

Reading Few-shot Video-to-Video Synthesis
source link: https://jyzhu.top/Reading-Few-shot-Video-to-Video-Synthesis/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Reading Few-shot Video-to-Video Synthesis
2022-05-13Computer Notes
Counter not initialized! More info at console err msg. 1.9k 2 分钟
论文地址:http://arxiv.org/abs/1910.12713
作者:Ting-Chun Wang, Ming-Yu Liu, Andrew Tao, Guilin Liu, Jan Kautz, Bryan Catanzaro
发表: NeurIPS 2019
Project: https://nvlabs.github.io/few-shot-vid2vid
Github:https://github.com/NVLabs/few-shot-vid2vid
如果你去做这个任务,会怎么做?作者做的方法和你想的有什么差异?
首先这个任务选题对我来说很新,我之前都没有意识到过这方面的问题。如果告诉我有这样的问题,需要去解决的话,我的直观的想法会受到这篇论文作者的上一篇中提到的 特征嵌入方法 所影响:会想也通过将一类物体的特征编码起来,然后通过学习不同个体的特征编码,来实现不同风格的视频生成。
当今vid2vid方法的两个局限性:
- 需要大量数据,尤其是需要生成的这个人的视频数据
- 泛化能力有限,比如说只能在训练集中包含的人上生成新的pose-to-human视频,不能泛化到训练集中不存在的人上
所以这篇论文就是想解决这两个问题。
What:
任务是Video-to-video synthesis,即利用输入的语义视频(例如人的姿势、街景),生成写实的视频。例如说,人体姿势生成的任务,就是首先收集一个人做大量不同动作的视频,作为训练集;然后向模型中输入动作序列,让模型生成该人做该动作的视频。再比如街景生成,也是以大量街景视频作为训练集,然后向模型中输入语义mask序列,让它生成风格类似的全新街景。
这篇论文提出了一个网络,其中包括一个网络权重生成模块(novel network weight generation module)和attention机制
这个方法的创新点在于,只需要在测试时,向模型提供少量的在训练集中没出现过的新的人物的图像,它就能生成这个新的人的视频。
image-20220513171420180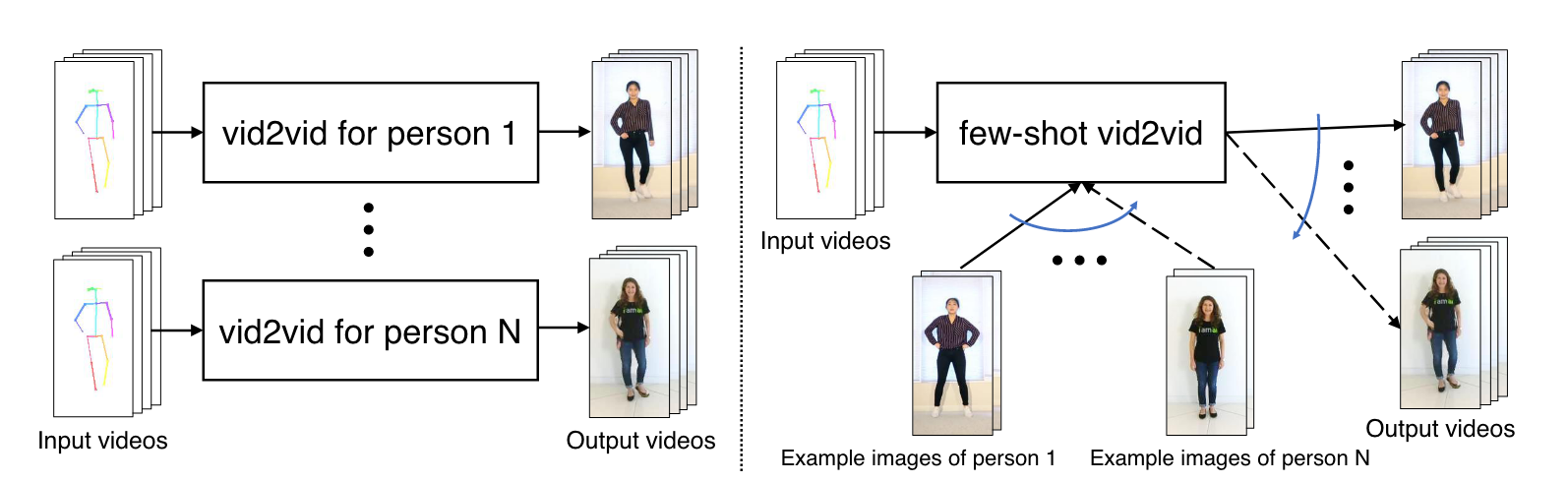
上图中,左边是现存方法,它们基本上对于每个人,都需要在单独的训练集上训练。右边是这篇论文提出的方法,只需要训练一次,然后输入一些示范图像,就可以泛化到新的人上。
读前疑问:
- 说是利用少量的新的人物的示范图像,生成网络权重。意思是以原本的vid2vid网络的权重作为输出?为什么?我的更直观的想法是,直接用一个新网络,学习新人物的图像,然后把output给concat或者加进旧网络的output中……另外,直接作用于网络权重上,在我的粗浅理解中,会不会造成信息的损失呢?还是说本质上没差? related work里提到这类网络属于adaptive network,跟常规网络相比有不同的inductive bias(想想也是),有对应的应用任务。或许我之后再了解一下这块。
- 标题中的few-shot是什么意思,就是指更少的data、更高的泛化性吗?这是一类任务吧,从少量标注的样本中学习的意思。这个确实就是啊,只需要一点点示范图像,就可以生成图中这个人/物的新video。
- 作者的上篇论文是利用gan,这篇又用上了attention,为什么作出这样本质的改变呢?
- 视频生成任务可以分成3类:
- unconditional synthesis:随机生成视频片段
- future video prediction
- vid2vid:把语义输入转变成现实风的视频。这篇论文就是属于这个任务,不过它聚焦的点在于few shot,即通过在测试的时候输入少量图像,让生成的视频可以泛化到没见过的domain上
vid2vid是前一篇工作的内容啦。reference:Reading vid2vid
few-shot本质上就是多加了个网络E,用来生成原补洞网络H的权重。至于原本还有两个网络W和M,他们都不需要改动,因为他们都是基于上一帧生成的图像进行变形的,代表一种运动,而和视频本质的内容没有关系。
精髓一图:
image-20220810193845710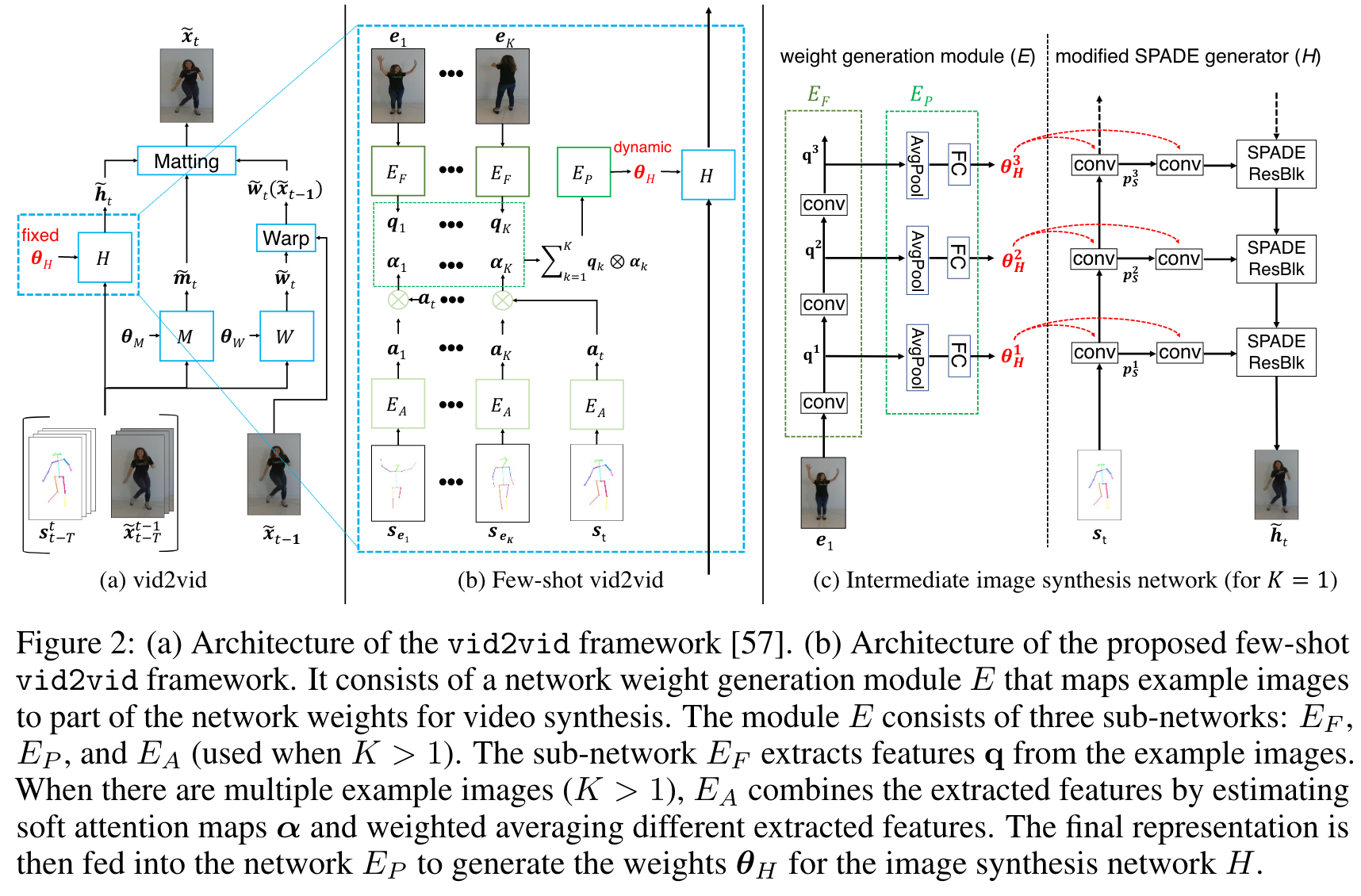
用最新的SOTA语义图像生成模型SPADE代替了上一篇论文中的网络H。SPADE包含several spatial modulation branches and a main image synthesis branch。不过网络E只更新SPADE模型中的spatial modulation branches的权重,因为1这样量比较小,2这样可以避免一个直接从input image到output image的短路(我尚没有深究原因)。
权重生成模块E。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK