

真正“搞”懂HTTP协议04之搞起来 - Zaking
source link: https://www.cnblogs.com/zaking/p/16867636.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
前两篇文章,我们从空间和时间的角度都对HTTP有了一定的学习和理解,那么基于上一篇的HTTP发展的时间顺序,我会在后面的文章由浅入深,按照HTTP版本内容的更迭,一边介绍相关字段的使用方法,一边讲解其特性和目的,并和大家一起手写测试代码,学以致用。
当然在真正进入时间线之前,我们还还需要一些前置内容,本篇呢,会先带大家去手写一下HTTP的一个小栗子及相关配置修改方式。然后我还会根据测试的HTTP请求带大家先熟悉一下HTTP的基本内容。
这就是本篇的所有内容啦~本来还想把HTTP的特点和方法也写进来,但是觉得篇幅可能会太长,所以还是另起一篇吧。
一、一个小的不能再小的小栗子
其实这个小栗子的代码十分简单,我们主要使用Node来作为服务器端。然后还需要修改一下下本地的Hosts文件。废话不多说,想必大家的大刀都饥渴难耐了吧,啊哈哈哈哈。
我们先来把测试代码写好,简单的一批,我是直接从Node官网的文档的首页直接复制下来的:
const http = require("http");
const hostname = "127.0.0.1";
const port = 8080;
const server = http.createServer((req, res) => {
res.end("Hello Zaking World!This is Node");
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
这段代码十分简单哈,就是启动个服务,然后服务器返回一段字符串就完事了。然后我们直接在命令行中执行这段代码的文件:
node ./server.js
嗯,你可以看到这个文件的文件名叫做server。启动成功后,我们直接打开浏览器在地址栏输入http://127.0.0.1:8080/,就可以直接看到浏览器中显示出了结果:
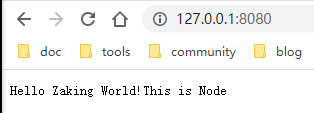
很顺利,很完美~到了这一步,其实你已经完成并体验了HTTP/0.9的所有内容。Get请求,返回字符串。但是现在还只是通过本地的ip来访问我们启动的服务,我们要在本地模拟一下域名,直接通过域名来访问我们启动的Node服务,实验一下Get请求。
首先,我们找一下本机的hosts文件。Windows的hosts文件在这里:C:\WINDOWS\system32\drivers\etc\hosts。你可以直接复制下来在windows里搜索,注意保存的时候需要管理员权限,而mac的地址则是在这里:/etc/hosts。可以通过命令行:open /etc/hosts打开后修改,也可以直接找到文件后修改。你可以在hosts中加一行,修改成这样:
127.0.0.1 www.zaking.com
然后,别忘了用管理员权限保存一下,我们直接打开浏览器,输入www.zaking.com:8080。当然,这个域名你可以随便起,就是本地自己玩嘛。我们可以看到浏览器同样获取到了我们想要的内容:
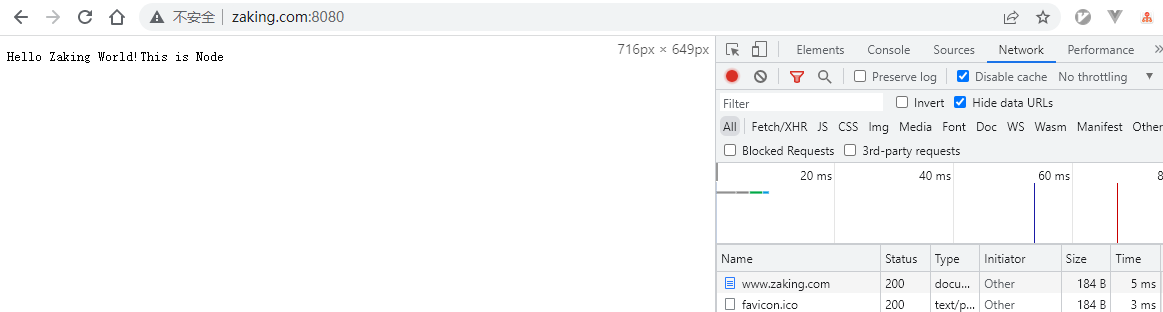
为什么我们加了hosts的配置之后,就可以在本地通过域名来访问我们启动的服务了呢?其实简单来说,就是域名解析的过程。当浏览器访问www.zaking.com的时候,发现这不是一个ip那就肯定是域名了,于是会尝试去访问一系列的域名服务器,把这个域名转换成ip,但是由于整个域名解析的体系实在是很复杂,如果每次都去访问服务器确定域名对应的ip,那实在是慢死了。于是为了解决慢的问题,就出现了缓存,当浏览器尝试去获取对应域名的ip的时候,会先去浏览器自己的缓存里看看有没有这个域名的IP,没有就去操作系统里找,再没有,就会去检查本机的域名解析文件,也就是hosts,于是,找到了就直接转换成这个对应的ip了。
那要是本机没找到呢?那没办法,就得一级一级的去域名服务器找对应的ip啦。
OK,我们的基本例子代码和最最最简单的实验都做完了。接下来的篇章我们都基于这个最简单的例子,去试验各个HTTP的核心重点。
二、HTTP报文的组成
还记得我们在空间穿梭的时候说过,当发送请求的时候,会在HTTP报文的基础上每一层都会加上上一层的头信息,然后当服务器获取,路过各层的时候,会拆下来各层需要的头信息。那HTTP其实也类似,也需要在传输的数据前附加一些头数据。唯一不太一样的是,HTTP的这些头数据,是纯文本,也就是ASCII码,所以这些数据用肉眼就能分辨,不需要借助解析工具。
HTTP协议是基于请求—响应的模型,所以头数据也分为请求报文和响应报文。这两种报文的结构也是基本相同的,都由三大部分组成:
- 起始行(start line):描述请求或响应的基本信息
- 头部字段集合(header):使用key-value的形式更详细的说明报文
- 消息正文(entity):实际传输的数据,不一定只是文本,可能是图片、视频等二进制文件。
看起来好像有点复杂,在通常情况下,我们会把起始行和头字段统一叫做请求头或者响应头,也就是header,而传输的数据就叫做body。这样看起来是不是简单了些。
我还记得我说要按照HTTP的历史时间顺序来讲解HTTP,所以,现在应该讲的是HTTP/0.9,但是HTTP/0.9又太少了,所以我只能把它包含在这里了。
后面,我会按照总分的方式来讲后续的内容,总的就是总体的介绍、比如HTTP的方法、状态码、特点等等,分的部分呢,则是按照时间顺序来讲解头字段。这样,体系就清晰了。
不多啰嗦啦,我们继续~
一)起始行
起始行这个东西其实有两种叫法,发送请求的起始行就叫做请求行,发送响应的起始行就叫做状态行。我们分别来看下他们的区别。
我们来看张图:
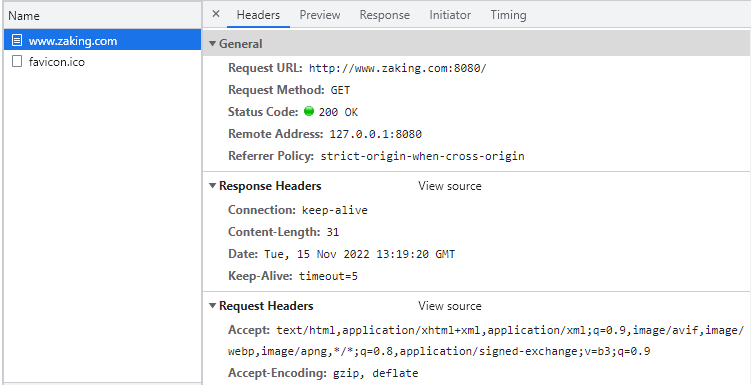
这就是我们上面的基础例子的HTTP请求的详细headers。诶?你这糊弄我呢?你这也没有啥请求行啊,不都是头字段么?糊弄我不懂呢?嗯……你看我后面慢慢给你编,上面这个图先看下就好,咱们每天都接触,不看也行啦。
1、请求行
请求行由三部分构成,分别是:
- 请求方法:通常是一个动词,表示对服务器资源的操作,比如GET、POST等。
- 请求目标:通常是一个URI,标记了目标资源的地址。
- 版本号:表示报文使用的协议版本。
你还记得HTTP的一个描述是:HTTP是使用纯文本传输的,那么在文本中,如何分割各个字段呢?嗯……就是空格,用空格来分割请求方法、请求目标以及版本号,然后,再用一个换行符来作为请求行结束的标记。
我们还是回到之前的例子中:
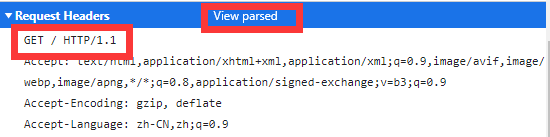
看到跟之前的图有什么区别了吗?这就是请求行原始的样子,而我们上图中看到的是parsed之后的,也就是经过了格式化,让我们看起来更舒服。而source则可以让我们看到报文的原始样子。
而在请求行中,实际上我们要重点关注的就是请求方法,这个我们下一章再说,我们先知道请求行都有哪些内容就好啦。
2、状态行
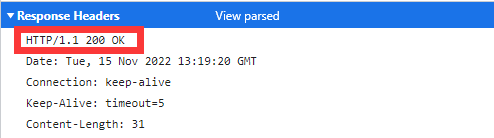
响应报文中的起始行不叫响应行,而是叫状态行,状态行也有三部分:
- 版本号:嗯,就是跟请求行中一样。
- 状态码:一个三位数字,用来表示请求处理的结果,比如200、300、400啥的。
- 原因:作为状态码的补充,就像一个说明。
状态行就像这样:
那你知道为啥响应报文中的起始行不叫响应行了不?重点就在这个状态码,告诉你对于当前请求的处理结果的状态。而状态码和原因则往往是配对出现的。
那么请求中有“方法”,响应中有“状态”。刚好,来回都描述的很完整。
二)头字段
请求行或者状态行再加上头字段,就是完整的请求头或者响应头。请求头和响应头的头字段基本上是一致的,都是一种key-value形式的键值对。但是头字段有以下几点需要注意一下:
- 字段名不区分大小写,Host还是host还是HOST都是一个意思,但是通常我们会首字母大写,便于阅读与理解。
- 字段名里不能出现空格,可以有连字符“-”,但是不能有下划线“_”。
- 字段名后面必须紧跟着“:”,不能有空格,而“:”后面可以随意空格。
- 顺序是无意义的,随便。
- 原则上字段名不能重复,除非本身的语义允许。
HTTP协议规定了好多好多的头字段,甚至我们还可以自定义头字段,但是通常头字段可以分为以下几类:
- 通用字段,请求头和响应头中都可以使用
- 请求字段,当然只能在请求头中用。
- 响应字段,当然只能出现在响应头中。
- 实体字段,其实算是通用字段,往往是为了描述传输的数据的额外的信息。
所以你看,原则上字段的类型就三种,要么只有我能用,要么只有你能用,要么就都能用。
当然,还有一种情况是往往有些字段不是独立出现的,而是有一定的配合~我们后面会详细聊哒。
实体,其实就是我们在使用HTTP的时候传输的数据内容,我们通常把它叫做body,当然,我们也可以通过GET方法来传递一定数据量的信息,0.9就是这样做的,但是毕竟这算不上是“正途”,如果我想要传音频、视频、图片咋整?总不能也用GET请求放在URL的query里吧?
这就需要我们的body了,但是body要怎么传呢?我传给你服务器一个视频文件,但是服务器怎么知道要按照什么样的方式来解析这个文件呢?嗯……可以根据文件的后缀吖,没错,那我要是改了后缀名呢?我就故意改,你能咋整,所以这种方法也不那么靠谱。
然后,其实某一个类型的文件的二进制编码的前面一小部分其实是固定的,我们也可以根据这些固定的数据来判断,但是这样也好像不是那么靠谱,而且还有点低效,还有很大概率查不出来。
那咋整,那就是MIME type,MIME是一个很大的标准规范,HTTP拿取了其中的一部分用来表示body的数据类型。那啥是MIME呢?嗯,它的大名叫做“多用途互联网邮件扩展”(Multipurpose Internet Mail Extensions),本来是给电子邮件用的,目的是为了让电子邮件可以发送出了ASCII码以外的任意数据。
MIME把数据分为了八大类,每个大类下面还有子类,大概是这样的:type/subtype。就很符合HTTP的标准要求,于是就顺手牵羊拿过来了。
在HTTP中常用的大概有text、image、audio/video、application等。最常见的大家也最熟悉的想必就是application/json啦。
至于具体每一个字段的详细解释,我会在后面讲解到对应字段的时候再加以详述。
三、小小结
我们稍稍回顾一下本篇我们都学习了哪些内容。
首先,我带大家完成了一个小小小栗子,看了一下GET请求。
然后,依赖于这个小小小栗子,我们知道了HTTP的组成有哪三部分或者哪两部分。
最后我问大家一个问题:你知道起始行中的重点内容有哪些么?
我们下一篇再见~嘿嘿
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK