

"AI问诊就是抛硬币"!甚至漏掉67%病患,Nature都看不下去了 | 量子位
source link: https://www.qbitai.com/2023/01/41329.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
“AI问诊就是抛硬币”!甚至漏掉67%病患,Nature都看不下去了

对可重复性提出了质疑
詹士 Alex 发自 凹非寺
量子位 | 公众号 QbitAI
“AI的一些医疗决策,实际上就是抛硬币。”
哈佛医学院的数据科学家Kun-Hsing Yu语出惊人。
他还补充道:
即便比赛中正确率达90%的获奖模型,再用原数据集子集测试时,准确度最多60-70%,可谓惨败。这让我们很惊讶。

上述科学家的观点来自Nature最近新发表的一篇文章。
内容对AI在医疗领域的可重复性提出了质疑,呈现诸多医疗领域及场景中,AI自带的黑箱属性造成的隐患。
更值得关注的是,尽管问题存在,但AI仍在医疗领域大规模推广使用。
举例来看,数以百计的美国医院已在使用一种AI模型标记败血症早期症状,但在2021年,该模型被发现未能识别率高达67%。
所以,AI究竟带来了哪些医疗隐患,如何解决?
继续往下看。

△ 图源:Nature
人工智能的“看病难”
我们先从哈佛医学院的数据科学家Kun-Hsing Yu发现AI“抛硬币”的始末聊起。
在医疗领域,AI用于诊断检测人体一直质疑声不断,Kun-Hsing Yu此番研究也是希望有个直观体感。
他选定了常见癌症之一的肺癌,每年有350万美国人因该病症去世,若能更早通过CT扫描筛查,很多人可以免于死亡。
该领域的确备受机器学习界关注,为此,2017年业内还举办了面向肺癌筛查的竞赛。

该活动归属于Kaggle的Data Science Bowl赛事,数据由主办方提供,涵盖1397位患者的胸部CT扫描数据。参赛团队需开发并测试算法,最终大赛按准确率给予评奖,在官宣中,至少五个获奖模型准确度90%以上。
但Kun-Hsing Yu又重新测试了一轮,然后震惊地发现,即便使用原比赛数据的子集,这些“获奖”模型最高准确率却下降到了60-70%。
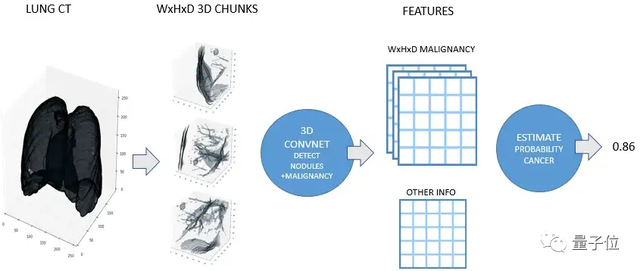
△ 一位参赛者分享的模型结构
上述状况并非个例。
普林斯顿一位博士,Sayash Kapoor,在17个领域的329项研究中报告了可重复性失败和陷阱,医学名列其中。
基于研究,这位博士及自己的教授还组织了一个研讨会,吸引了30个国家600名科研者参与。
一位剑桥的高级研究员在现场表示,他用机器学习技术预测新冠传播流行趋势,但因不同来源的数据偏差、训练方法等问题,没有一次模型预测准确。还有一位研究者也分享了——自己用机器学习研究心理课题,但无法复现的问题。
在该研讨会上,还有参与者指出谷歌此前遇到的“坑”。
他们曾在2008年就利用机器学习分析用户搜索所产生数据集,进而预测流感暴发。谷歌为此还鼓吹一波。
但事实上,它并未能预测2013年的流感暴发。一家独立研究机构指出,该模型将一些流感流行无关的季节性词汇进行了关联和锁定。2015年,谷歌停止了对外公开该趋势预测。
Kapoor认为,就可重复性来说,AI模型背后的代码和数据集都应可用并不出错误。那位研究新冠流行模型的剑桥ML研究者补充道,数据隐私问题、伦理问题、监管障碍也是导致可重复性出问题的病灶。

他们继续补充道,数据集是问题根源之一。目前公开可用的数据集比较稀缺,这导致模型很容易产生带偏见的判断。比如特定数据集中,医生给一个种族开的药比另一个种族多,这可能导致AI将病症与种族关联,而非病症本身。
另一个问题是训练AI中的“透题”现象。因数据集不足,用于训练模型的数据集和测试集会重叠,甚至该情况一些当事人还不知道,这也可能导致大家对模型的正确率过于乐观。

△ Sayash Kapoor博士
尽管问题存在,但AI模型仍已被应用在实际诊断场景中,甚至直接下场看病。
2021年,一个名为Epic Sepsis Model的医疗诊断模型被曝出严重漏检问题。
该模型用于败血症筛查,通过识别病人早期患病特征检测,避免这种全身感染的发生,但密歇根大学医学院研究者通过调查分析了27697人的就诊情况,结果发现,该模型未能识别67%败血症病患。
此后,该公司对模型进行了大调整。
一位计算生物学家对此指出,该问题之所以较难解决,也同AI模型透明度不足有关。“我们在实践中部署了无法理解的算法,也并不知道它带什么偏见”,他补充道。

△ 曝出Epic Sepsis Model问题的文章
可以明确的是,只要上述问题一直未能解决,商业巨头及相关创业项目也有些举步维艰——
去年谷歌谷歌健康(Google Health)宣布人员拆分到各团队,前几天,谷歌孵化的生命健康子公司Verily又被曝裁员约15%。
有没改进措施?
对于这样的现状,一些研究者和业内人士也在着手改进医疗AI。
一方面,是构建靠谱的超大数据集。
涵盖机构、国家和人口等多方面的数据,并向所有人开放。
这种数据库其实已经出现了,比如英国和日本的国家生物库,以及重症病房远程监护系统eICU合作的数据库等。
就拿eICU合作研究数据库来说,这里面大约有20万次的ICU入院相关数据,由飞利浦医疗集团和MIT的计算生理学实验室共同提供。
为了规范数据库的内容,需要建立收集数据的标准。例如一个关于医疗结果伙伴关系的可观测数据模型,让各医疗机构能以相同的方式收集信息,这样有利于加强医疗保健领域的机器学习研究。
当然,与此同时,也必须重视严格保护患者的隐私,而且只有当患者本人同意时,才有资格把他们的数据纳入库。
另一方面,想要提升机器学习质量的话,消除冗余数据也很有帮助。
因为在机器学习中,冗余数据不仅会延长运行时间、消耗更多资源;而且还很可能造成模型过拟合——也就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差。
对于AI圈很热门的预测蛋白质结构,这个问题已经得到了有效缓解。在机器学习过程中,科学家们成功地从测试集中删除了和训练集用到的过于相似的蛋白质。
but,各病人医疗数据之间的差异,并没有不同蛋白质结构差异那么明显。在一个数据库中,可能有许许多多病情非常相似的个体。
所以我们需要想清楚到底向算法展示什么数据,才能平衡好数据的代表性和丰富性之间的关系。
哥本哈根大学的转化性疾病系统生物学家Søren Brunak如是评价。
除此之外,还可以请行业大佬们制定一个检查表,规范医疗AI领域的研究开发步骤。
然后,研究人员就能更方便地搞清楚先做什么、再做什么,有条不紊地操作;还能Check一些可能遗漏的问题,比如一项研究是回顾性还是前瞻性的,数据与模型的预期用途是否匹配等等。
其实,现有已有多种机器学习检查表,其中大部分是基于“EQUATOR Network”先提出的,这是一项旨在提高健康研究可靠性的国际倡议。
此前,上文提到的普林斯顿的Kapoor博士,也和团队共同发表了一份包含21个问题的清单。
他们建议,对于一个预测结果的模型,研究人员得确认训练集中的数据要早于测试集,这样可以确保两个数据集是独立的,不会有数据重叠和相互影响。
参考链接:
[1]https://www.nature.com/articles/d41586-023-00023-2
[2]https://www.wired.com/story/machine-learning-reproducibility-crisis/
[3]https://mp.weixin.qq.com/s/TEoe3d9DYuO7DGQeEQFghA
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK