

开挖扩散模型小动作,生成图像几乎原版复制训练数据,隐私要暴露了
source link: https://www.51cto.com/article/746311.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
开挖扩散模型小动作,生成图像几乎原版复制训练数据,隐私要暴露了
去噪扩散模型是一类新兴的生成神经网络,通过迭代去噪过程从训练分布中生成图像。与之前的方法(如 GANs 和 VAEs)相比,这类扩散模型产生的样本质量更高,且更容易扩展和控制。因此,经过快速发展,它们已经可以生成高分辨率图像,而公众也对诸如 DALL-E 2 这样的大型模型产生了极大的兴趣。
生成扩散模型的魅力在于它们合成新图像的能力,从表面上看,这些图像不同于训练集中的任何东西。而事实上,过去大规模的训练工作没有发现过拟合会成为问题,隐私敏感领域的研究人员甚至建议可以用扩散模型来保护隐私,通过生成合成示例来生成真实图像。这一系列的工作是在扩散模型没有记忆和重新生成训练数据的假设下进行的。而这样做将违反所有的隐私保障,并滋生模型泛化和数字伪造方面的许多问题。
本文中,来自谷歌、 DeepMind 等机构的研究者证明了 SOTA 扩散模型确实可以记忆和重新生成单个训练示例。

论文地址:https://arxiv.org/pdf/2301.13188v1.pdf
首先,研究提出并实现了图像模型中记忆的新定义。然后,研究设计了分为两阶段的数据提取入侵(data extraction attack),使用标准方法生成图像,并对一些图像进行标记。研究将该方法应用于 Stable Diffusion 和 Imagen,从而提取了 100 多个几乎相同的训练图像副本,这些图像中,既有个人可识别照片也有商标 logo(如图 1)。

为了更好地理解记忆的方式和其中的缘由,研究者在 CIFAR10 上训练了数百个扩散模型,以分析模型精度、超参数、增强和重复数据删除对隐私的影响。扩散模型是研究评估中私密度最低的图像模型形式,它们泄漏的训练数据是 GANs 的两倍之多。更糟的是,研究还发现现有的隐私增强技术无法提供可接受的隐私 - 效用权衡。总的来说,本文强调了日益强大的生成模型和数据隐私之间存在着紧张的关系,并提出了关于扩散模型如何工作以及如何被妥善部署的问题。
为什么要做这项研究?
理解扩散模型如何记忆和重新生成训练数据的背后存在着两个动机。
第一个是了解隐私风险。重新生成从互联网上抓取数据的扩散模型可能会带来与语言模型类似的隐私和版权风险。比方说,已经有人指出,记忆和重新生成受版权保护的文本和源代码存在着潜在的侵权指标。那么同理,复制专业艺术家创作的图像也会被称为数字伪造,艺术界为此展开了一场争论。
第二个是理解泛化。除了数据隐私,理解扩散模型如何以及为什么记忆训练数据有助于理解它们的泛化能力。例如,大规模生成模型的一个常见问题是,它们令人印象深刻的结果是来自真正的生成,还是直接复制和重新混合训练数据的结果。通过研究记忆,可以提供生成模型执行这种数据复制速率的具体经验描述。
从 SOTA 扩散模型中提取数据
从 Stable Diffusion 中提取数据
现在从 Stable Diffusion(最大、最流行的开源扩散模型)中提取训练数据。
本次提取将先前工作的方法应用于图像,包括两个步骤:
1. 使用标准抽样方式的扩散模型并使用前一节的已知 prompt 生成多个示例。
2. 进行推理,将新一代的模型与已记忆的训练模型相分离。
为了评估入侵的有效性,研究从训练数据集中选择了 35 万个重复次数最多的示例,并为每个提示生成 500 个候选图像(总共生成 1.75 亿张图像)。
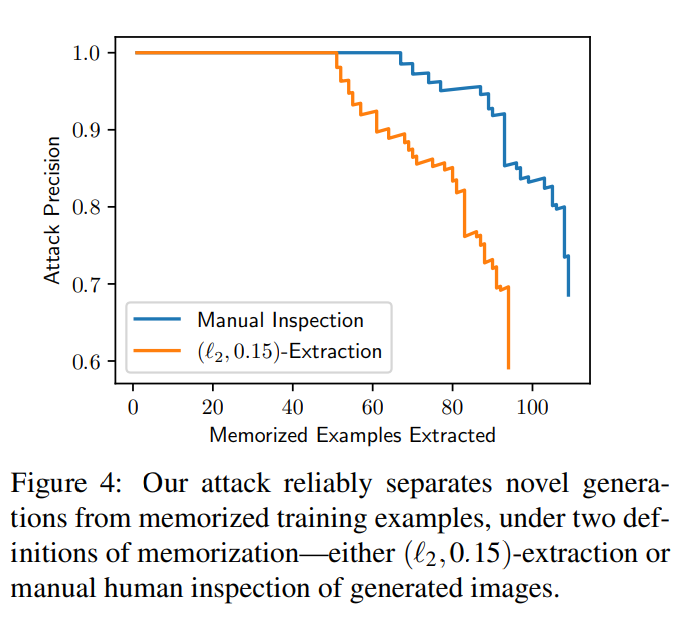
首先,研究对所有这些生成的图像进行排序,以确定哪些是记忆训练数据生成的图像。然后,将这些生成的每张图像与论文中定义 1 下的训练图像进行比较,并将每张图像注释为提取或未提取。研究发现有 94 张图像被提取,为了确保这些图像不仅是符合某些任意的定义,研究还通过视觉分析手动注释了前 1000 张生成的图像,这些图像要么是记忆的,要么是没有记忆的,并且发现另外 13 张(总共 109 张图像)几乎是训练示例的副本,即使它们不符合研究 L_2 范数定义。图 3 显示了提取图像的子集,这些图像以近乎完美像素的精度再现。

实验还给出了在有给定带注释的有序图像集的情况下,计算曲线,评估提取的图像数量与入侵的假阳性率。入侵异常精确:在 1.75 亿张生成的图像中,可以识别出 50 张 0 假阳性的记忆图像,并且所有的记忆图像都可以以 50% 以上的精度提取。图 4 包含了两种记忆定义的精度 - 召回曲线。
从图像中提取数据
尽管 Stable Diffusion 是目前公开可用的扩散模型中最佳选择,但一些非公开模型使用更大的模型和数据集获得了更强的性能。先前研究发现,较大的模型更容易记住训练数据,因此该研究对 Imagen(一个 20 亿参数的文本 - 图像扩散模型)展开了研究。
令人惊讶的是,研究发现在 Imagen 中入侵非分布图像比在 Stable Diffusion 中更有效。在 Imagen 上,研究尝试提取出 500 张 out-of - distribution(OOD)得分最高的图像。Imagen 记忆并复制了其中 3 个图像(这三个图像在训练数据集中是独有的)。相比之下,当研究将相同的方法应用于 Stable Diffusion 时,即使在尝试提取 10,000 个最离群的样本后,也未能识别任何记忆。因此,在复制和非复制图像上,Imagen 比 Stable Diffusion 的私密性更差。这可能是由于 Imagen 使用的模型比 Stable Diffusion 更大,因此记得的图像也就更多。此外,Imagen 在更小的数据集上进行了更多的迭代训练,这也可以有助于提高记忆水平。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK