

UE4/UE5 动画的原理和性能优化 - UWA问答 | 博客 | 游戏及VR应用性能优化记录分享 |...
source link: https://blog.uwa4d.com/archives/USparkle_APPO.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
动画在UE4/UE5项目中,往往不仅是GPU和渲染线程开销大户,也是游戏线程的开销大户。按照我的经验,大型游戏项目(尤其是手游)做到中后期,整个项目优化工作做得差不多的时候,你应该也会发现动画的开销会占到整个GameThread的二分之一到三分之二。动画到底是做了什么会产生这么多的开销?项目里关于动画的优化也是最容易扯皮的一件事,开发给美术说要砍资源,减少骨骼数,要减少蒙皮面数,否则游戏跑不动,而美术说骨骼数不够根本做不出好的效果,不能优化。但是为什么骨骼数,蒙皮面数会影响到动画的性能呢?难道除了砍资源之外,就没有别的优化手段了吗?为了回答这些问题,我觉得很有必要说一说动画在虚幻引擎内部的执行流程,最后也会说下我在虚幻引擎动画这块推荐的优化手段。
骨骼动画的本质
UE4/UE5的骨骼动画其实都是通过SkeletalMeshComponent来实现的。这个组件内部会引用到一个SkeletalMesh资源,就像StaticMeshComponent一样,也有一个StaticMesh资源,从资源层面来说SkeletalMesh和StaticMesh的区别就是多了骨骼。Component相对于资源来说,可以理解为对象实例和类的关系,同一个资源可以有很多个Component实例。
直观的来说,一个Mesh想要动起来,那么就需要去对每个顶点做Transform(位移/旋转/缩放),当我们连续做很多帧这样的Transform并按顺序播放,就变成了动画。但是一个几万面的Mesh,在资源层面一帧就要保存几万个Transform,即使引入关键帧,也肯定还会占非常多的空间,因此这个做法明显不现实。那么能想到最直接的解决办法就是对这几万个Transform数据做压缩,把相同的归并在一起。
骨骼这个概念,本质上就是压缩相同顶点的Transform的一种方式。具体来说,就是把Mesh上一部分的顶点和其中一个或多个骨骼做绑定,那么我们只要记录这个骨骼的Transform就好了,这样一个Mesh就被划分成了多个部分,不同部分受不同的骨骼影响。最后计算顶点的实际位置时就只需要让顶点乘以关联的骨骼Transform就可以了。如果顶点是和多个骨骼关联,那么也可以分别乘以不同骨骼的Transform以及受影响的百分比,再求和,就可以得到最终的顶点位置。
进一步来看,如果每个动画都记录全局Transform数组,可能数据量还是会有些大且不规律。骨骼和骨骼之间也可以记录相对的Transform,也就是让每一级都在父级的局部空间内做Transform,这样每一级坐标的范围也会明显变小,而且也很像动物的关节一样一节一节动,比较符合实际情况,骨骼数组就变成了一棵树,当我们记录动画时就会更容易,而计算实际的Transform时,只要递归把所有父级的Transform乘在一起,就得到了最终的Transform。
这个通过骨骼Transform计算出实际顶点的过程,叫做Skin(蒙皮)。而这个骨骼Transform数组,叫做Pose(姿势)。UE4/UE5的SkeletalMeshComponent,其实就是把美术做的多个动画原始的Pose资源(AnimSequence),通过动画蓝图做混合,得到最终的一个Pose,再根据这个Pose做蒙皮求得每个顶点实际位置并绘制的过程。
具体来说,就是下面这两个步骤:
- 先在游戏线程中TickComponent求得当前帧的最终Pose
- 再在渲染线程中根据最终Pose做CPUSkin或GPUSkin算出顶点信息,并进行绘制
当然上面这些过程描述只是我自己的理解,从细节上来看可能不那么专业,这里只要大致理解原理,重点知道这两个步骤就好。
动画的执行流程
GameThread
先来说第一个步骤,在GameThread上,每帧主要是通过TickComponent来执行的。当然这个类里也有一些其它的Tick函数,比如布料和物理动画有单独的Tick函数,开启对应功能后才会Tick,这里就不细说了。
因此可以简单说,想要优化动画的GameThread性能,其实就是要减少TickComponent函数的耗时。我们也知道蓝图里的动画蓝图节点数量以及路径的多少和复杂程度也会直接影响到动画的效率。那么只要搞清楚TickComponent里面到底干了什么,是怎么驱动动画蓝图节点执行的,我们就可以做一些针对性优化了。
下面就是我整理出来的一帧,从TickComponent到动画节点的时序图:
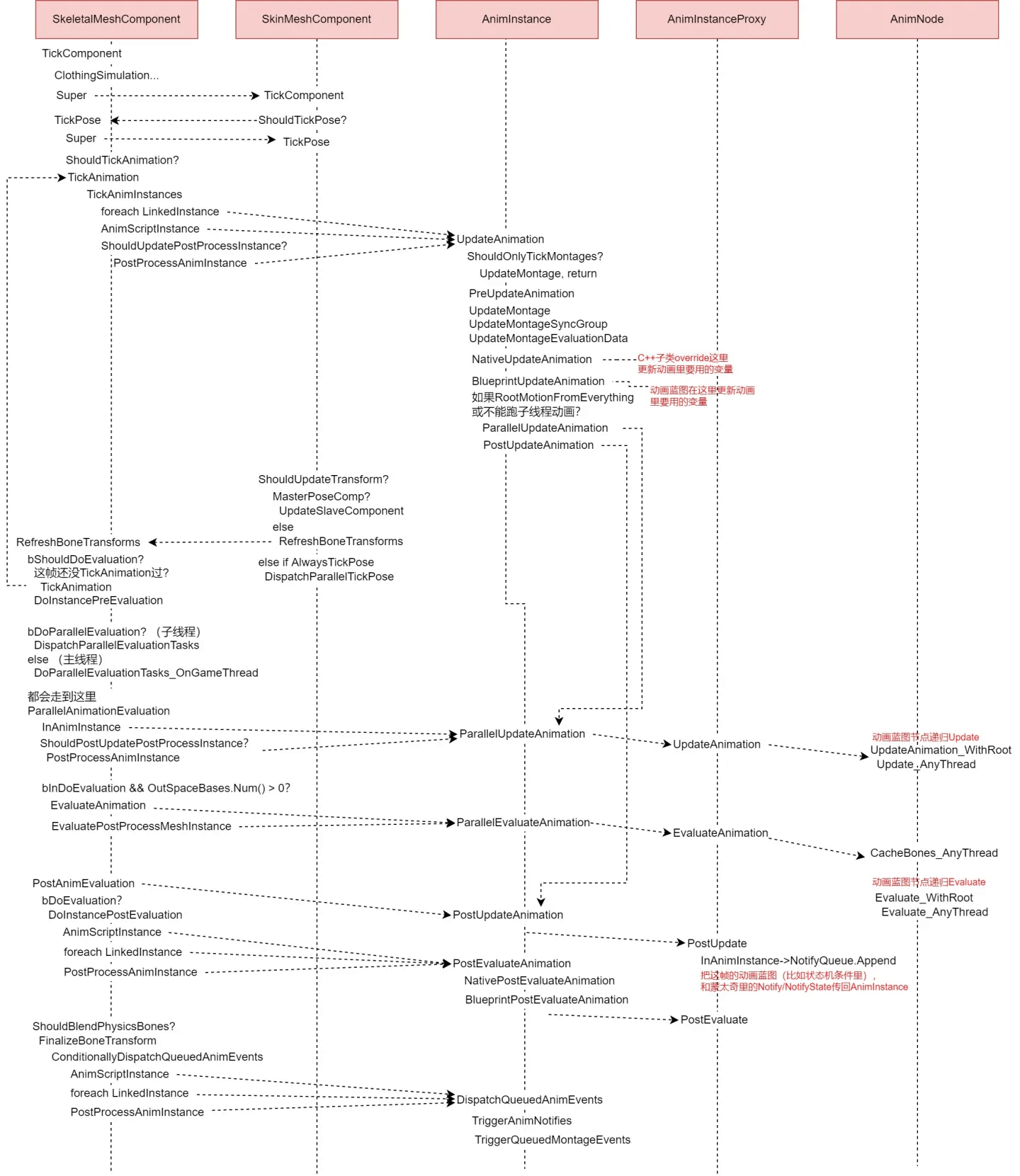
可以看到,完整的动画Tick主要分了几个大块,一开始先在GameThread更新动画蓝图里面的变量。然后根据情况在子线程或GameThread去Update,Evaluate,最后再回到GameThread去通知Notify/NotifyState。
如果有物理动画,还会在EndPhysics时调用EndPhysicsTickComponent,将物理的结果和动画做Blend,这部分不细说。当然还有关于URO的一些跳帧函数,为了简单起见我也没有画出来。
上图中比较关键的两个步骤:UpdateAnimation,EvaluateAnimation是递归调用动画蓝图里面的节点的Update,Evaluate。
- UpdateAnimation:主要作用就是用DeltaTime更新动画进度,算权重以及计算动画蓝图执行路径(动画蓝图里各种Blend节点),让每个执行到的节点更新内部的成员变量。
- EvaluateAnimation:根据前面算的权重或路径,解算实际的Pose,其实就是求每根骨骼这一帧最终的Transform值。
这两个步骤,是可以放在子线程的。
RenderThread
然后再来说说SkeletalMeshComponent渲染线程做的事情。其实和静态网格或其它可绘制的SceneComponent一样,在渲染线程都是通过PrimitiveSceneInfo绘制的,通过SkeletalMeshSceneProxy把GameThread和RenderThread连接起来。
常规的PrimitiveComponent构建渲染信息,其实就是在CreateRenderState_Concurrent里构造SceneProxy和SceneInfo,绘制时会通过调用SceneProxy::DrawStaticElements或者SceneProxy::GetDynamicMeshElements获取对应的Batch。当位置或者资源发生变化时候,Component就通过各种MarkXXXDirty函数来让渲染线程刷新数据。这里细节很多,以后有机会单独再讲。
这里相比于静态网格的绘制,比较关键的是多了一个SkeletalMeshObject这样的结构。这个数据也是在CreateRenderState_Concurrent构建的,本身作为DynamicData传给渲染线程的。在CreateRenderState_Concurrent里可以看到,这个类分成了几个子类,根据情况不同来选择创建,如下图MeshObject。
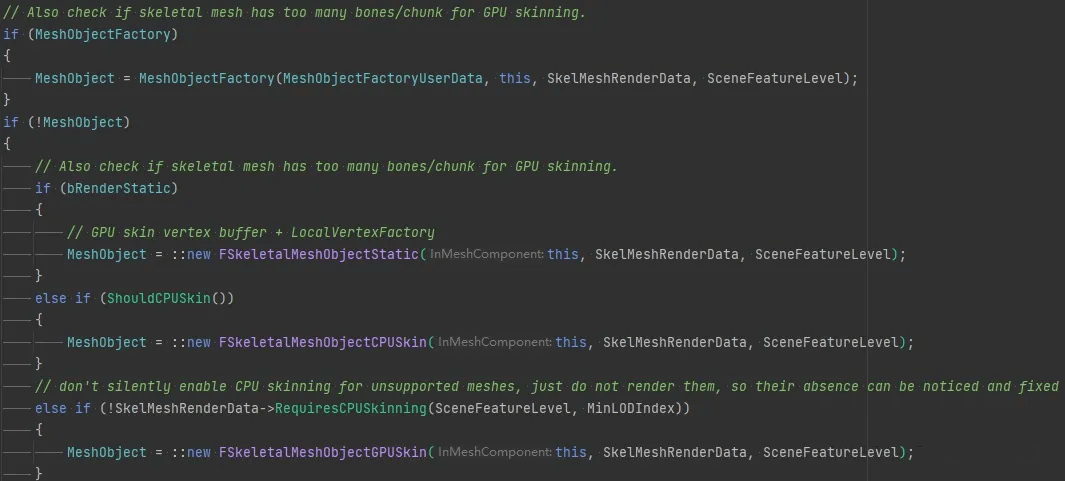
通过名字我们可以知道,这个对象做的就是蒙皮的工作。GPUSkin就是在Shader里做蒙皮,而CPUSkin就是在渲染线程里做蒙皮,另外一个Static,就是把SkeletalMeshComponent当成StaticMeshComponent一样来绘制。
在SendRenderDynamicData_Concurrent里,我们可以看到会调用MeshObject -> Update,这个函数就是把算好的Pose给刷到渲染线程上的,内部流程很长,最终会把骨骼数据存到FDynamicSkelMeshObjectDataGPUSkin的Reference To Local上,当然中间还有一堆MorphTarget,布料之类的数据就先忽略。
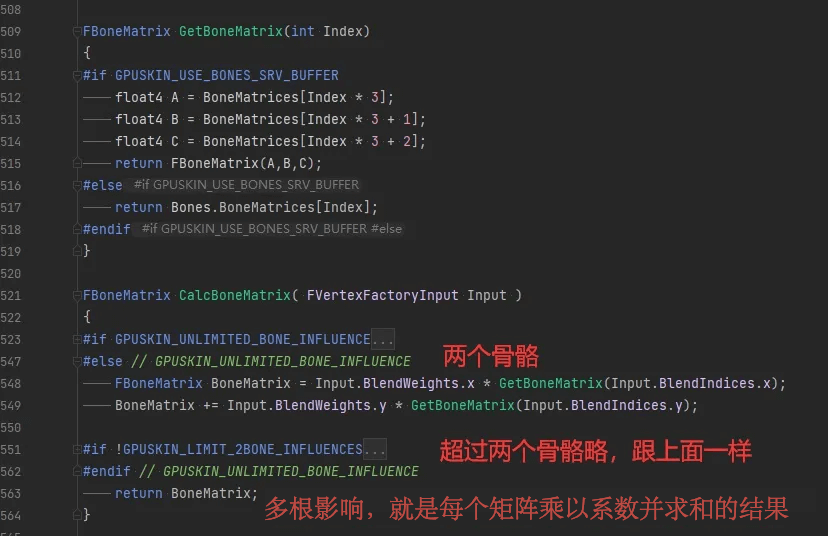
在顶点工厂FGPUBaseSkinVertexFactory的UpdateBoneData函数中,会把上面构造好的Reference To Local传到BoneBuffer上,如果支持SRV这个BoneBuffer就是SRV,否则会用UniformBuffer,超过4个骨骼时候会额外带个BlendIndicesExtra和BlendWeightsExtra。然后在着色器代码GpuSkinVertexFactory.ush里下面这两个函数可以看到蒙皮的做法,就是把每个骨骼的Transform乘以对应权重并求和,如下图,可以看到GetBoneMatrix里的宏根据是否支持SRV来从不同Buffer里获取实际的骨骼矩阵数据。
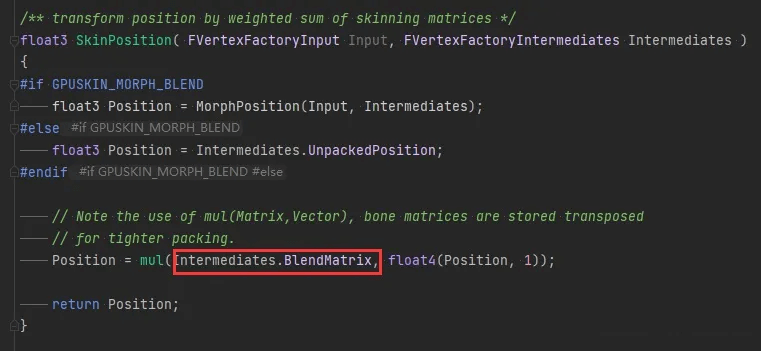
计算顶点位置时候,就乘以刚才算的那个最终的骨骼矩阵,就是当前帧实际的顶点位置,如下图:
CPUSkin本质一样,只不过把前面CalcBoneMatrix放到了渲染线程C++代码里,这里就不细说了。
优化
整个流程通了,就可以来具体说说动画的优化了,我们只要围绕整个流程中每个步骤做针对性优化就可以。下面就是一些具体做法:
1.将UpdateAnimation和EvaluateAnimation放到子线程上面去,这样相当于转移了游戏线程的开销。但是如果动画蓝图本身很复杂,游戏线程还是会空等的。当然动画蓝图里面的节点也要尽量搞成FastPath,这个不用细说了就是常规做法。UE5也已经支持了动画蓝图里面在子线程更新变量,基本可以让事件图表什么都不做或只做很简单的事情,这样游戏线程在动画更新前基本上可以做到没开销。
2.根据情况可以减少动画蓝图里的Notify/NotifyState。从流程可以看到,动画通知都是等到动画从子线程回来后才在GameThread做的,这些通知也是通过遍历的时候触发,如果通知回调的逻辑非常复杂,那么这块的开销也一定会很重,当然这个优化也要根据Stat数据来看。
3.尽量不要用RootMotion,从流程上也可以看到RootMotion可能会影响到是否能在子线程上执行,要用也最多只用蒙太奇的RootMotion。另外本身RootMotion也会有一些网络同步的问题。
4.开启URO。上面流程里虽然没说,但其实这个功能非常关键且效果非常明显,尤其是高帧率模式的游戏不开URO可能都跑不到目标帧率。URO其实是让动画可以跳帧,远处的屏占比比较低的动画更新频率低一些,这样可以显著节省Tick的开销。当然更推荐结合官方的动画预算分配器插件来使用,可以规划好每帧动画固定的预算,根据重要度来动态调整URO甚至关闭Tick。另外需要注意的是,这个优化是有损体验的,但是却是效果最显著的做法。
5.从流程上来说,动画Tick也分为下面这几种选项:
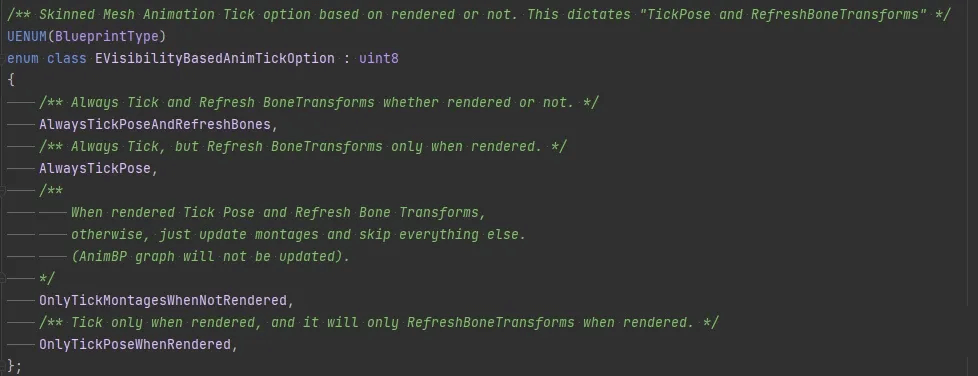
可以考虑将这个选项切换成下面几种。最后一个OnlyTickPoseWhenRendered最省,第一个AlwaysTickPoseAndRefreshBones最耗。中间两个稍微有些区别,OnlyTickMontagesWhenNotRendered在不渲染的时候只调用Update,而不Evaluate。
6.如果单个动画本身不怎么耗,但是量非常大且很多实体基本是一样的,可以考虑做一些公用的SkeletalMeshComponent,然后真正的实体去CopyPose来避免内部动画的计算。官方也提供了一个动画共享插件,专门做这件事的,本身原理也是通过CopyPose来实现。
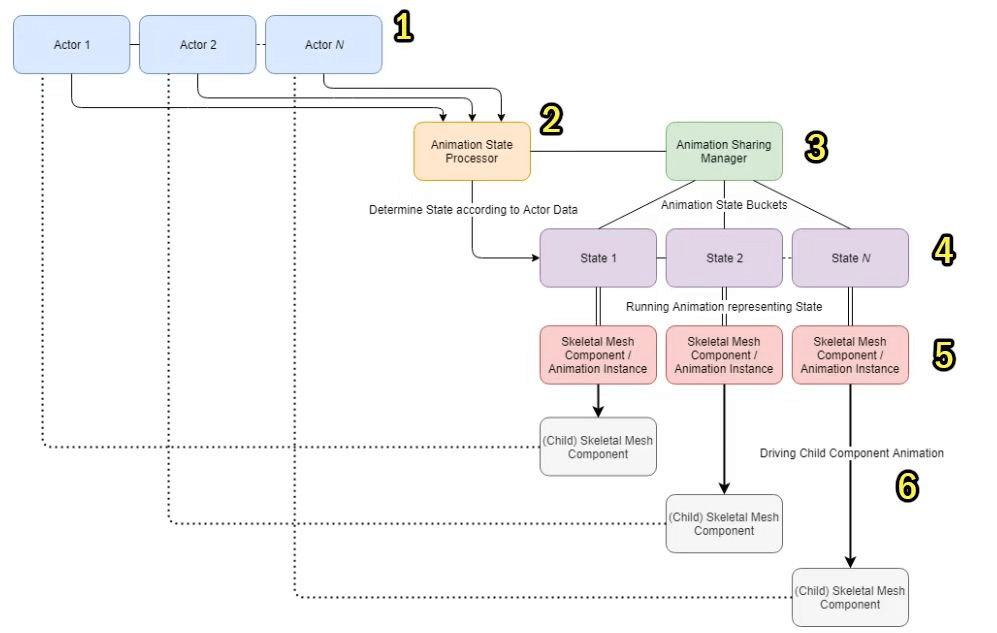
7.从动画本身来说,也尽可能让动画蓝图做得简单一些,尽量让最经常运行的那条路径短一些。也可以继承AnimInstance并封装或合并一些计算的函数。
8.如果GPU没压力,CPU压力很大,动画又比较简单,可以考虑烘培顶点动画,具体做法可以参考我之前的一篇,即使不用MassAI也能单独拿出来用:
这个做法虽然合了Instance,但不支持BlendPose。如果能改源码也可以考虑自己做个ComputeShader来实现简单的混合,不过因为有回写,用CS做Blend在手机上也有可能是负优化。
9.从资源层面入手,让美术砍掉多余的骨骼以及减面,也会有一些效果,但是也得具体情况具体分析,因为虚幻引擎本身对面数不敏感,美术对于减骨骼和减面可能拉扯几个月也就抠出来一点点,大部分情况这个操作不会起很大作用。当然资源也不要做的太离谱,比如做了个千足蜈蚣这样的怪物,每条腿都有好几节骨骼,这种情况就只能砍资源了,再从其它方面优化也不会起作用的。
10.如果SkeletalMeshComponent是动态挂载动画、网格这些资源的,也包括动态Link Layer,要考虑将这些额外的资源做异步加载,不要出现游戏线程Flush资源的操作。
11.每个动画节点都有个Initialize_AnyThread函数,默认会在InitAnim里触发。尤其是上面第10点这些动态挂载的操作,一定会频繁触发到这些初始化。如果能改源码,可以考虑将初始化屏蔽,第一次执行Update_AnyThread的时候再调用,这样平时跑不到的节点就任何开销都没有了,当然这里改的时候也有不少细节需要注意,可能会引起崩溃,改完要多测。
12.如果有Cosmetics这种换装系统,一个Mesh上挂的组件太多了也会造成很大开销。可以考虑在玩家换完装备的时候,通过USkeletalMergingLibrary的Merge功能,将多个基于同样骨架的SkeletalMesh合并成一个Mesh,这样也能省掉多个组件的Tick开销。这个合并资源的操作也可以在运行时做,相当于用内存换CPU。如果能改源码,也可以将这个工作放在子线程上做,不过要注意涉及到UObject的一些操作只能在GameThread做。
这些都是一些我目前能想到的做动画优化时候比较有用的方案,当然实际也不止这么多做法,而且也不见得对每个项目都管用。但是总的来说还是要了解清楚引擎内部的原理,根据实际问题抓性能数据来做针对性分析。
这是侑虎科技第1290篇文章,感谢作者quabqi供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
作者主页:https://www.zhihu.com/people/quabqi
再次感谢quabqi的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK