
3

数据结构-详解优先队列的二叉堆(最大堆)原理、实现和应用-C和Python - LeonYi
source link: https://www.cnblogs.com/justLittleStar/p/17084540.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、堆的基础
1.1 优先队列和堆
优先队列(Priority Queue):特殊的“队列”,取出元素顺序是按元素优先权(关键字)大小,而非元素进入队列的先后顺序。
若采用数组或链表直接实现优先队列,代价高。依靠数组,基于完全二叉树结构实现优先队列,即堆效率更高。一般来说堆代指二叉堆。
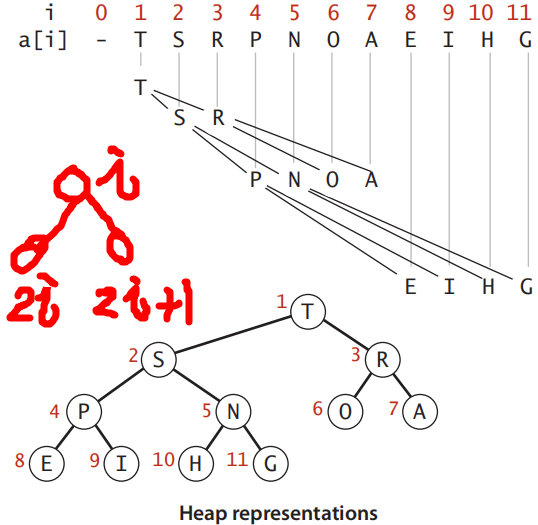
优先队列的完全二叉树(堆)表示。

堆序性: 父节点元素值比孩子节点大(小)
- 最大堆(MaxHeap), 也称“大顶堆”:根节点为最大值;
- 最小堆(MinHeap), 也称“小顶堆” :根节点为最小值。
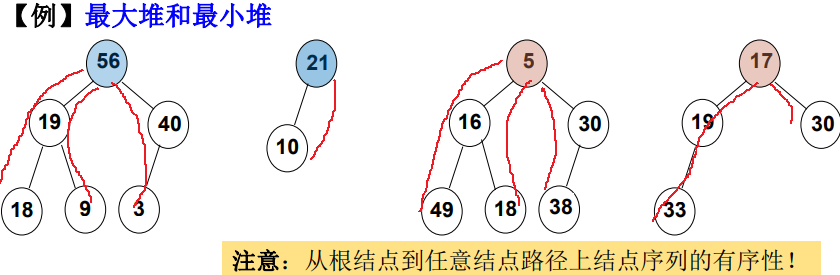
通常以最大堆为例。 最小堆实现,直接把最大堆元素值取负。
二、最大堆实现
2.1 最大堆操作
最大堆(MaxHeap)数据结构实际为完全二叉树,每个结点的元素值不小于其子结点的元素值。
其主要操作有:
- MaxHeap InitializeHeap( int MaxSize ):初始化一个空的最大堆。
- Boolean IsFull( MaxHeap H ):判断最大堆H是否已满。
- Boolean IsEmpty( MaxHeap H ):判断最大堆H是否为空。
- Insert( MaxHeap H, ElementType X ):将元素X插入最大堆H。
- ElementType DeleteMax( MaxHeap H ):返回H中最大元素(高优先级)。
核心操作为恢复堆序性:在堆中执行了可能违反堆序性的简单修改后,需通过修改堆确保重新满足堆序性。有两种情况:
- 自底向上reheapify(上滤,swim): 当某个节点的优先级增加时(或在堆的底部添加一个新节点)时,必须向上遍历调整堆以恢复堆序。
- 自顶向下reheapify(下滤, sink):当节点优先级减少(变小)时(例如,如果用键较小的新节点替换根上的节点),必须向下遍历调整堆以恢复堆顺。
可以先实现这两个基本辅助操作,然后使用它们来实现插入和删除最大值。其操作如下图所示:
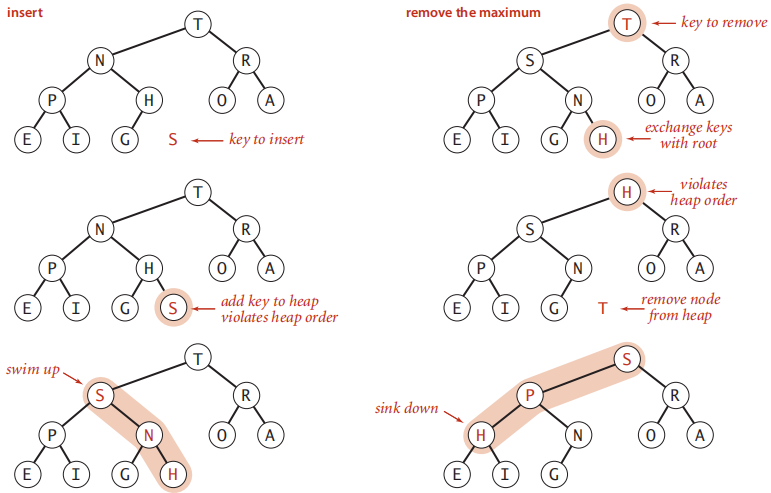
插入-插入元素索引上移,父节点值下移;
删除-孩子节点值上移,末尾元素索引下移(降序插入排序,右边有序,直到找到一个小于它的元素);
2.2 最大堆C实现
2.2.1 基本操作
声明堆结构


View Code
View Code
判是否满堆,以及是否为空
View Code
2.2.2 最大堆的插入
将新增结点插入到,从其父结点到根结点的有序序列中 ( 完全二叉树,插入时间复杂度O(logN) )

一步步往上调整(上滤)
View Code
2.2.3 最大堆的删除
删除位置-根结点,返回堆顶(最大值)元素,并调整堆使其保持堆序性(少了一个元素)。
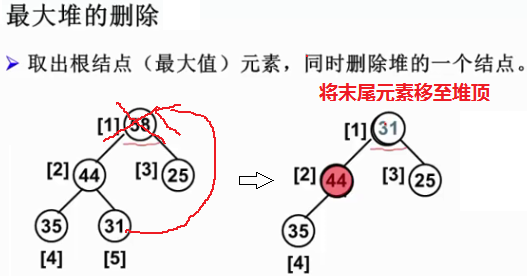
View Code
自顶向下,找到更大的孩子节点(孩子不一定是2个,也可能只有1个),并和末尾元素比较
若孩子更小或等于则不动,若孩子更大则将孩子值上移。末尾元素索引下移-下滤
2.2.4 最大堆的建立
将已经存在的N个元素,按最大堆的要求存放在一个一维数组中
方法1:通过插入操作,将N个元素一个个相继插入到一个初始为空的堆中去,其时间代价最大为O(N logN)。
方法2:在线性时间复杂度O(N)下,建立最大堆。
- 将N个元素按输入顺序存入,先满足完全二叉树的结构特性
- 调整各结点位置,以满足最大堆的有序特性
分析:该如何调整堆?
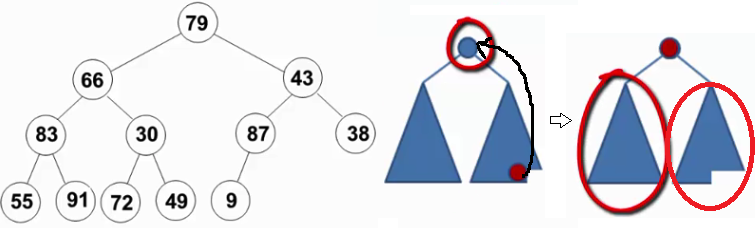
在删除最大值操作中,末尾元素放置于堆顶,此时其左子树和右子树均为堆。其调整思路为,不断地找更大的孩子调上来,自己下沉(下滤操作)。
但是,如上图左子图所示,初始化的堆并不满足堆序性(对79而言,其左右均不是堆,其他节点也是这个情况),似乎不能直接使用删除最大值操作。
实际可以逆向思维,找到最小满足该情况的例子:
从倒数第一个有儿子的节点开始(末尾节点的父亲,此节点的左右肯定是堆-叶节点),逆序执行(自底向上,逆层序遍历)下滤操作。这样当目标节点的左子树和右子树都为堆时,就可以自然地复用删除最大值操作
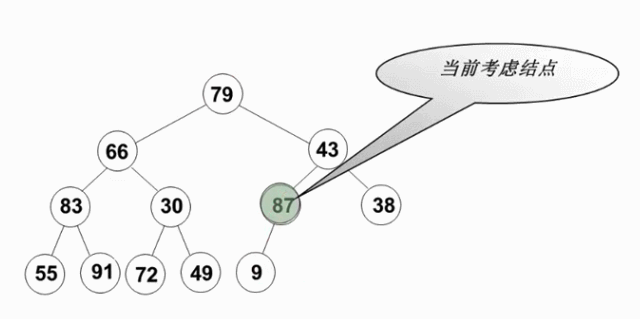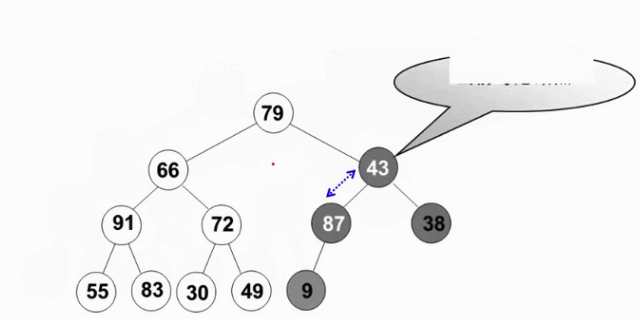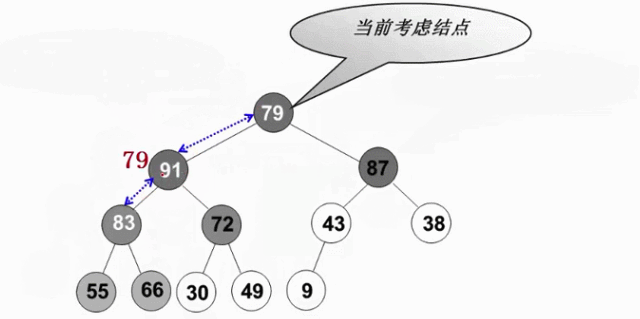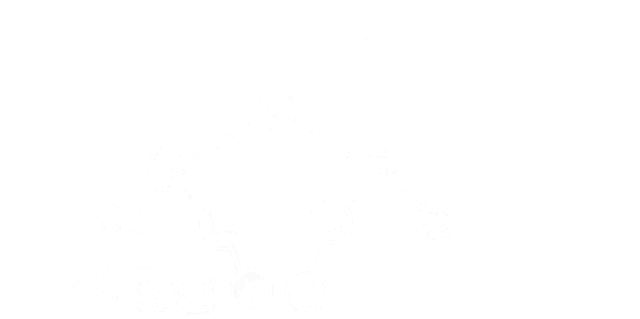
View Code
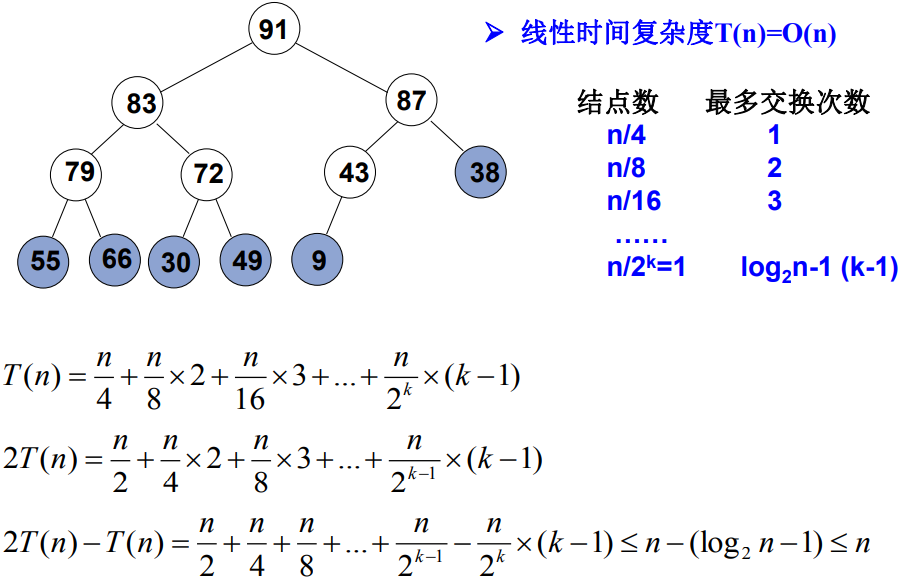
倒数第2层最多交换1次, 其余节点的交换次数此时按其深度线性递增(节点数按2的对数下降)
基于下滤操作的删除最大值实现:
View Code
可知,删除最大值中的调整操作是BuildHeap的特例。此外,还有删除堆中某个元素、增大某个元素的优先级和减小某个元素的优先级的操作。高效执行此操作的前提 ,是用哈希表简历key到index的映射。
2.3 最大堆Python实现
逻辑参照上述C语言版
View Code
调用python包
View Code
三、堆的应用
经典的应用有选择问题、堆排序和Huffman编码等等。
3.1. 选择问题
问题描述:输入N个数,找到第k个最大的数。如果K=N/2,就是找中位数, 这是选择问题的最困难的情况。
暴力法:直接排序,并返回排序数组的倒数第K个数,O(NlogN),
算法A: 大优先队列
- 将N个元素读入数组,并构建最大堆O(N)
- 然后执行K次删除最大元素O(KlogN)
最后一次删除的元素就是第K个最大值,总时间复杂度:O(N + KlogN)。
- 如果k小时,运行时间取决于建堆O(N)。
- 如果k大时,运行时间取决于删除O(KlogN)。例如K=N,即O(NlogN),直接堆排序
- 如果K=N/2,平均时间复杂度(NlogN)
算法B: 小优先队列(流式处理)
- 将K个元素读入数组,并构建最小堆O(K)
- 依次删除最小堆的最小元素,再将元素插入最小堆(把待插入元素放在堆顶,然后下滤)O((N-K)logK)
因此,O(K + (N-K)logK) = O(K(1-logK) + NlogK) = O(NlogK)
3.2 堆排序
- 将N个元素读入数组,并构建最大堆O(N)
- 然后,执行N-1次删除最大元素O(NlogN),返回的元素构成的数组有序
每次删除元素可以放在当前堆尾。慢于希尔排序。
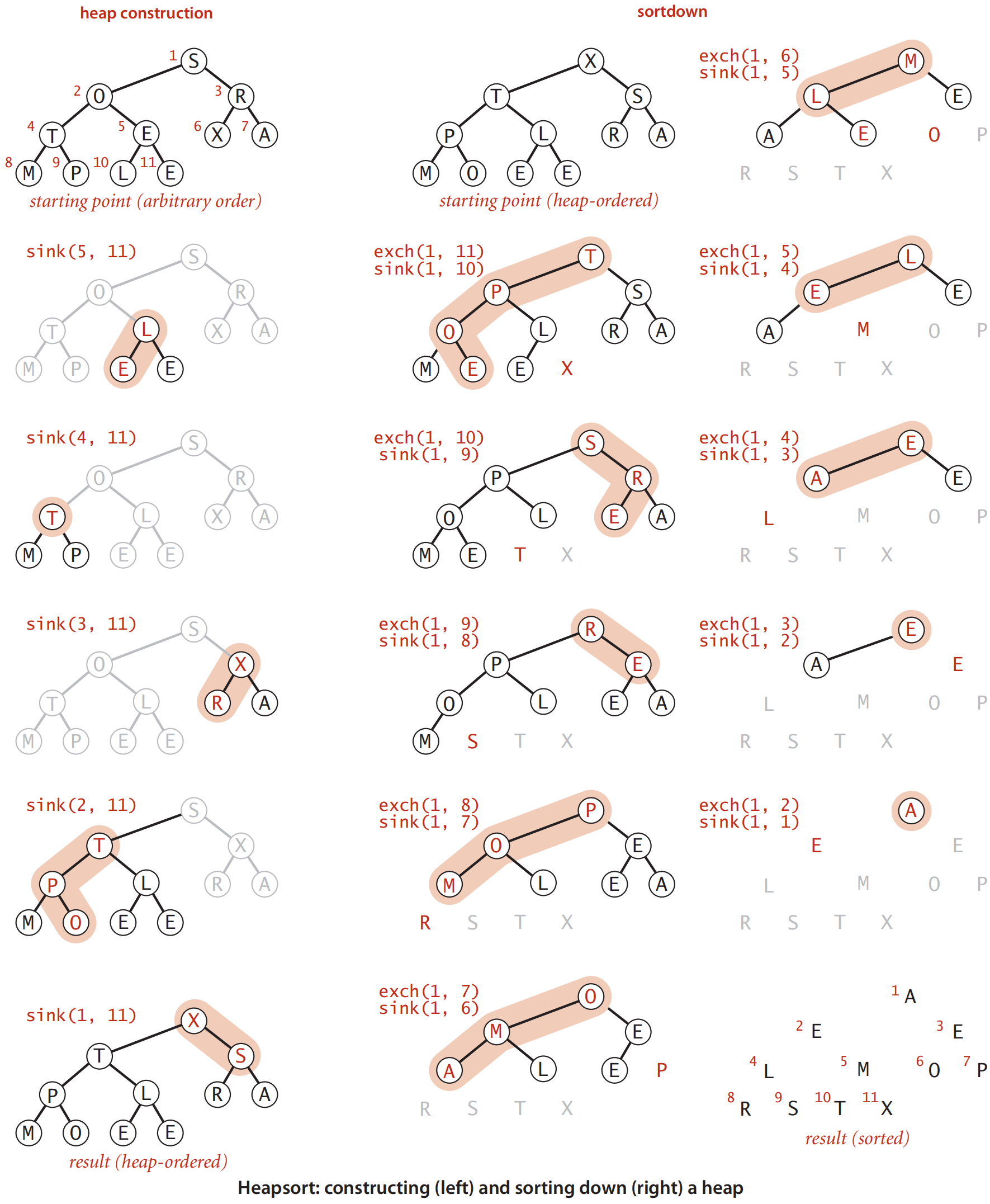
- 实际实现时,先自底向上调用N/2 + 1次下滤操作PercolateDown,线性建堆。
- 然后,每次把堆顶元素和堆末尾元素交换,将堆size减1,并从根节点执行下滤操作PercolateDown。共计N-1次(最后一个元素已经在堆顶,不需要操作)
堆排序不完全同于二叉堆的删除,其数组元素初始位置在0,所以下滤开始位置为0而不是1,下滤范围从N-1到1(实际堆的大小)。
Python调包版
View Code
Python实现
View Code
View Code
参考资料:算法第四版,浙江大学-数据结构慕课
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK