without the parentheses and return
.producedusing the captured value and casting it to anInt. Notice the convenience of using the captured value. - If it doesn't match the first expression, you test it against another that consists of two numbers with a dash between them.
- If that matches, you return
.finishedand use the two captured values as integers. - If the second expression didn't match, you check for the third possibility, a number followed by a dash, then a space to represent a show that's still running.
- If this matches, you return
.onGoingusing the captured value.
Each time, you use wholeMatch to ensure the entire input string, not just a substring inside it, matches the expression.
Build and run. See the new field properly reflected on the UI.
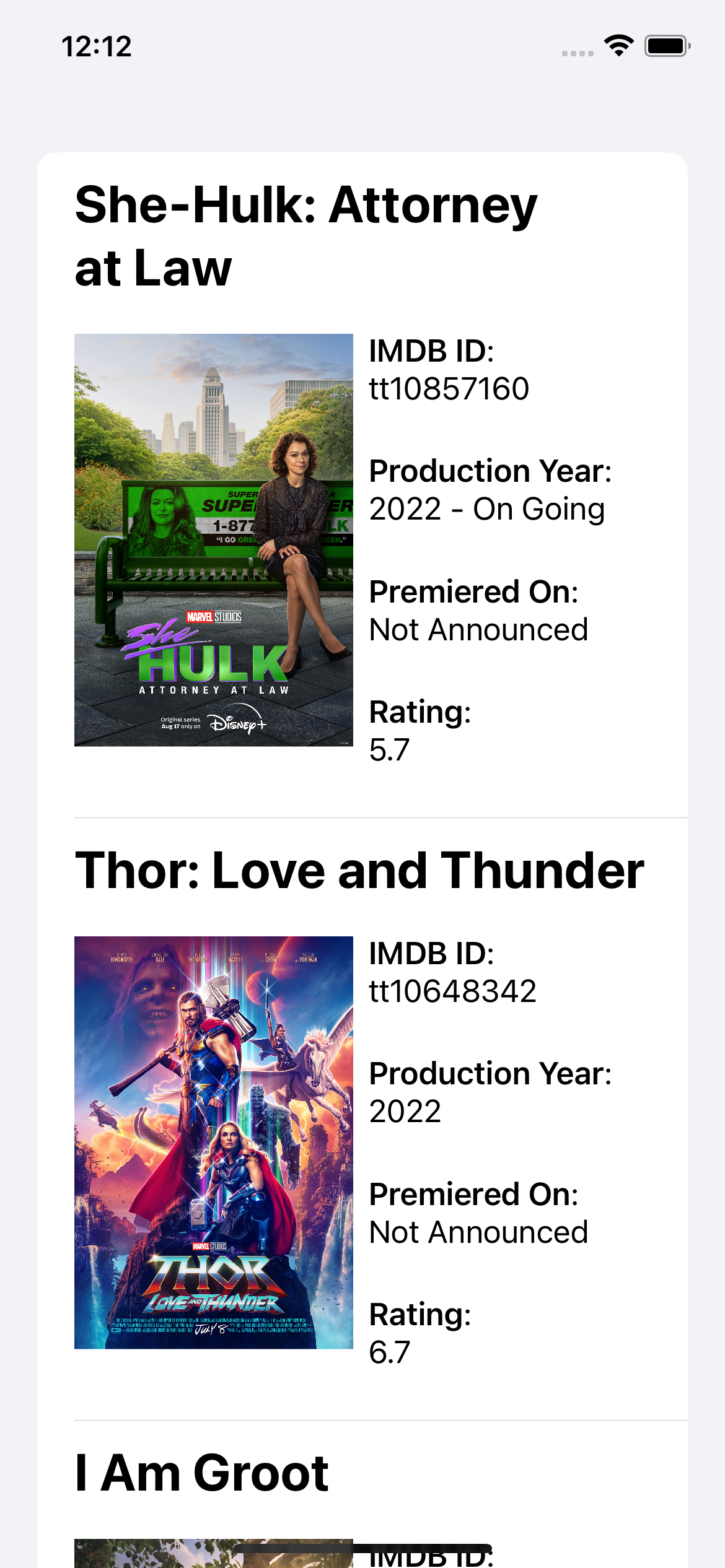
Next, open PremieredOnInfo.swift and change the implementation of fromString(_:) there to:
public static func fromString(_ value: String) -> Self {
let yearOnlyRegexString = #"\d{4}"# // 1
let datesRegexString = #"\S{3,4}\s.{1,2},\s\d{4}"#
guard let yearOnlyRegex = try? Regex(yearOnlyRegexString),
let datesRegex = try? Regex(datesRegexString) else { // 2
return .unknown
}
if let match = value.wholeMatch(of: yearOnlyRegex) { // 3
let result = match.first?.value as? Substring ?? "0"
return .estimatedYear(Int(result) ?? 0)
} else if let match = value.wholeMatch(of: datesRegex) { // 4
let result = match.first?.value as? Substring ?? ""
let dateStr = String(result)
let date = Date.fromString(dateStr)
return .definedDate(date)
}
return .unknown
}
This time, instead of regular expression literals, you store each regular expression in a String and then create Regex objects from those strings.
- You create two expressions to represent the two possible
valuecases you expect, either a four-digit year, or a full date consisting of a three-character full or shortened month name or a four-character month name, followed by one or two characters for the date, followed by a comma, a whitespace and a four-digit year. - Create the two Regex objects that you'll use to compare against.
- Try to match the whole string against the
yearOnlyRegexString`. If it matches, you return.estimatedYearand use the provided value as the year. - Otherwise, you try to match the whole string against the other Regex object,
datesRegexString. If it matches, you return.definedDateand convert the provided string to a date using a normal formatter.
\n where n is the number of the capture. Take care to access the captures safely in the correct order.
Build and run. Behold the Premiered On date correctly displayed. Nice work!

Where to Go From Here
Understanding regular expressions can turn you into a string manipulation superhero! You'll be surprised at what you can achieve in only a few lines of code. Regular expressions may challenge you initially, but they're worth it. There are many resources to help, including An Introduction to Regular Expressions, which links to even more resources!
To learn more about Swift Regex, check out this video from WWDC 2022.
You can download the completed project files by clicking the Download Materials button at the top or bottom of this tutorial.
Swift's Regex Builders are a kind of result builder. Learn more about this fascinating topic in Swift Apprentice Chapter 20: Result Builders.
We hope you enjoyed this tutorial. If you have any questions or comments, please join the forum discussion below!

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK