

ChatGPT 之后,对抗信息熵增
source link: https://www.36kr.com/p/2131633158384903
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ChatGPT 点燃了全球对未来的想象,还让沉寂已久的退休大佬决定重出江湖。是的,就是这两天被刷屏的王慧文。
这位曾经美团的核心人物,在社交媒体公开发表宣言。从最初的「必须参与」,到5000万美元带资入组,不在意岗位、薪资和title,求组队。第三天干脆宣布创建一个「全新生命体」,发出AI英雄榜,招募顶级人才。
这是ChatGPT传入中国后,最高调的起步公司。它面临的对手是那些国内外科技巨头。
微软推出基于 ChatGPT 的 New Bing 一天后,谷歌匆忙搬出 Bard 应战。虽然发布会的演示尴尬出错,市值一夜蒸发超过 7000 亿元,但微软和谷歌被认为是最有可能将ChatGPT大放光彩的公司。
国内公司也纷纷表态,百度、阿里、腾讯等大厂均表示自己在相关方向上有所布局。
百度三月即将上线「文心一言」,并接入百度搜索;阿里达摩院正在研发对话机器人,并计划与钉钉等生产力工具深度结合;腾讯虽未透露出具体的应用计划,但也底气十足地表示,自己在大模型(LLM)、机器学习(ML)和自然语言处理(NLP)等领域有着技术储备,进行应用探索。
总之,全网都是ChatGPT,被讨论,被神话,被人穷尽溢美之词,被视为是新一轮工业革命。但也有人发出警醒,ChatGPT也在被误解。
01 大力出奇迹
「我相信大厂声称自己正在布局 ChatGPT ,除了有保住股价的考虑,肯定也有了解这些前沿技术的团队。但是懂得大致的技术框架,和真正做出来跟 ChatGPT 效果一样好的东西,是两件事情。」一位 AI 公司的技术合伙人说。
OpenAI 对外发布了许多 ChatGPT 相关的研究性论文,讲述大致的思路,但不会透露技术细节。上述合伙人提醒,「其他公司想要复刻,还是需要自己摸索。而一旦涉及到技术细节的摸索,就要有特别大的投入。」
他认为,OpenAI 的伟大之处在于,在结果未知的情况下,就敢于下注。「一般公司为了活下去,不得不去考虑投入产出比。」模型的参数越多,意味着训练、调试时间的成倍增加。时间的翻倍,意味着硬件成本、人力成本的翻倍。
据《财富》杂志报道,2022年,OpenAI公司的收入预计不足3000万美元,净亏损5.45亿美元。而随着ChatGPT的火爆,可能进一步增加亏损,因为用户每一次调用,就会让OpenAI付出更多的计算资源和带宽成本。
本质上,ChatGPT 是一个表现令人惊艳的统计语言模型。
它的原理是,不断将前文的文本片段作为条件,预测下一个词语出现的概率,选中概率较高的单词,从而生成通顺的语句和段落。
ChatGPT 的技术——GPT 3.5,是由 Transformer 的技术线发展而来的。而 Transformer 的第一篇研究文章,其实是由谷歌发布的。
2017 年 6 月,谷歌发布论文《Attention is all you need》,推出能调用 6500万参数的 Transformer 模型,并首次将其用于理解人类语言;2018 年,谷歌又推出了 3亿参数的 BERT 模型。
只不过谷歌走得并不坚定,精力远比OpenAI分散。
OpenAI 在扩大模型的道路上一路狂奔。GPT-3 模型有 1750 亿个参数,训练的数据量高达 5000 亿个 token(约合 3000 亿个词)。
谷歌则在多种技术路线间摇摆不定,万亿参数的Switch Transformer并没有得到持续投入;Flan-T5模型一度有着胜过GPT-3的表现,但由于优化进度缓慢,还是由OpenAI先做出了ChatGPT这款产品,将大语言模型的神奇能力展现在我们面前。
北京智源人工智能研究院理事张宏江进一步解释,1750亿参数量,约有700G大小,一次训练成本大致花1200万美金。所以,大模型的发展不光是算法上的进步,在数据、算力上的要求也非常巨大。
这是一个「大力出奇迹」的故事。AI 模型的训练,并不是「一份耕耘,一份收获」的线性逻辑。
学术界有一个术语,叫做「涌现」(emergence),参数到了一定的程度,模型效果会迎来质的飞跃。但这个程度,究竟是10亿、100亿、1000亿,在实践之前都无从得知。对于 GPT 来说,「参数越多,效果越好」只是个「后验性」的结论。
OpenAI 的孤注一掷,等来了它的「涌现」;而谷歌的多线并行,却也是当时的「局部最优解」。
在大语言模型的训练上,「没有人比其他人领先超过两到六个月。」谷歌在相关研究领域硕果累累,并未落后于 OpenAI 半个身位,但精力分散拖累了它将学术成果落实为具体应用的步伐。
02 应用会更容易吗?
尽管ChatGPT技术内核的突破有非常高的门槛,但是OpenAI的大模型对产业的影响是绝对深远的。
张宏江将其形容为,是从小农经济到大规模生产的一个很重要的变化,就像当初电网的变革一样,此前自己发电,而今天要用 AI,不需要再做模型,而是用已有的大模型,以一种服务方式提供给用户。
ChatGPT 超过Tiktok,成为迄今为止用户最快破亿的应用。积累 1 亿用户,ChatGPT 用了两个月, Tiktok用了九个月,而 Instagram 则用了两年多。
OpenAI 的首席执行官 Sam Altman 曾在推特上表示,用户与 ChatGPT 每次交互的计算成本为「个位数美分」。随着用户破亿,其每月计算成本高达数百万美元。
基于此,OpenAI 开启了新一轮融资,也在探索如何直接用 ChatGPT 变现。
2月1日,OpenAI 正式官宣 ChatGPT Plus —— ChatGPT 的个人付费订阅服务。用户支付 20$/月的费用,即可享受高峰时段的优先访问、更快的响应时间,还能优先尝鲜新功能。

OpenAI 官宣ChatGPT Plus
to C 的付费制还在试点和探索阶段,to B 的付费 API 调用则是 OpenAI 现阶段的主要收入来源。
2021 年底,OpenAI 对公众开放了 GPT-3 的 API 接口,开发者和相关公司可付费调用,实现自然语言理解和生成的任务。除此之外,OpenAI 还开放了 Codex、DALL·E 的 API 接口,分别完成自然语言转代码、自然语言转图像的任务。路透社的数据显示,OpenAI 2022 年收入达数千万美元,2023 与 2024 的预计年收入分别为 2 亿美元和 10 亿美元。
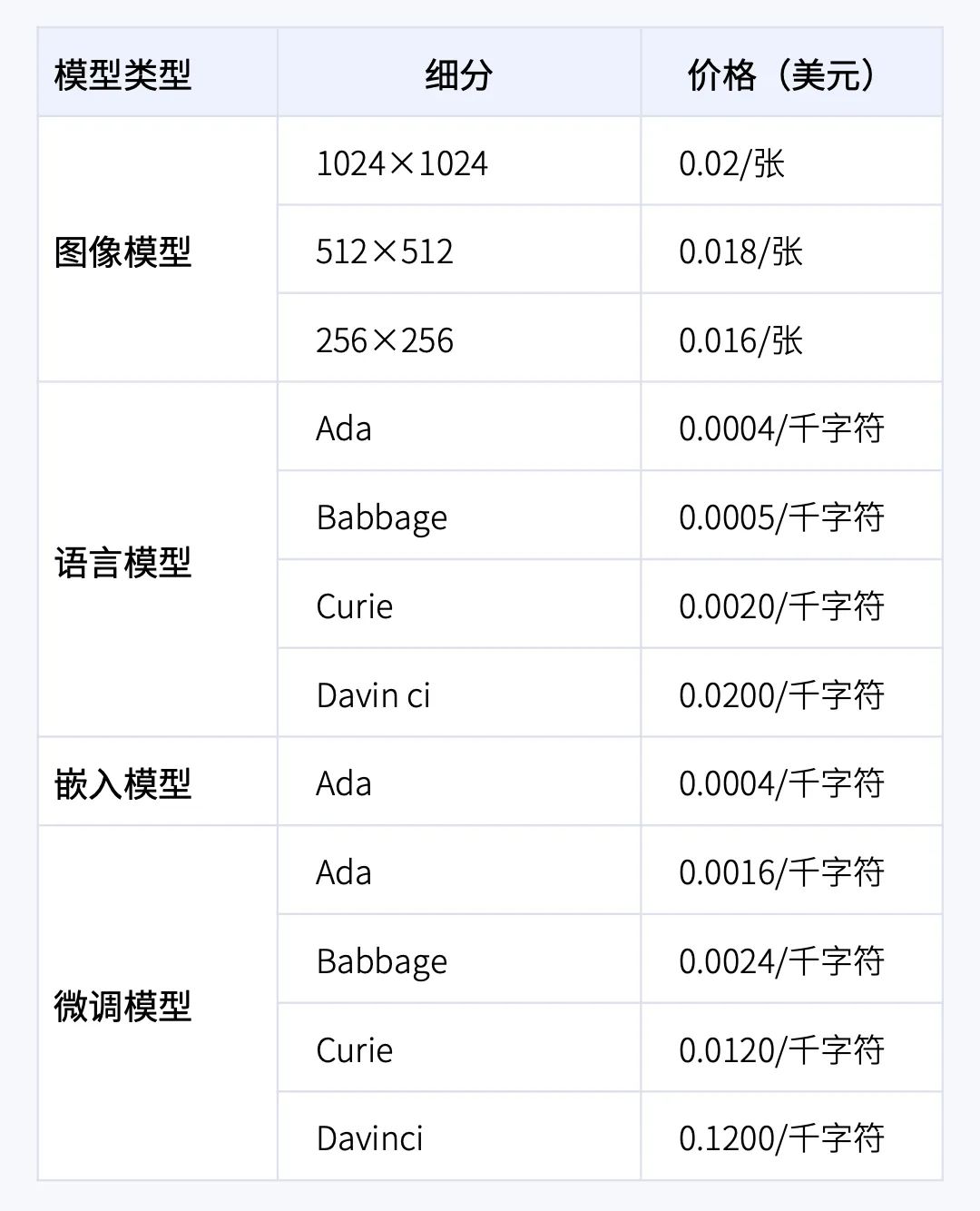
OpenAI API 调用价格
一个大模型,即使像 ChatGPT 一般有惊艳的表现、足够的通用性,也无法用来解决所有问题。从新技术的诞生,到可用的行业产品,再到后续的运营和用户服务,还需要很多下游应用企业结合行业场景来进行微调和开发,形成「整体产品」方案。
Jasper 就是这样一家基于 GPT-3 API 的生成式 AI 公司,提供电商、广告、博客等场景下营销文案、种草文案的自动生成服务,以及后续的搜索引擎优化工具。2022年,Jasper 募资 1.25 亿美元,估值达 15 亿美元。
再比如 Notion,接入 GPT-3 API 后,在文档工具中实现了自动续写、翻译、语法检查等功能。
即便是基于垂直行业的语料库对模型进行微调,也需要不小的研发成本:GPT-3 的每一次升级和迭代,这些下游企业也要跟进调整,需要一定的财力支撑。
国内关于ChatGPT概念的不少公司也拿到投资,而且类似文本生成、图像生成、音频生成、视频生成、虚拟人、元宇宙等场景在中国的落地能力,也许会跟海外同步,甚至更快。
不过,目前的大模型,更多偏向于单点式的应用,优化生产环节中的某一个小问题,并未带动整个工作流的革新。
第一次工业革命,蒸汽机实现了机器替代人工;第二次工业革命,电力技术驱动了规模化生产。之所以能够被称之为「工业革命」,都是因为技术为生产力带来了质的提升。目前来看, AI 原生产品还没有能够大范围囊括某一领域的工作流,并且提供完整解决方案。
03 冲击会抵达哪里?
如同过去所有新的生产力工具一样,ChatGPT 问世以来,关于它会冲击哪些行业的讨论不绝于耳。
作为当今最为先进「统计语言模型」,ChatGPT 在问答和对话上的表现出色。它能够模仿人类的交互方式,提供和整合信息,从而辅助创意和决策。
ChatGPT 有效缩短了「信息→决策」的路径,受到其影响最大的,是与「满足信息需求」有关的生意,尤其是帮助「人找信息」的生意。
其中无法回避的,首当其冲就是搜索引擎。因为很多人认定,基于ChatGPT有可能诞生出比 Google 更出色的搜索引擎。
ChatGPT已经明确回答,它不会替代搜索引擎。实际上,比起功能替代,未来的信息搜索应当是两者的结合。
ChatGPT 的优势在于,它可以综合生成更为完整、拿来即用的答案,还可以通过多轮对话回答后续问题,但我们无法忽视它的硬伤——真实性和逻辑性问题。
首先,ChatGPT生成的答案中难以避免地出现事实性错误。按照既定的语言模型和规则,ChatGPT 可以生成相应的文本,却无法自查自纠;且生成的序列越长,出现错误引用的概率也会随之增加。这也就是为什么谷歌 Bard 言之凿凿地说詹姆斯·韦布空间望远镜拍摄了太阳系以外的行星的第一批照片(实际并非如此),微软 New Bing 进行 GAP 的财报分析时引用了许多错误数据。
其次,ChatGPT 虽然很少在语法上犯错,但它在推理(reasoning)任务上的表现不够令人满意,颇有种「数学是语文老师教的」感觉。至少在目前,我们无法指望它能够通晓逻辑、厘清事实。而它通过对话喂给我们的唯一答案,也限制了我们从多处来源交叉验证信息的能力。
朱啸虎就提出警醒,ChatGPT最大的风险是在网上创造出巨量的似是而非的内容,那以后就不仅仅是「物理学不存在了」,如何判断信息的真实性越来越难,熵爆炸式增长。
实际上,较为理想的产品形态是,由 ChatGPT 精选优质信源,拼接为完整答案,并给出引用来源供我们核实。或者在搜索结果页面的基础上,由ChatGPT来总结要点。
除了微软Bing外,初创公司 Perplexity 也尝试结合 ChatGPT 和搜索引擎,做出更智能的信息搜索工具。
Perplexity 的结果展示,包括三个部分:Perplexity(生成的直接答案)、Sources(引用来源)、Related(相关问题)。你还可以在前文的基础上进行追问,获得更聚焦的信息增量。
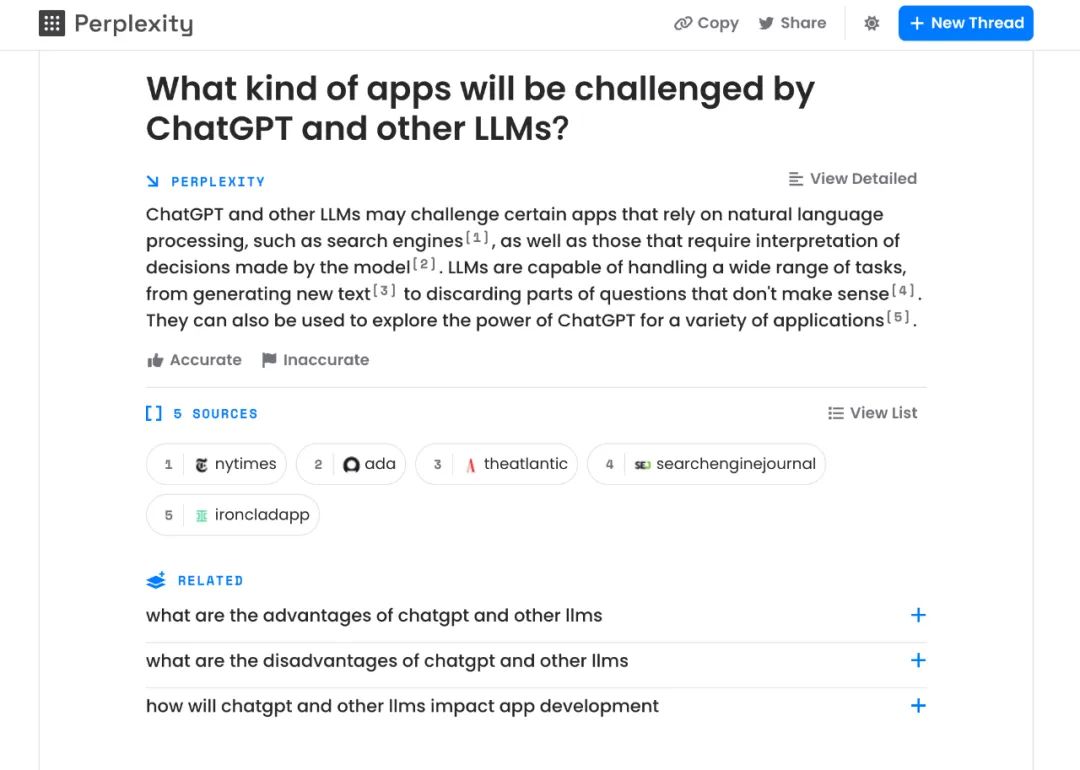
Perplexity产品界面
此类信息搜索产品,若想提供好的使用体验,也需要ChatGPT在未来能够做到「知之为知之,不知为不知」。否则,甄别错误信息的成本将是巨大的,在关键任务中造成的风险也难以估量。
目前,学者们正在琢磨着怎么给 ChatGPT 打上「知识补丁」(Knowledge Patch)。比如问到它拿不准的问题时,它能够输出「抱歉,我不了解」这样谦虚而自知的回答,而不是言之凿凿地胡编乱造。
「所有的行业都值得用AI重做一遍」,技术的进步会带来新的生产力工具,也会带来新的问题。ChatGPT 让我们获取信息变得更容易,同时对我们的判断力提出了更高的要求。客观、理性、全面地分析信息,还是只能靠我们自己。
本文来自微信公众号 “新莓daybreak”(ID:new-daybreak),作者:史圣园,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK