

TPU演进十年:Google的十大经验教训
source link: https://blog.csdn.net/OneFlow_Official/article/details/127330386
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
TPU演进十年:Google的十大经验教训

David Patterson,Google杰出工程师、UC Berkeley荣誉退休教授、美国国家工程院、科学院院士、文理科学院“三院”院士。他是RISC(精简指令集计算机)、RAID(独立磁盘冗余阵列)和NOW(工作站网络)的缔造者,他与John Hennessy的著作《计算机体系结构:量化研究方法》在业内久负盛名。
2017年,David Patterson加入Google TPU团队,2018年3月,他与John Hennessy共同获得图灵奖,2008年获ACM/IEEE Eckert-Mauchly 奖(被誉为计算机体系结构最高奖),2000年获得冯·诺依曼奖章。
本文是他近期在加州大学伯克利分校的演讲,他分享了Google TPU近十年的发展历程以及心得体会,并阐述了提升机器学习硬件能效对碳足迹的影响。OneFlow社区对此进行了编译。
作者|David Patterson
翻译|胡燕君、贾川、程浩源
1
一场由TPU引发的“地震”
2013年,Google AI负责人Jeff Dean经过计算后发现,如果有1亿安卓用户每天使用手机语音转文字服务3分钟,消耗的算力就已是Google所有数据中心总算力的两倍,何况全球安卓用户远不止1亿。
如果仅通过扩大数据中心规模来满足算力需求,不但耗时,而且成本高昂。因此,Google决定针对机器学习构建特定领域计算架构(Domain-specific Architecture),希望将深度神经网络推理的总体拥有成本(TCO)降低至原来的十分之一。
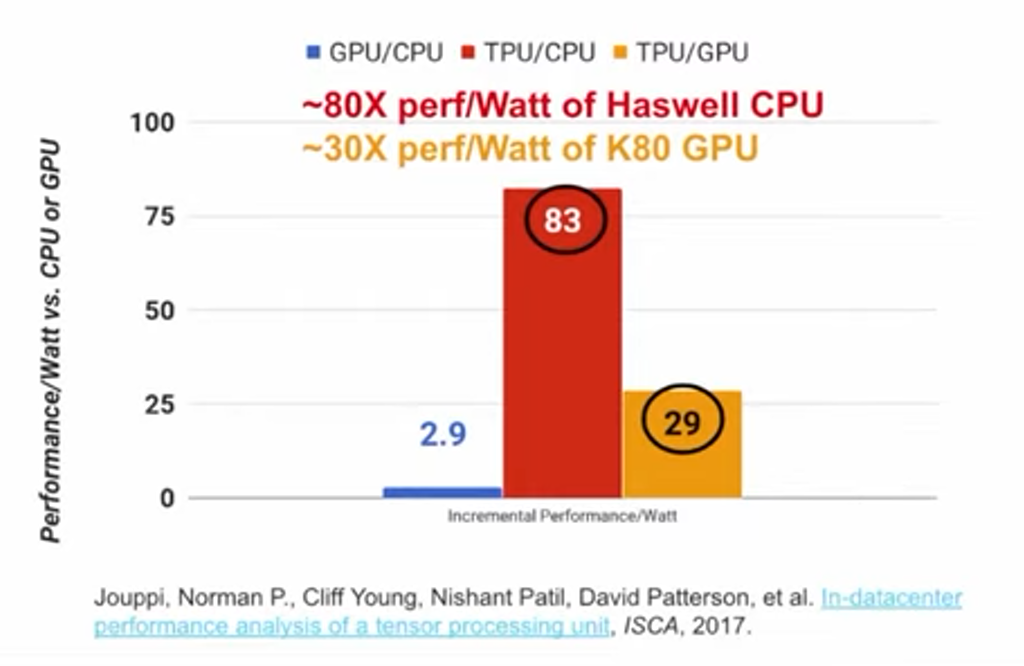
于是,Google在2014年开始研发TPU,项目进展神速,仅15个月后TPU就可在Google数据中心部署应用,而且TPU的性能远超预期,它的每瓦性能是是GPU的30倍、CPU的80倍(数据源自论文:https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf)。
2016年,在Google I/O开发者大会上,Google首席执行官Sundar Pichai对外公布了TPU这一突破性成果,他介绍道:
“通过Google云平台,用户不但可以接触到Google内部使用的高性能软件,还可以使用Google内部开发的专用硬件。机器学习的计算规模巨大,因此Google研发了机器学习专用硬件,也就是‘张量处理单元(TPU)’。TPU的每瓦性能比市面上所有GPU和FPGA都高出一个数量级。用户可以通过Google云平台体验TPU的优异性能。DeepMind研发的AlphaGo在与韩国棋手李世石的对战中使用的底层硬件就是TPU。”

希腊神话中,特洛伊战争的起因是两方争夺世界上最美的女人——海伦,后世诗人将海伦的美貌“令成千战舰为之起航”。我认为TPU就像海伦,它的出现引起了“成千芯片与之竞逐”。
可以说,TPU的问世引发了硅谷的“地震”。TPU宣布诞生后,Intel耗资数十亿美元收购了多家芯片公司,阿里巴巴、Amazon等竞争对手纷纷开始研发类似产品。TPU重新唤起了人们对计算机架构的关注,后来的几年内,出现了上百家相关初创企业,年均总融资额近20亿美元,各种新奇的想法层出不穷。
五年后,Sundar Pichai又在2021年Google I/O开发者大会公布TPU v4:
“AI技术的进步有赖于计算基础设施的支持,而TPU正是Google计算基础设施的重要部分。新一代TPU v4芯片的速度是v3的两倍多。Google用TPU集群构建出Pod超级计算机,单台TPU v4 Pod包含4096块v4芯片,每台Pod的芯片间互连带宽是其他互连技术的10倍,因此,TPU v4 Pod的算力可达1 ExaFLOP,即每秒执行10的18次方浮点运算,相当于1000万台笔记本电脑的总算力。”
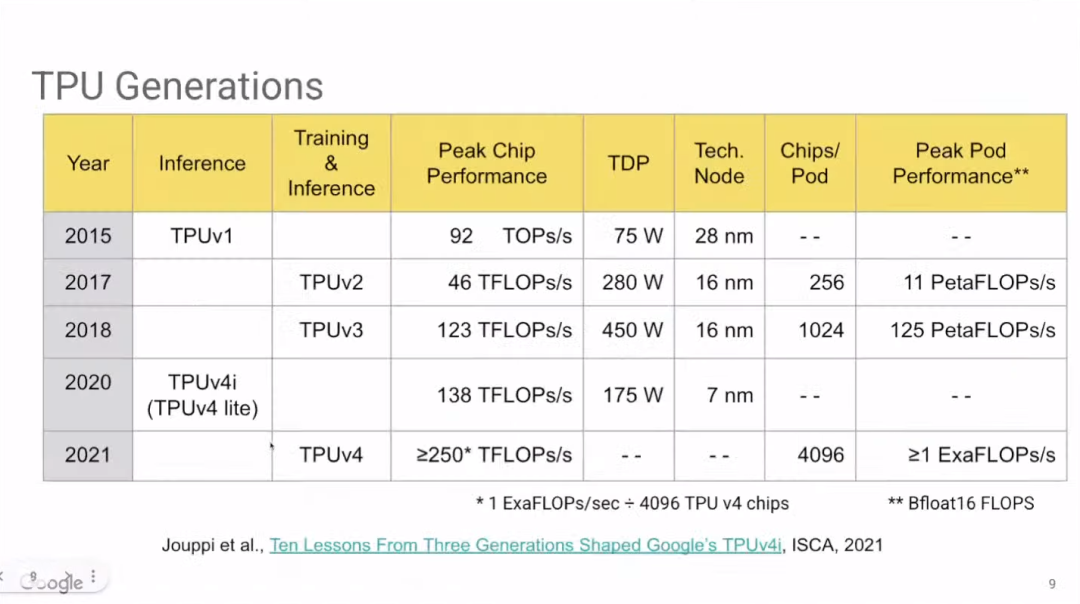
上图展示了TPU的发展历史。其中,Google尚未公布TPU v4i(TPU v4 lite)的相关细节。去年Google宣布TPU v4i已在云服务上可用,也发表了一篇关于TPU v4i的论文(https://www.gwern.net/docs/ai/scaling/hardware/2021-jouppi.pdf)。
2
十年演进,十大教训
过往十年,我们在ML计算架构的发展中汲取了十大教训。

其中,前五个都和ML模型本身有关,后五个则关乎硬件和架构。这些经验对深度学习以外的领域也有借鉴意义。
教训一:DNN所需内存空间和算力迅速增长

我们阅读近几年的论文后发现,推理模型所需的内存空间和算力平均每年增长50%。由于芯片设计和部署至少各需要1年,投入实际使用并优化需要3年。可见,从一款芯片开始设计到生产周期结束的5年内,模型所需的内存空间和算力已增长到大约8倍。因此,在芯片设计之初就要将这种增长考虑在内。
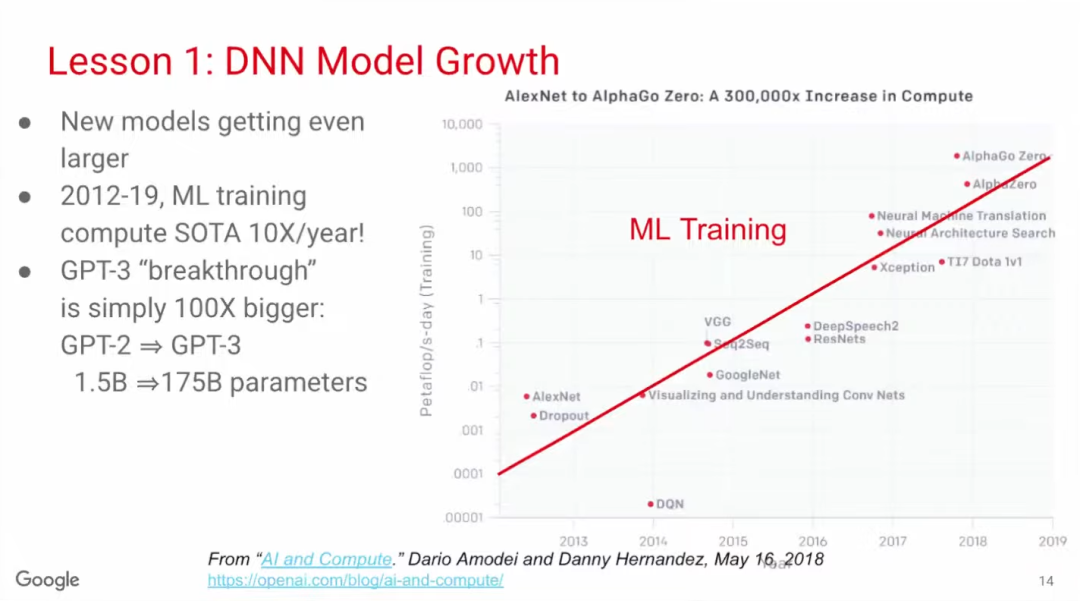
训练模型的增长速度比推理模型更快。根据OpenAI的统计,2012-2019年,SOTA训练模型的算力需求年均增长10倍。备受关注的GPT-3模型的参数量更是从15亿(GPT-2)增长到1750亿,提高了100倍。
教训二:DNN工作负载随着DNN突破不断演变

深度学习是一个日新月异的领域。2016年,MLP(多层感知器)模型仍是主流,但到2020年,CNN、RNN和BERT等不同模型百花齐放。BERT是一种全新的Transformer模型,诞生于2018年,短短两年后,四分之一以上的Google内部应用都在使用BERT模型,可见深度学习发展变化之快。因此,ML计算架构需要能够支持多种模型。
教训三:DNN模型可优化
通常而言,计算机架构师只需懂硬件、体系结构、编译器,如果还懂操作系统则更好,但他们不需要懂应用。然而,构建针对特定领域的架构则需要软硬件兼通。

对ML工程师而言,只要可以让模型跑得更好,他们非常愿意根据硬件/编译器改进DNN模型。毕竟DNN模型不像GCC编译器,后者已成为被广泛采纳的编译器标准,不会轻易根据硬件改动。
DNN模型之所以可以优化,部分原因是这些程序本身不算庞大,大约只是成千上万行PyTorch或TensorFlow代码,操作可行性较强。
Google的一篇论文介绍了一种模型优化技术Platform-aware AutoML,AutoML使用的方法称为“神经架构搜索(Neural Architecture Search)”,即机器自动在搜索空间中寻找更优的神经网络模型结构。在上述论文的例子中,经机器自动优化后的CNN1模型,在相同的硬件和编译器上可实现相同的准确率,而运算性能为原模型的1.6倍。
教训四:影响推理体验的是延迟,而非批次规模
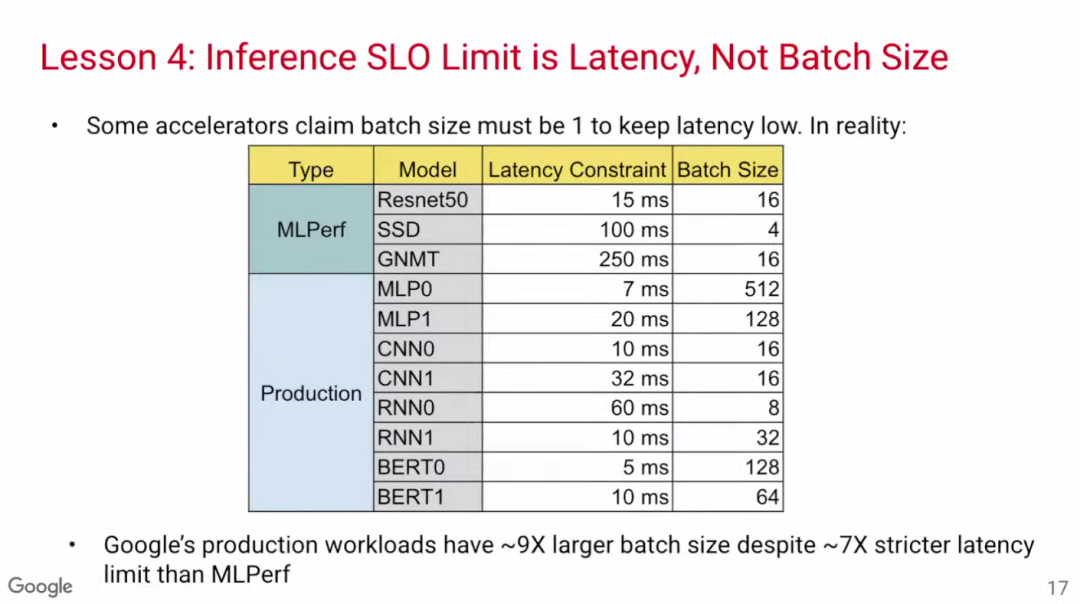
一些关于模型推理优化的论文把重点放在数据批次规模(batch size)上,认为要把batch size设置为1才能使延迟降到最低。然而,通过MLPerf基准数据可见,Google的生产模型在batch size相当大的情况下也能实现低延迟,这可能是因为这些模型是基于TPU开发,因此更加高效。
教训五:生产端推理需要多租户技术

DNN需要使用多租户技术(multi-tenancy)。不少深度学习论文的一个假设是同一时间只需运行一个模型,但在实际应用中,有不少情况都需要在不同模型中切换。
比如,机器翻译涉及各种语言对,就需要不同的模型;传统的软件开发需要用到一个主模型和多个实验模型;甚至有时因为对吞吐量和延迟有不同的侧重要求,就需要不同的batch size,进而需要不同的模型。
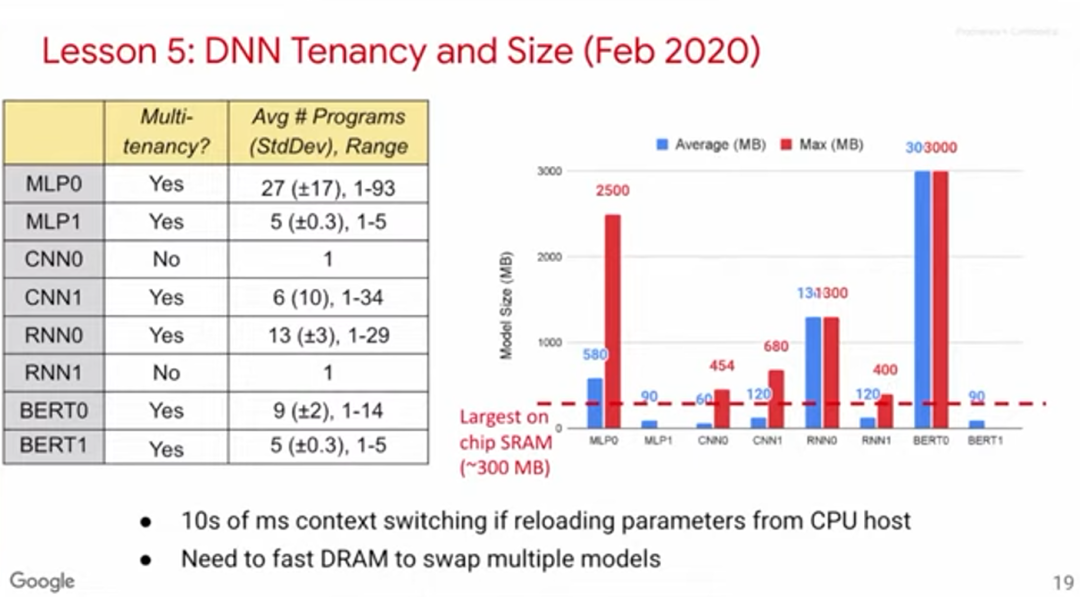
如上图所示,我们收集了8个模型的基准数据,其中6个模型涉及多租户。右方的柱状图展示了模型大小(以MB计算)。红色虚线表示单块芯片的最大SRAM,可见不少模型需要的内存远大于此,这意味着需要有存取速度极快的DRAM。部分芯片的设计思路是利用SRAM解决所有任务,但在多租户应用场景下,我们认为这很难办到。
教训六:重要的是内存,而非浮点运算数
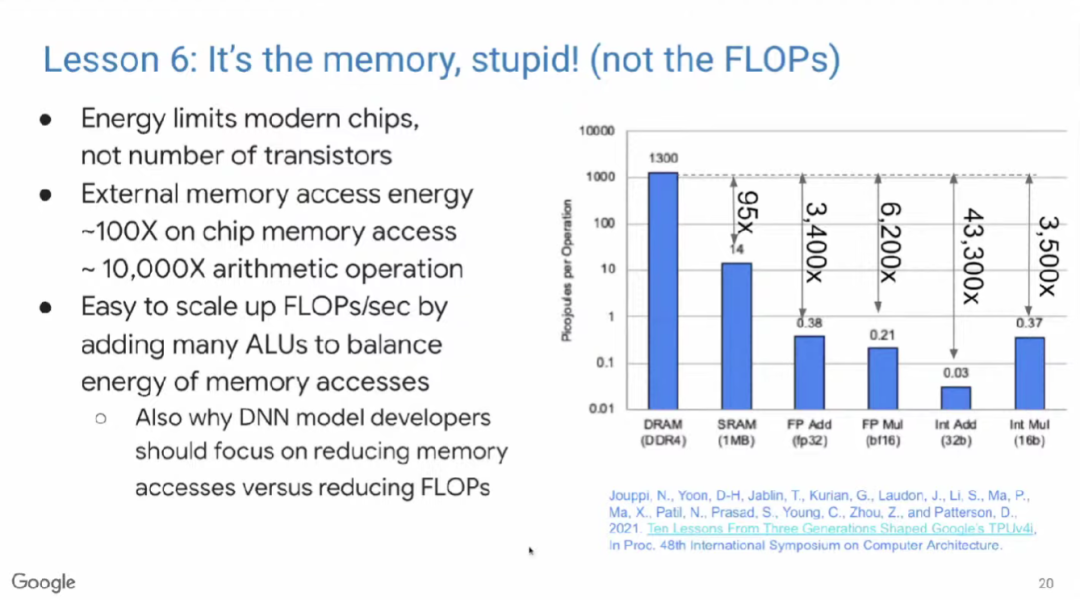
借用克林顿竞选总统时的口号——“重要的是经济,懂吗?”(OneFlow译注:当时美国正值经济萧条,克林顿将经济作为竞选演说的重要话题,最终赢得选举),在此,我想说,“重要的是内存,不是浮点运算数(FLOPs),懂吗?”
现代微处理器最大的瓶颈是能耗,而不是芯片集成度。Yahoo!创始人Mark Horowitz在十多年前就发现,访问片外DRAM的能耗是访问片上DRAM的100倍,是算术运算的5000~10,000倍。因此,我们希望可以通过增加浮点运算单元(FPU)来分摊内存访问开销。基于Mark Horowitz的数据,芯片上的FPU数量被设置为10,000个左右。ML模型开发人员常常试图通过减少浮点运算数来优化模型,但其实减少内存访问数才是更有效的办法。
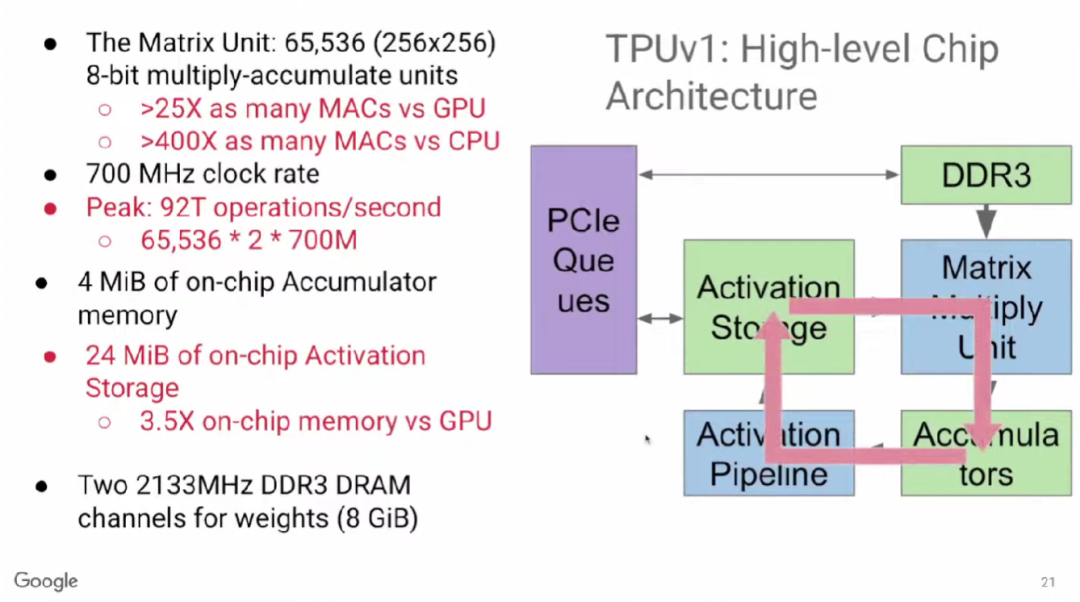
TPU v1有65,000多个乘法单元,比GPU、CPU等硬件高出许多倍。尽管它的时钟频率较低,仅为700MHz,但由于其乘法单元数量巨大,且每个乘法单元可进行2个运算操作,因此TPU v1每秒可执行65,000×2×700M≈90 TeraOPS次操作。
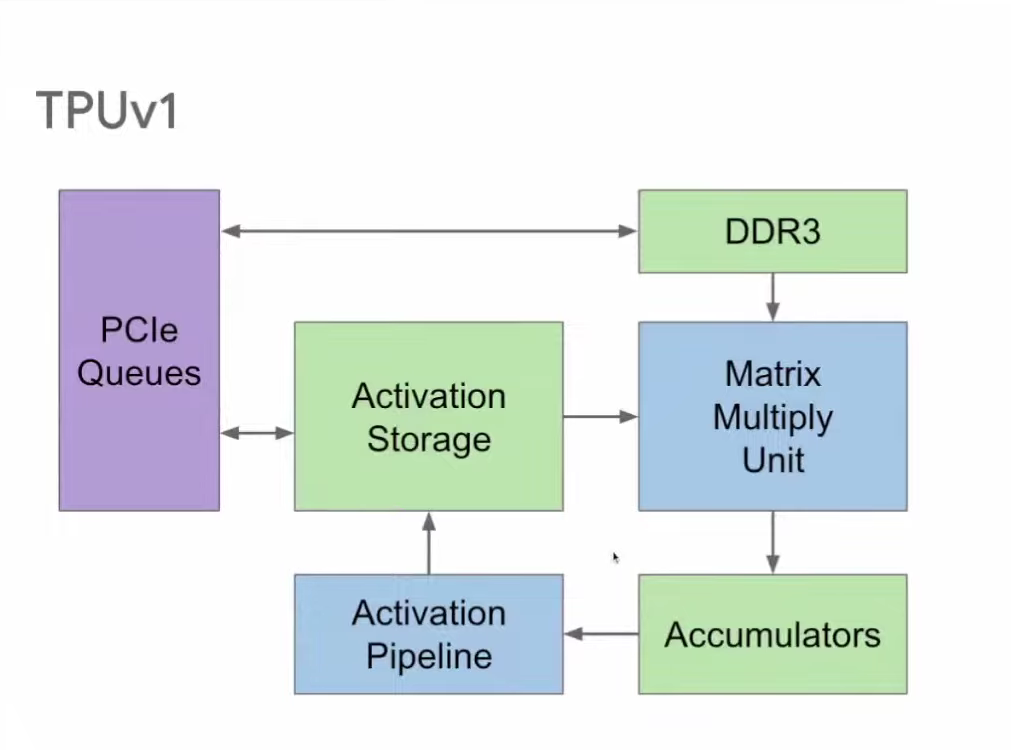
上图右侧展示了运算时的主要工作循环。65,000多个乘法器组成矩阵乘法单元(Matrix Multiply Unit)。计算时,首先启动累加器(Accumulator),然后通过激活函数管道(Activation Pipeline)进行非线性函数运算。累加器和激活函数输出存储(Activation Storage)是两个主要功能单元之间的缓冲区。内存(DDR3)向矩阵乘法单元输入参数;最后,计算结果通过PCIe队列返回服务器。
因此,TPU v1中主要的数据流动如下图红色箭头所示,此外的数据流动还包括DDR3向其中输入权重,以及计算输出结果发送至主机。
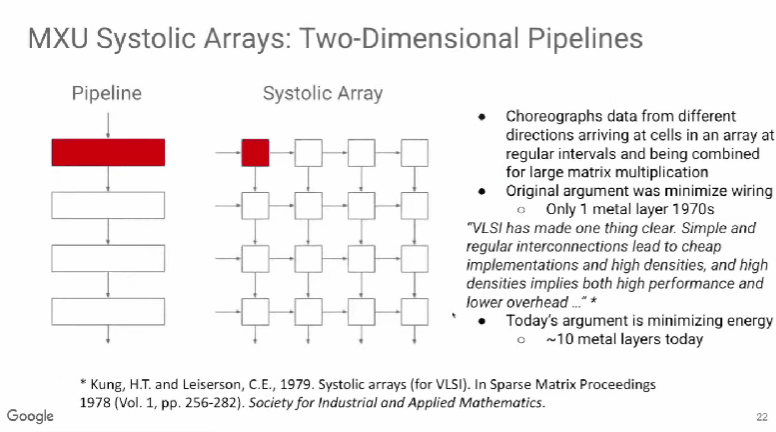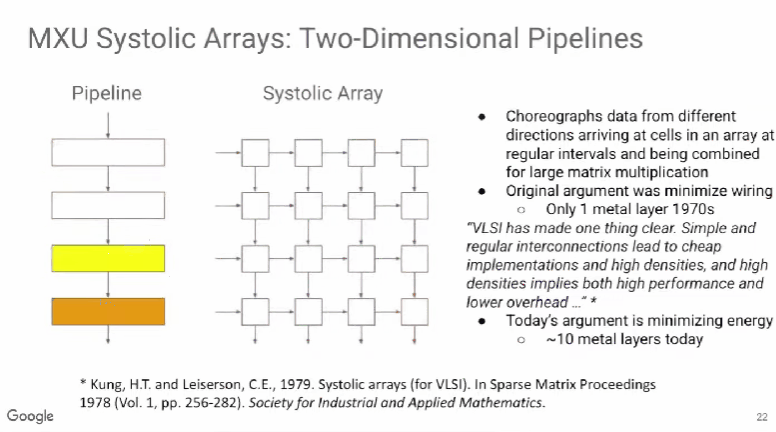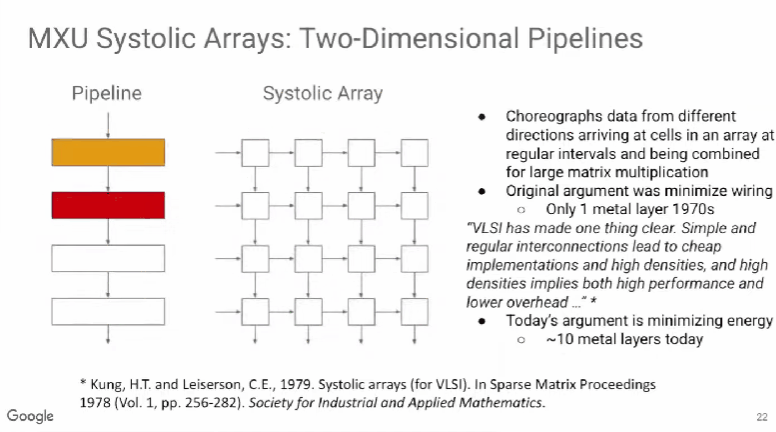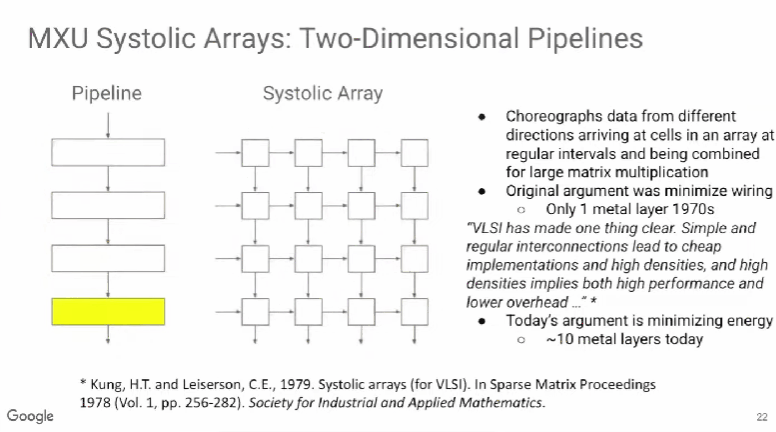
TPU v1使用了脉动阵列(systolic array),这一概念早在40年前就被提出,做法是以固定的时间间隔使数据从不同方向流入阵列中的处理单元(cell),最后将数据累积,以完成大型矩阵乘法运算。由于70年代的芯片只有一个金属层,不能很好地实现互连,所以Kung和Leiserson提出“脉动阵列“以减少布线,简化连接。
现代芯片有多达10个金属层,不存在这方面的问题,其最大难点是能耗,而脉动阵列的能效极高,使用脉动阵列可以使芯片容纳更多乘法单元,从而分摊内存访问开销。
教训七:DSA既要专门优化,也要灵活

作为一种针对特定领域的架构(DSA),TPU的难点在于既要进行针对性的优化,同时还须保持一定的灵活性。Google在推出用于推理的TPU v1之后,决定攻克更难的问题——训练。
训练之所以比推理更加复杂,是因为训练的计算量更大,包含反向传播、转置和求导等运算。而且训练时需要将大量运算结果储存起来用于反向传播的计算,因此也需要更大的内存空间。
TPU v1只支持INT8计算,对训练而言动态范围不够大,因此Google在TPU v2引入了一种的新的浮点格式BFloat16,用于机器学习计算。训练的并行化比推理的并行化更难。由于针对的是训练而非推理,所以TPU v2的可编程性也比TPU v1更高。
与TPU v1相比,TPU v2的改进分为5步。第一步,TPU v1有两个存储区域:Accumulator和Activation Storage,前者负责储存矩阵相乘结果,后者负责储存激活函数输出。
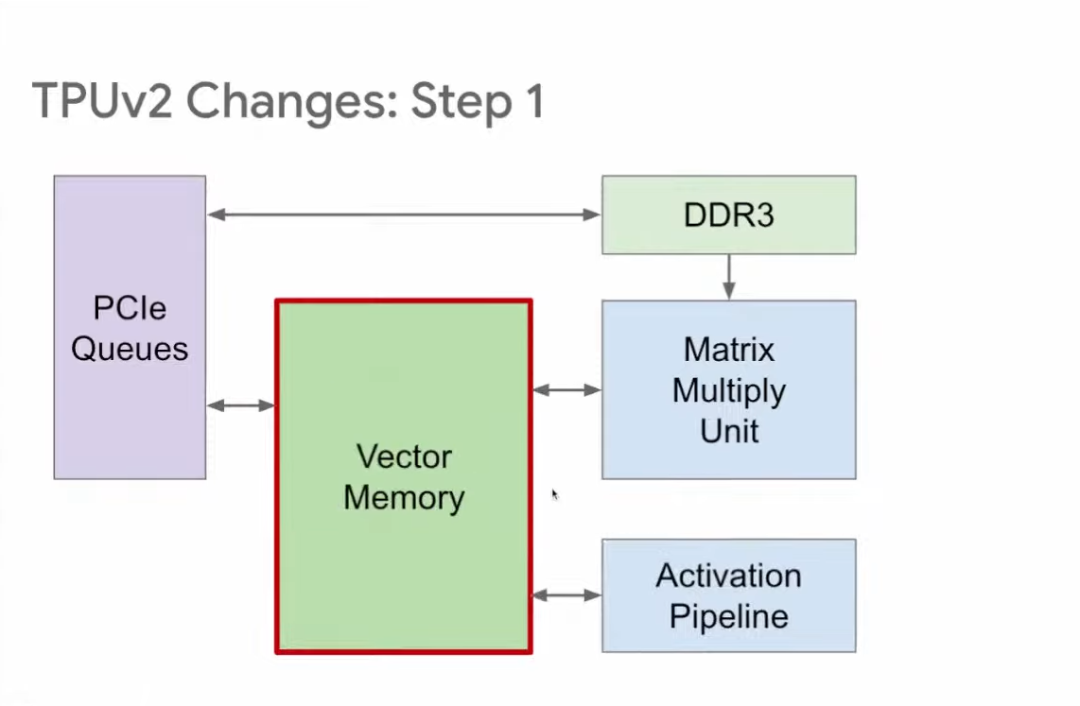
为了提升灵活性,TPU v2将上述两个互相独立的缓冲区调整位置后合并为向量存储区(Vector Memory),从而提高可编程性,这也更类似传统的内存区。
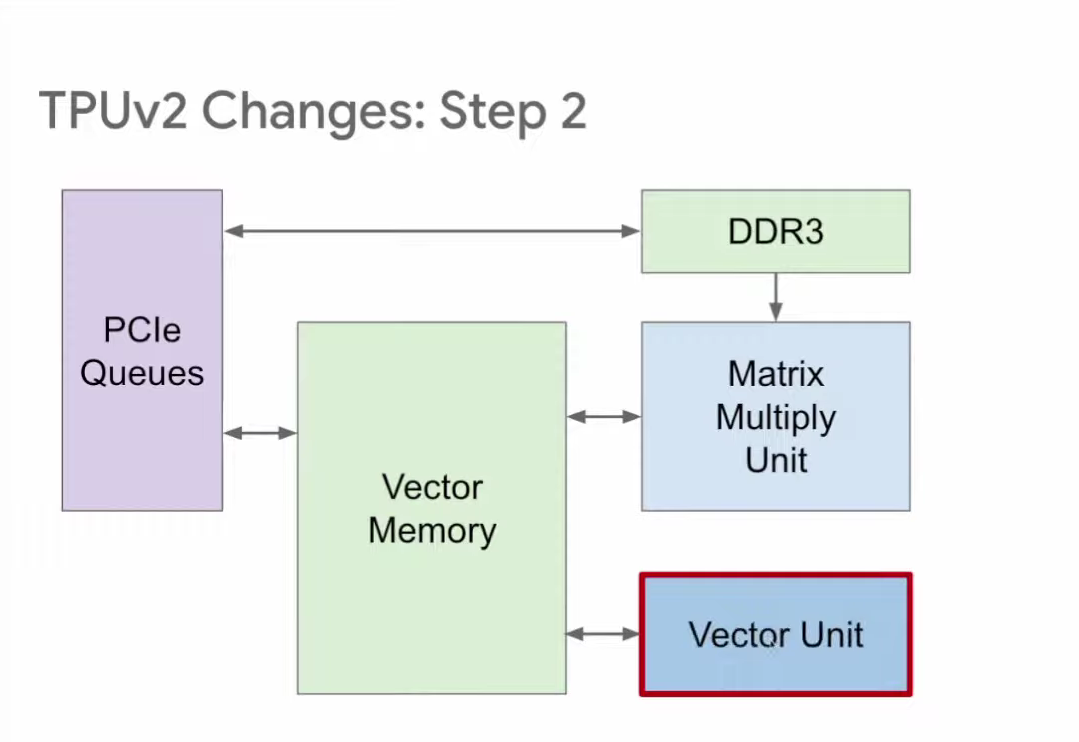
第二步改进针对的是激活函数管道(Activation Pipeline),TPU v1的管道内包含一组负责非线性激活函数运算的固定功能单元。TPU v2则将其改为可编程性更高的向量单元(Vector Unit),使其对编译器和编程人员而言更易用。
第三步,将矩阵乘法单元直接与向量存储区连接,如此一来,矩阵乘法单元就成为向量单元的协处理器。这种结构对编译器和编程人员而言更友好。
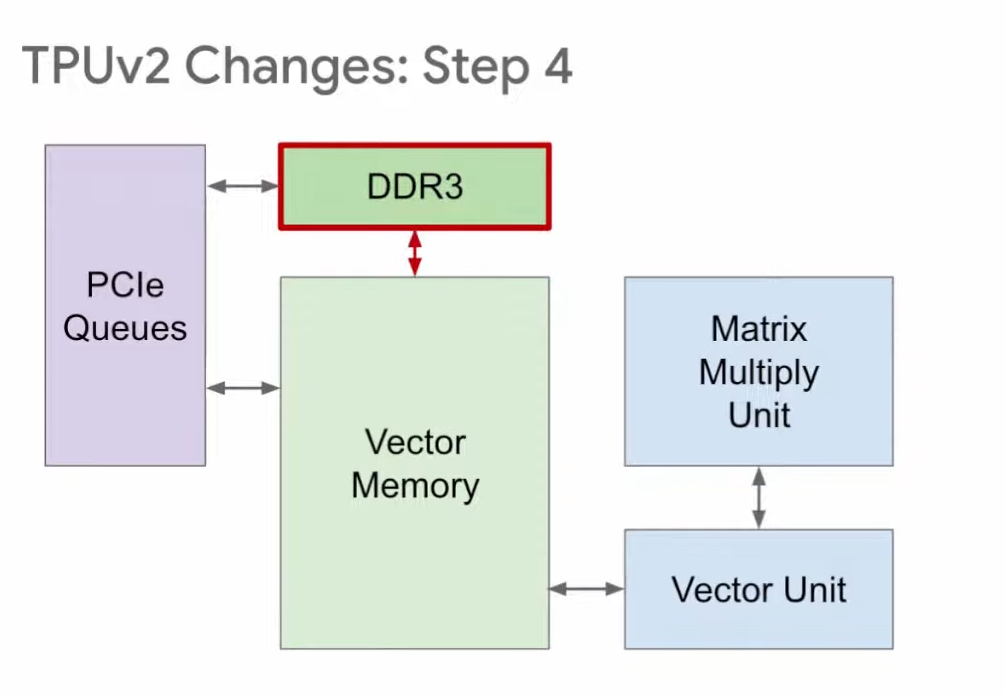
第四步,TPU v1使用DDR3内存,因为它针对的是推理,只需使用已有的权重,不需要生成权重。针对训练的TPU v2则不一样,训练时既要读取权重,也要写入权重,所以在v2中,我们将原本的DDR3改为与向量存储区相连,这样就既能向其读取数据,又能向其写入数据。
然后,我们将DDR3改为HBM。因为从DDR3读取参数速度太慢,影响性能,而HBM的读写速度快20倍。
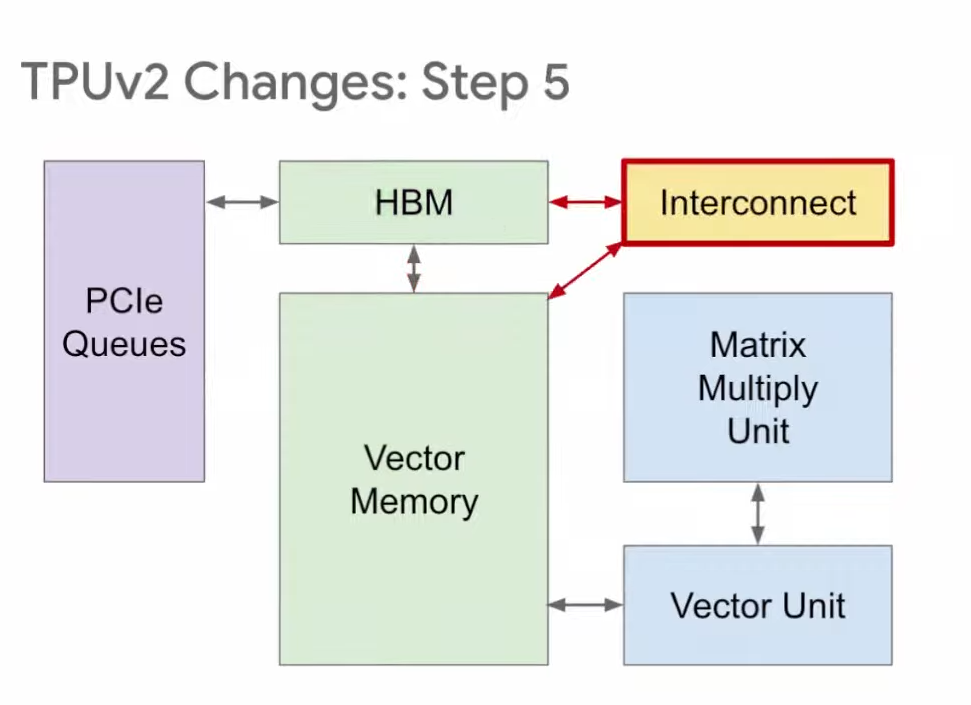
第五步,我们在HBM和向量存储区之间增加互连(Interconnect),用于TPU之间的连接,组成我们之前提到的Pod超级计算机。以上就是从TPU v1到TPU v2的改进。
教训八:半导体技术的发展速度参差不齐

回顾过去可以发现,各类技术的发展速度并不同步。计算逻辑的进步速度很快,芯片布线的发展速度则较慢,而SRAM和HBM比DDR4和GDDR6的速度更快,能效更高。
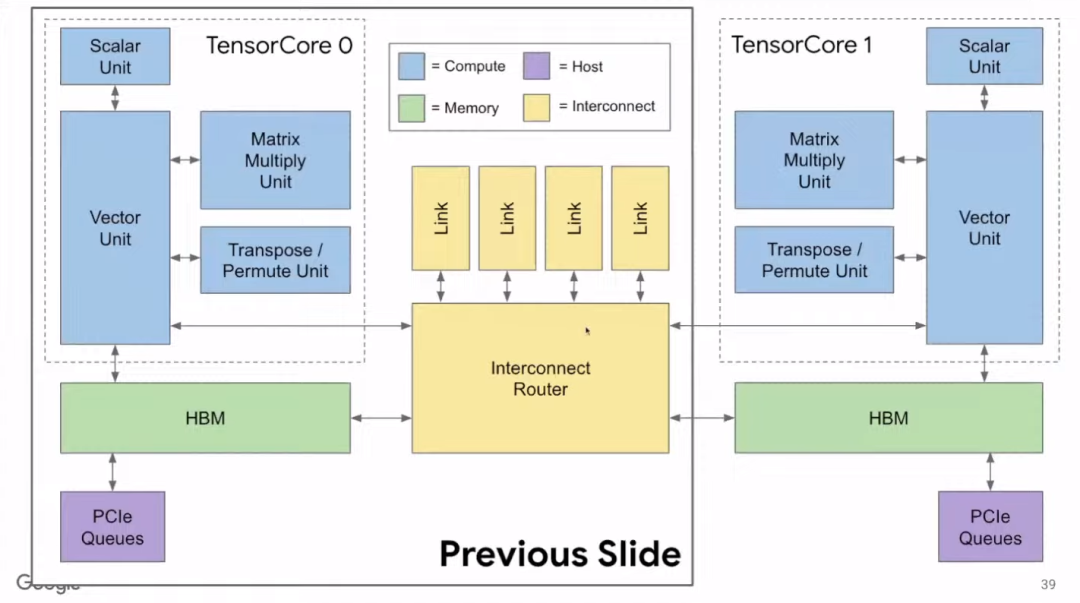
上图虚线框内展示了单个Tensor Core运算单元。TPU v2中有两个互连的Tensor Core。
由于布线技术的进步相对滞后,如果仍像TPU v1一样,每块芯片只有一个Tensor Core,就会导致管道更为冗长,如果管道出了问题也会更加麻烦。因此,我们将两个Tensor Core互相连接,这对编译器而言也更友好。
Google做出TPU v2之后,希望再花一年时间完善v2,所以TPU v3没有引进新技术,只是v2的改进版。
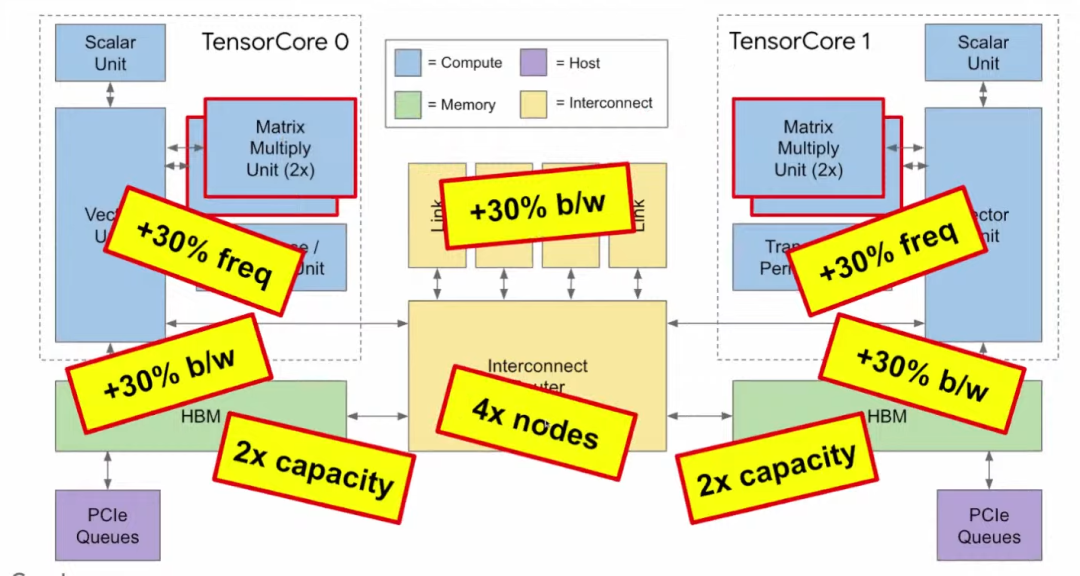
与v2相比,TPU v3有以下特点:
-
体积只大了不到10%;
-
矩阵乘法单元(MXU)的数量翻倍,因此峰值性能也翻倍;
-
时钟频率加快了30%,进一步加快计算速度;
-
内存带宽扩大了30%;
-
容量翻倍,可使多种应用更加方便;
-
芯片间带宽扩大30%;
-
可连接的节点数是之前的4倍。

上图左上角即为TPU v1的主板。中间是v2,v2的散热方式是风冷,所以图中可见高高突起的风冷散热器。右上角是v3,v3的运行温度太高,所以只能采用液冷。左下角是TPU v2组成的Pod超级计算机,共有256张TPU,峰值性能为11 PFLOP/s;右侧的TPU v3 Pod有1024张TPU,峰值性能可达100 PFLOP/s(1 PFLOP/s即每秒1015次浮点运算)。
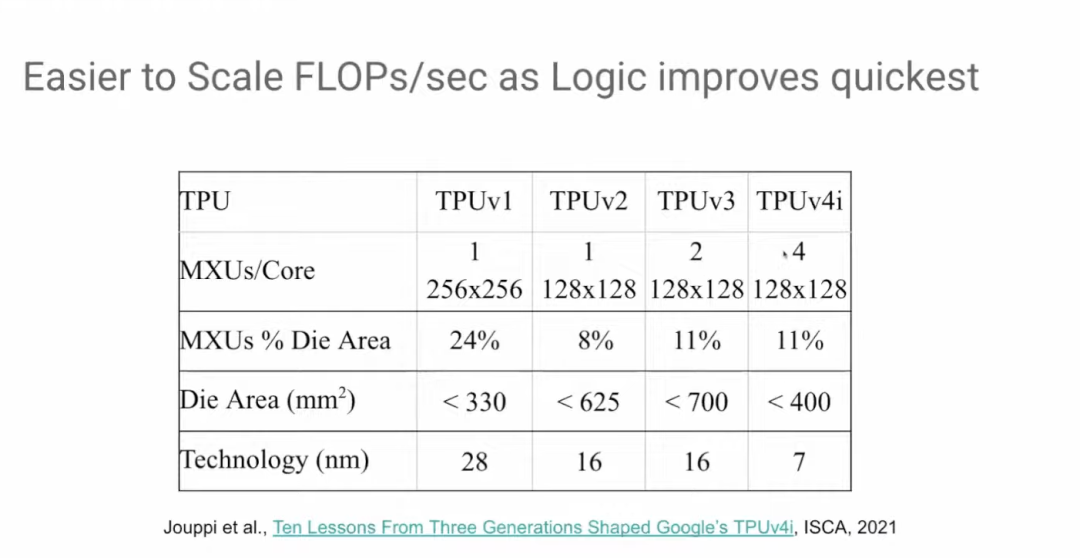
从TPU v3到TPU v4i,矩阵乘法单元的数量再次翻倍,但芯片面积却没有扩大。如前所述,计算逻辑的发展速度是最快的。
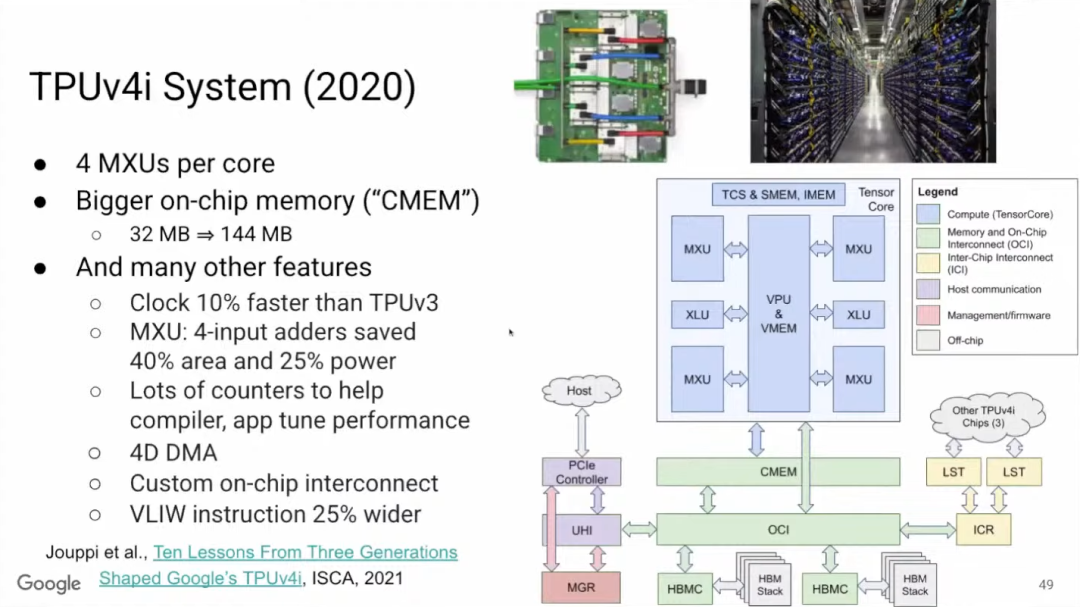
如果想了解TPU v4i,可以阅读论文《Ten Lessons From Three Generations Shaped Google’s TPUv4i》。TPU v4i中,单个Tensor Core有4个矩阵乘法单元,是v3的两倍,且v4i的片上内存更大。此外,TPU v4i的时钟频率加快了10%,矩阵乘法单元中使用四位加法器(4-input adder),可以大幅节省芯片面积和功耗。
性能计数器(Performance counter)的重要性不言而喻,Google在v4i的很多地方都放置了性能计数器,可以更好地协助编译器,并能更清楚地掌握运行情况。
性能计数器没有缓存,它们都在编译器控制的4D DMA (直接存储器访问)之下,并且可以进行自定义互连。最后,为了控制更多的MPU(微处理器)和CMEM,VLIW(超长指令字)指令拓宽到将近400位。
教训九:编译器优化和ML兼容性十分重要

XLA(加速线性代数)编译器可对全程序进行分析和优化,优化分为与机器无关的高级操作和与机器相关的低级操作,高级优化操作将影响TPU和GPU,所以通常我们不会改动高级优化操作,以免导致失灵,但我们可以改动低级优化操作。
XLA编译器可以处理多达4096个芯片的多核并行,2D向量和矩阵功能单元的数据级并行性,以及322~400位VLIW指令集的指令级并行。由于向量寄存器和计算单元是2D,这就要求功能单元和内存中有良好的数据布局。此外,由于没有缓存,所以编译器需要管理所有的内存传输。
最后的问题是,与CPU相比,DSA的软件栈还不够成熟。那么编译器优化最终能够提速多少?

实际上的提速相当可观。其中重要的优化之一称为算子融合(Operator Fusion),如将矩阵乘法与激活函数进行融合,省略将中间结果写入HBM再读取出来的步骤。上图是我们的MLPerf基准测试结果,可见,使用算子融合平均可以带来超两倍的性能提升。
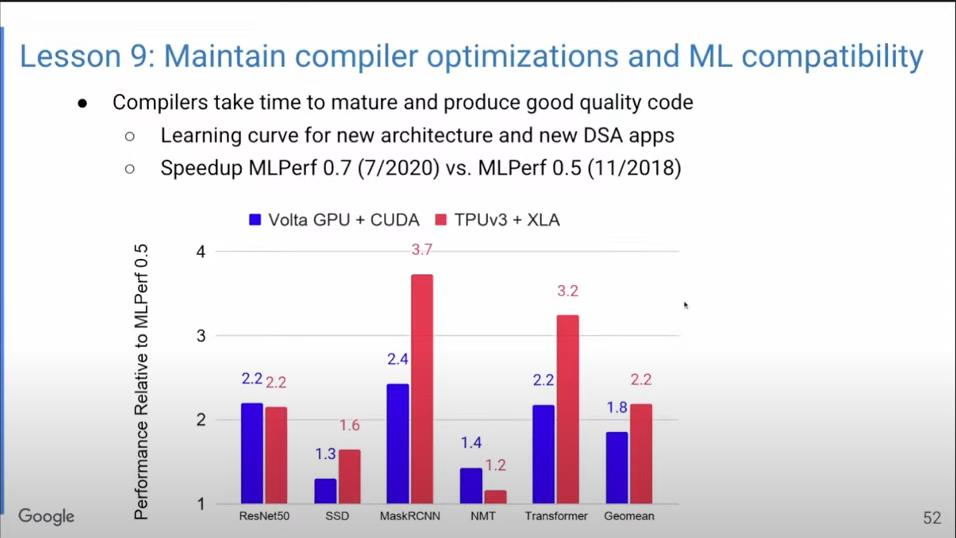
上图显示了编译器优化的提速效果。蓝色表示使用GPU,红色表示使用TPU,经过短短十几个月的优化后,不少模型的性能都提升到了两倍。要知道,对C++编译器而言,如果能在一年内把性能提升5%-10%就已经非常了不起了。
此外,编译器的后向ML兼容性非常重要。我的同事Luiz Barroso主管Google的一个与计算机架构无关的部门,他表示不希望在训练中花太多时间,希望一晚上就可以训练好模型,第二天可以直接部署。我们希望训练和推理时结果一致,这就是我们说的后向ML兼容性,我们还希望它能在所有TPU上运行,而不是每次更改TPU时都要重新训练。

为什么保持后向ML兼容性如此困难?因为浮点加法不符合结合律,所以运算顺序可能会影响运算结果。而TPU的任务就是让所有机器对编译器而言都没有区别,以便可以在重组代码的同时获得相同的高质量结果,以实现后向ML兼容性。
教训十:优化的目标是Perf/TCO还是Perf/CapEx
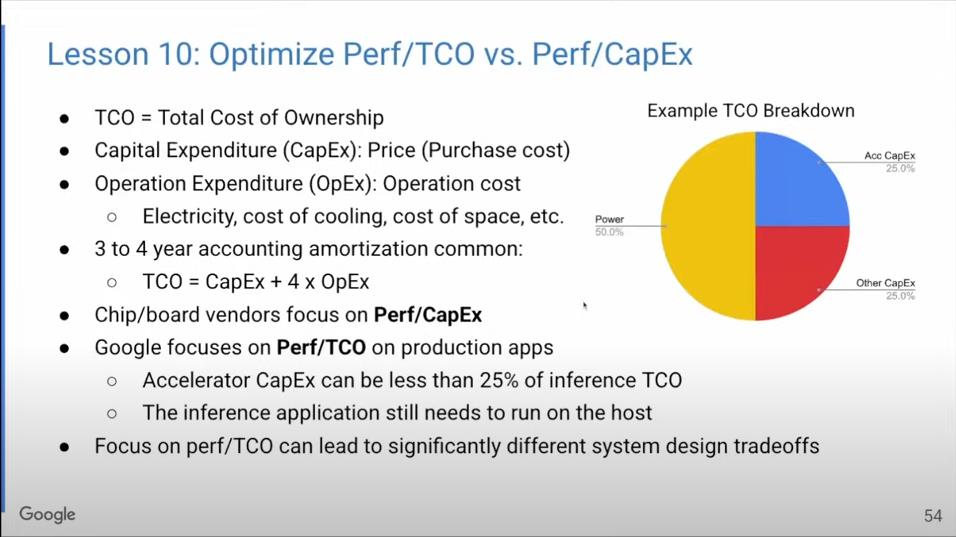
在将研究成果应用到实际生产时,我们优化的目标是什么?Google构建硬件是为了用在自己的数据中心,所以我们所要控制的成本是指总体拥有成本(TCO),包括资本成本(采购成本)和运行成本(电力、冷却、空间成本)。资金成本是一次性的,而运行成本需要持续支出3~4年。
因此,芯片和主板生产商只需要考虑产品性能/资本成本的比率;而Google却要考虑整个硬件生命周期的成本,关注性能/总体拥有成本之间的比率。如上面的饼状图所示,电力可占总体拥有成本的一半。所以,如果把眼光扩大到总体拥有成本上,在系统设计时就很可能会做出不同的取舍。

之前提到,TPU v1有一个Tensor Core,v2和v3有两个。到了v4时,基于对总体拥有成本的考虑,Google决定分开设计:用于训练的TPU v4有两个Tensor Core,用于推理的TPU v4i只有一个。这样就大大提升了性能和总体拥有成本之间的比率。
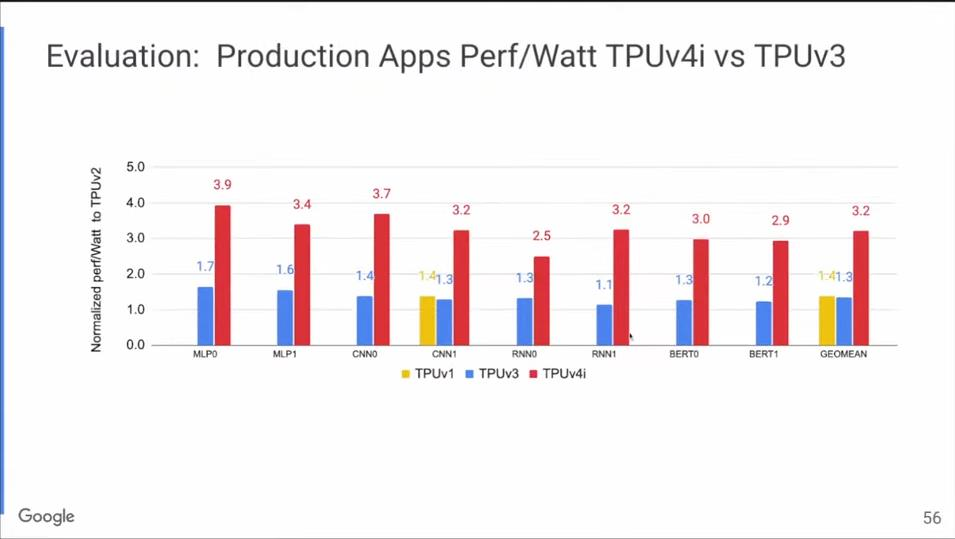
上图是TPU v4i和TPU v3的每瓦性能对比,红色是TPU v4i,蓝色是TPU v3,前者的每瓦性能是后者的两倍以上。
3
提升机器学习能效,减少碳足迹
2021年10月的IEEE Spectrum杂志有一篇文章提到,训练某一模型需要数年时间,花费1000亿美元,总碳排放量相当于纽约一个月的排碳量,如果还要进一步提升模型准确度,这些数字还会更夸张。
2022年1月,又有文章表示,根据当前的算力需求增长曲线预计,到2026年,训练最大AI模型的成本将相当于美国的GDP,大概是20万亿美元。

Google研究了ML硬件的能源消耗。不同于全生命周期消耗的能源(包括从芯片制造到数据中心构建的所有间接碳排放),我们只关注硬件运行时的能源消耗。
展望未来,我们有办法让机器学习的能耗降低到原来的100倍,碳排放量降低1000倍。我们可以从四方面协同着手,极大地促进机器学习在更多领域的可持续发展:
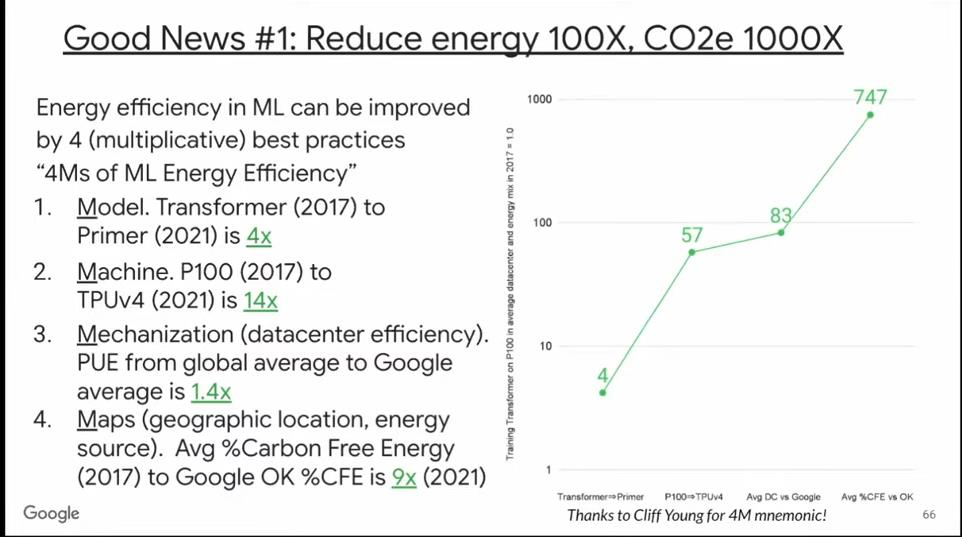
第一个因素是模型。Google在2017年公布Transformer模型,四年后,又开发了Primer模型,其计算质量相同,但能效更高。Primer的能耗和碳排放量相比Transformer降低了4倍。
第二个因素是硬件。2017年所使用的P100 GPU和当前最新TPU的性能相差了14倍。所以,前两个因素结合,可以将能耗和碳排放量降低60倍。
第三个因素是数据中心的能效。Google的PUE大约是其他数据中心的1.4倍。所以,前三个因素累积,可以将能耗和碳排放量降低80倍。
第四个因素是数据中心的地理位置。即使在同一个国家,不同地区使用无碳能源的比例也可能大不相同。在Google所有数据中心所在地中,俄克拉荷马州的无碳能源占比最高,Primer模型就是在此处训练的,这可将碳排放量在上述基础上降低9倍。
综合上述四个因素,我们可将机器学习的能耗降低80倍,碳排放量降低700倍。这非常了不起。
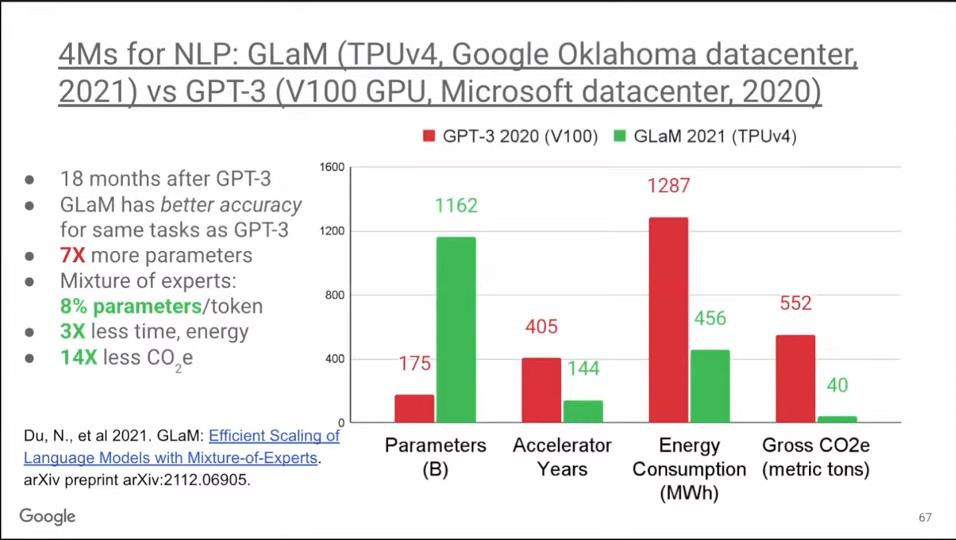
OpenAI的GPT-3问世后引起了Google所有机器学习工程师的注意,他们都卯足了劲想做得更好。18个月后,Google推出了GlaM模型,在相同的基准测试中它的表现比GPT-3更好。GlaM的参数是GPT-3的七倍,达到1.2万亿,但它的能耗却并不大,因为它利用了稀疏性。GlaM是一个MoE模型(Mixture of Experts,专家混合模型),它平时只调用每个token中的8%的参数,而密集型模型会使用100%的参数。因此,GlaM中加速器的工作时长和能耗都降低了3倍。
最后,与GPT-3不同的是,GlaM在俄克拉荷马州使用清洁能源进行训练,因此累计下来,其碳排放量降低了14倍。所以GlaM的例子表明,相比V100 GPU,使用TPU v4既减少了碳排放量,而且计算质量更好。
(原视频链接:https://www.youtube.com/watch?v=PLK3pGELbSs)
其他人都在看
点击“阅读原文”,欢迎体验OneFlow v0.8.0

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK