

修复 Wordpress 与 MySQL 中文乱码
source link: https://freemind.pluskid.org/technology/wordpress-mysql-coding-issue/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
修复 Wordpress 与 MySQL 中文乱码
前一阵子有网友告知我的旧博客现在显示完全是乱码。类似于这样子:
记得最开始写的那个 blog 也是在大概两年之åŽæ¢çš„,就是现在这个 blog 。ä¸è¿‡å½“时之所以æ¢æ˜¯å› 为原æ¥å¸®æˆ‘ host blog 的朋å‹ä»–们的主机è¦åœæ¢ä½¿ç”¨äº†ï¼Œåœ¨ DH æ–°æ了 blog 但是懒得从旧版本的 wordpress 费力导入新版本,于是就分开了两个 blog ,旧的ä¸å’新帖,åªä¾›è®¿é—®ã€‚
于是我抽空调查并修复了一下,虽然这些年随着 Unicode 以及 UTF-8 编码的普及,乱码问题已经逐渐不那么常见了,但这个看起来好像还是一个比较容易碰到的问题,所以这里分享一下问题的根源和修复办法。
首先说乱码原因,它们是以 UTF-8 格式编码的中文被当作是 CP1252 编码的文本处理之后的结果。例如在 Python3 里通过如下方式即可还原原来的中文:
garbled_text = ("记得最开始写的那个 blog 也是在大概"
"两年之åŽæ¢çš„,就是现在这个 blog")
cp1252_encode(garbled_text).decode('utf-8')
# ==> '记得最开始写的那个 blog 也是在大概两年之后换的,就是现在这个 blog'
这里 cp1252_encode(text) 是我们定义的一个辅助函数,和
text.encode('cp1252') 功能类似,只是多处理几个 corner
case,我们后面会讲。当然实际情况下这个字符串本身通常是以某种编码(例如
UTF-8)存储在文件或者数据库里的,例如我的乱码博客主页的 HTML
文件用编辑器的二进制模式打开是这样的:
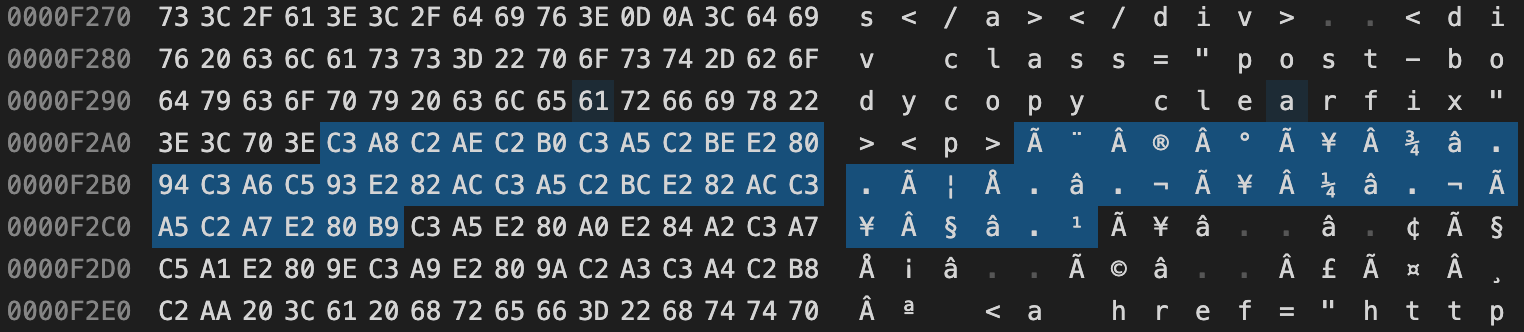
这里显示的二进制值是乱码的字符串再以 UTF-8 格式编码后的结果,例如以 C3 A8 C2 AE 开始的这一段,可以用如下 Python 代码来验证:
codes = b'\xc3\xa8\xc2\xae\xc2\xb0\xc3\xa5\xc2\xbe\xe2\x80\x94'
codes.decode('utf-8').encode('cp1252').decode('utf-8')
# ==> '记得'
Python 在打开文件的时候可以指定 encoding='utf-8'
选项,读入文本的过程实际上就是完成了上面代码中的第一步解码。例如,我们可以通过类似如下的代码来解析
HTML 文件里的乱码:
with open('unicode.txt', encoding='utf-8') as f:
print(cp1252_encode(f.read()).decode('utf-8', errors='ignore'))
我碰到的情况是 MySQL
数据库里的文本乱码了,要解决这个办法一个是可以将数据库导出为 sql
文件,然后使用 Python 通过类似于上面的办法来修复 sql
文件的编码,之后再导入回数据库。除此之外,MySQL
也支持直接对数据库的列进行转码操作。假设我有一个叫 comments
的表格需要修复,下面我们先将该表格复制一个备份:
CREATE TABLE comments_backup LIKE comments;
INSERT INTO comments_backup SELECT * FROM comments;
假设该表格的 content
列是乱码,我们可以通过如下指令即可修复:
UPDATE
comments
SET
content =
CASE
WHEN CONVERT(CAST(CONVERT(content USING latin1) AS BINARY) USING utf8mb4) IS NULL THEN content
ELSE CONVERT(CAST(CONVERT(content USING latin1) AS BINARY) USING content)
END
这里我们使用了 MySQL 的 CONVERT
函数,注意我们这里使用了 Latin 1
来转码,因为根据官方文档,MySQL
里所谓的 latin1 编码其实是 CP1252 编码(并且 MySQL 里的
UTF-8 居然默认不是完整的 UTF-8,无法处理 4
字节编码的字符,并且未来这个默认情况会变成能处理 4
字节字符的情况,怎么感觉满地都是坑?)。
另外这里是使用“转码”的方式,有点绕弯,Python
的编码+解码的组合比较容易理解,因为有 Unicode
字符串本身作为中间变量。MySQL 里并没有 Unicode
字符串,所有的文本都是以某一种编码存储的,由于我的表格编码是
UTF-8,上面的第一个 CONVERT(... USING latin1)
其实是对其内容进行 UTF-8 到 latin1 的转码,对应到 Python 就是先以 UTF-8
进行解码,然后再以 latin1
进行编码,和我们上面写的操作一致,接下来只要再使用 UTF-8
进行解码即可恢复原来的文本 Unicode。不过 MySQL 里不存在 Unicode
文本,而到这一步我们其实已经得到了正确的 UTF-8
编码的内容,只是由于之前的转码操作,MySQL
在表格的元信息里记下来了这一列的数据是 latin1 编码的文本,我们需要让
MySQL 直接将它当成 UTF-8 文本(这一步是 reinterpretation
而不是转码),具体做法就是上面代码里显示的,先通过 CAST
将这一列的内容变成普通二进制数据,让 MySQL 丢掉原来的 (latin1)
编码元信息,然后再将其“转码”为 UTF-8 编码,我猜 MySQL 的转码函数在
source
是无编码的二进制数据时不对内容做任何操作,直接简单地加上列的编码元信息。这样一来就完成了内容修复。😃
文本编码小知识
为什么正常的中文变成乱码之后看起来有很多重复类似的头上有小帽帽的字母了呢?这其实对让我们找到错误的编码给了一些提示。首先原本的文本是以 UTF-8 格式编码的,UTF-8 是一个变长编码,一个字符有可能会被编码为一个字节到四个字节不等的长度,而第一个字节的头几个位决定了该字符是以几个字节编码的,见下图:
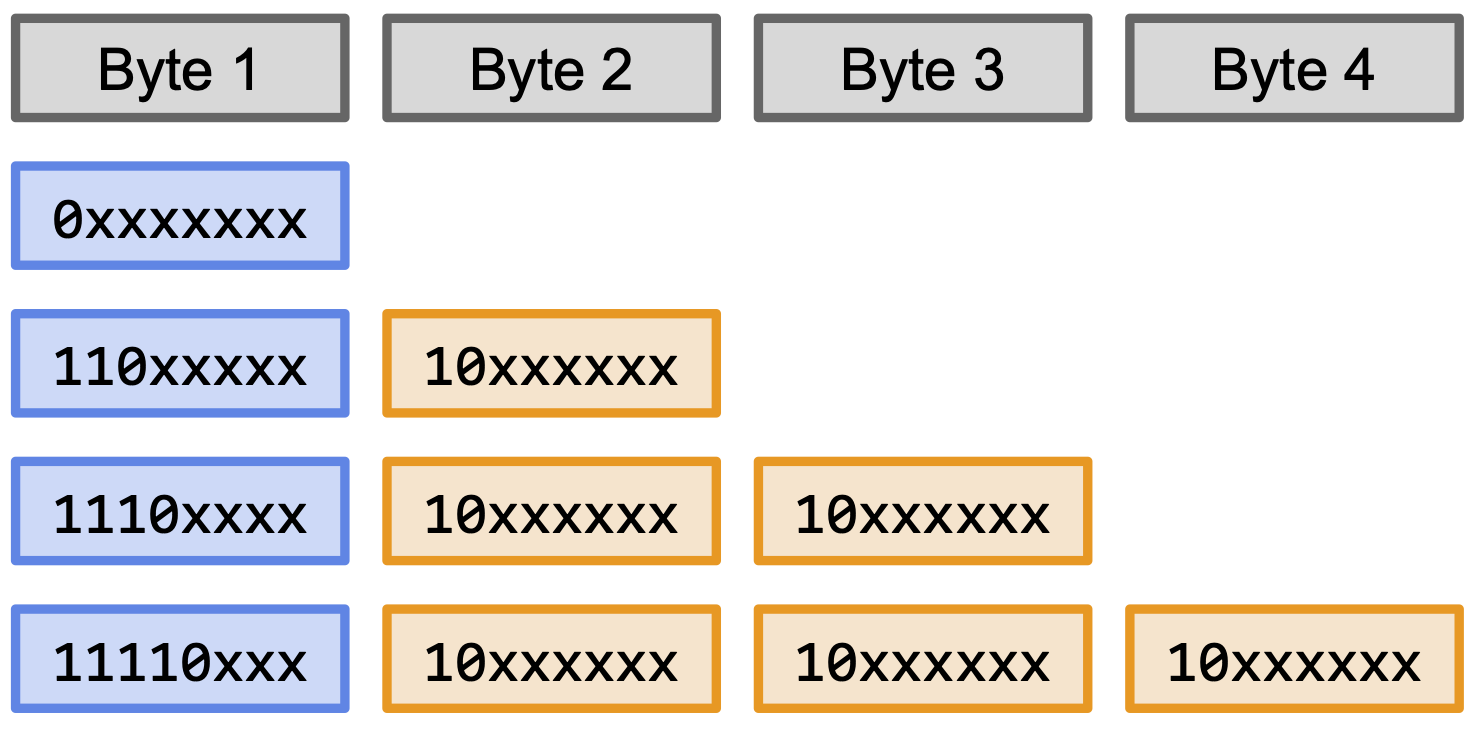
中文字符很多都是以三个字节编码的,例如下面代码中“记得最开始”五个字的编码全都是三个字节的,注意第一个字节都是以 1110 开始,乱码里的重复类似的字母很有可能就是这个固定的前缀编码导致的。
def show_encoding(text, encoding):
for ch in text:
ch_bytes = ch.encode(encoding)
ch_bits = '_'.join(f'{x:08b}' for x in ch_bytes)
print(f'{ch} => {repr(ch_bytes):>15s} ({ch_bits})')
text = '记得最开始'
show_encoding(text, 'utf-8')
# 记 => b'\xe8\xae\xb0' (11101000_10101110_10110000)
# 得 => b'\xe5\xbe\x97' (11100101_10111110_10010111)
# 最 => b'\xe6\x9c\x80' (11100110_10011100_10000000)
# 开 => b'\xe5\xbc\x80' (11100101_10111100_10000000)
# 始 => b'\xe5\xa7\x8b' (11100101_10100111_10001011)
所以如果找到什么编码里以 1110 开始的字节对应那些 äåé 之类的字符的话,很有可能就是罪魁祸首了。事实上,从 Wikipedia 里 latin1 编码的码表可以看到,Ex 行,也就是十六进制 E (二进制 1110) 为头四位的字节正是这些字符: àáâãäåæçèéêëìíîï 。当然最后证实是 CP1252 而不是 latin1,是因为 MySQL 里奇怪设置的缘故。实际中 CP1252 和 latin1 编码基本上是一样的(例如 CP1252 码表里的 Ex 行也是这些帽帽字符),只是前者把后者码表里一些不可显示的控制字符的位置用来编码里一些额外的符号。
另外这种编码之间的转换并不总是无损可完美恢复的,特别是有些编码里有一些不合法的或者未定义的码,例如
CP1252 里 0x90 就是未定义的,程序以 CP1252
进行解码的时候碰到该字节时行为时不确定的。在 Python
里默认是抛出异常,拒绝继续解码。通过 errors='ignore' 可以让
Python
直接忽略该字节,如果是这样的话这个字节的数据就字节丢失了,之后即使找到正确的编码组合也无法正常恢复所有的文本。还好
MySQL
里的处理方法似乎是直接照原样复制,所以文本恢复过程基本没有问题。下面的代码中定义了
cp1252_encode 和 cp1252_decode 两个函数,通过
errors='surrogateescape' 简单地模拟了 MySQL
的行为,也就是本文前面使用的 CP1252 编码函数。
# decode_table: 0xDC80-0xDCFF => 0x80-0xFF
# encode_table: the reverse
cp1252_encode_table = {}
cp1252_decode_table = {}
for i in range(128, 256):
decoded_char = bytearray([i]).decode('cp1252', errors='surrogateescape')
if ord(decoded_char) >= 0xDC80 and ord(decoded_char) <= 0xDCFF:
cp1252_decode_table[decoded_char] = chr(i)
cp1252_encode_table[chr(i)] = decoded_char
def cp1252_decode(bytes):
"""CP1252 decode, with un-decodable bytes being pass through."""
text = bytes.decode('cp1252', errors='surrogateescape')
return ''.join(map(lambda x: cp1252_decode_table.get(x, x), text))
def cp1252_encode(text):
"""CP1252 decode, with un-decodable bytes being pass through."""
text = ''.join(map(lambda x: cp1252_encode_table.get(x, x), text))
return text.encode('cp1252', errors='surrogateescape')
以下大致记录一下时间线。刚看到乱码的时候我的第一反应是网页被用非
UTF-8 编码渲染出来(例如中文常用的 GBK 编码等),然后被浏览器当作 UTF-8
来解码了,此时在浏览器里选择以某个特定的编码打开通常就能解决问题,在我上大学的年代经常会有这样的情况,但是现在
UTF-8 编码已经相当普及了,基本上大部分网站都会直接用 UTF-8
编码渲染,并在 HTML
里明确指定字符集,所以现在许多浏览器都直接去掉了让用户可以手动选择编码的功能(我只看到
Safari 还有)。如果浏览器不支持,也可以直接下载 HTML 文件,用 Vim
打开,然后使用命令 :e ++enc=gbk 就能让 VIM
重新读取该文件并以 gbk
进行解码。当然这两种方法都没有解决问题,因为这里碰到的是错误解码并被二次编码的情况。
通过 WayBack Machine 找到了我的旧博客的去年七月的一个备份版本,至少当时显示是一切正常的,主要是这提供了足够的原始文本让我后面可以进行编码比对。其实我一开始并不知道问题是出在 Wordpress 的配置还是数据库内容本身,禁用 Wordpress 插件等基本操作都没有解决问题。而且奇怪的是博客内容是乱码,但是“最近评论”却是正常的中文,检查了一下 Wordpress 插件的代码发现它有一个缓存,如果没有新评论的话就直接显示缓存里的内容,而不是去数据库读取原始评论。这说明问题很可能出在数据库上。
接下来通过 phpMyAdmin 登陆到数据库上,发现表格的内容确实是乱码,尝试设置 Wordpress 连接数据库的编码,以及配置数据库表格本身的编码等都没能造成任何影响。这个时候我尝试在数据库里手工插入一条带中文的数据,发现内容显示出来是正常的编码,这说明并不是数据库配置的问题,而是数据库里的已有内容本身遭到破坏了。究竟数据库里的内容是如何损坏的,这个问题至今仍然是一个谜,一个可能的原因是我的博客服务器的提供商进行了一次系统迁移,并且使用导出导入的方法进行了数据库备份和恢复,但是恢复的时候没有指定正确的编码,当然是否是这样我也无从验证,但是以这个为线索其实能在网上搜到很多相关的情况,再加上其他一些线索(例如乱码里常见的编码)最后绕了一大圈弯路才找到了问题的根源和解决办法。
当然最后还有一个小插曲就是修复了文章内容和评论表格的编码之后,博客整体显示正常了,但是每篇文章的标题却依旧是乱码,更奇特的是在 Wordpress 文章编辑页面上看到的标题又是正常的。一开始我以为是某些缓存的问题,尝试禁用相关的插件,刷新浏览器缓存以及服务器缓存都无果。想尝试直接编辑并保存文章的方式来强制刷新其它可能存在的缓存,结果发现似乎 Wordpress 的版本太旧了,已经无法保存编辑了……😅 最后一招是切换博客主题,发现切换之后终于显示正常了,但是换回原来的主题之后还是继续乱码,这说明问题大概不是出在缓存,而是在我使用的博客主题本身。然后既不懂 PHP 也不知道 Wordpress 的主题插件架构的我居然大海捞针地找到了主题插件里相关的代码问题:原来它不知道出于什么目的,在最初编辑博客的时候在博客文章本身的表格之外又存储了一份主题特定的元信息,并在里面另存了一份博客标题,由于我修复 SQL 编码的时候没有修复那个表格,所以依旧是乱码,但是其他主题里是直接读取博客文章表格里的标题字段,所以就没有乱码问题。
Wordpress 博客静态化
在碰到各种问题,特别是事后小插曲之后,让我深刻认识到软件的老化与消亡的问题。软件作为一段代码虽然是一个静态的存在,并且作为数字内容存在,除非碰到重大数据灾难,并不会像实物那样磨损和消耗,但是它作为一个可运行的实体却是确确实实需要不断维护和更新,否则就会逐渐出现各种各样的问题并最终“死亡”(无法运行)。这是因为没有任何软件是完全独立存在的,软件本身可以保持不变,但是其周围的环境总在随着时间的变化而变化,其中有些变化会有意或无意地引入向后不兼容的问题,所以从软件自身的角度来说,其实是“不进则退”的。更严重的是如果软件依赖的技术、第三方库等本身陷入停滞状态,那么软件也会被迫逐渐消亡。
但是我们并没有足够的精力去持续维护和更新所有的软件,就我的旧博客系统来说,上一次使用已经是十年前了,其实过了这么久它还能正常打开已经是挺出乎意料的了(当然更出乎意料意料的是现在还有人会看我当时写的文章,有些内容我现在看来应该挺幼稚的),不过即使是为自己的归档目的我也觉得还是有必要尽量维护一下。在有限的精力下又想要尽可能地维护一个软件系统让它不至于过快的消亡,最有效的方式大概还是尽可能减小它的复杂度和对环境(系统运行环境、第三方库等)的依赖性了。
对于一个网站来说,静态 HTML 页面模式应该是最符合这个条件的选择了,虽然并不是所有的网站都适合转换成我静态网页,但是博客系统其实是很合适的,特别是不在更新的博客,连动态评论系统其实也是不需要的。当然最基础的 HTML 页面归档其实在 WayBack Machine 里已经有了,不过我还是希望有自己的一份归档。
我最先尝试的是比较自动化的方案,Wordpress 有一个叫做 Simply Static 的插件专门用来做这件事情,不过在尝试过程中再次掉到“软件消亡”的大坑中。首先该插件与旧版本的 PHP 不兼容,于是我升级了 PHP 之后发现网站直接无法正常显示了,经过一番排查发现是我使用的博客主题本身太旧了无法兼容新的 PHP,并且该主题早已没有在维护和更新,在爱好者论坛找到一个非官方的更新版,经过一番合并工作总算是勉强恢复了网站原来的样子——当然其实这里我直接换一个主题也许是最便利的,但是既然是做归档工作,还是希望维持它本来的面貌。总之费了很大劲最后终于可以运行 Simply Static 插件了,结果发现它出了不少奇怪的错误,生成出来的静态页面也缺失了相当多的内容。由于我对 PHP 的了解完全为零,也不知道如何在服务端调试,折腾了一番之后只好放弃,改用手工归档的办法。
手工归档简而言之就是不通过 Wordpress
内部,而是从外部直接将渲染出来的网页抓取下来,这样得到的结果通常比较乱,需要做不少后期处理。网站抓取的工具有不少,最简单的是可以直接用命令行工具
wget 的 --mirror
模式,再加上其他一些比较细节的选项,例如:
wget --mirror --page-requisites --convert-links --adjust-extension --compression=auto \
--reject-regex '/feed' --no-if-modified-since --no-check-certificate \
--limit-rate=20K https://blog.pluskid.org
这里有介绍了几个最主要的命令行参数的用途。这样抓取的坏处
wget
并不知道这个网站的内部结构,只能沿着链接顺藤摸瓜,特别是对于原本是动态网站的情况,很有可能抓下来很多重复的或者不需要的内容,例如我在命令行参数里加入了
--reject-regex '/feed' 让它忽略所有跟 RSS feed
相关的链接,但是我们通常并不能事先预料到所有可能产生重复内容的链接,例如
Wordpress 博客系统在每一条用户评论里加了一个“回复”链接,wget
把每一个链接都当作一个新的页面,结果凡是有评论的页面都被重复下载了许多份。如果反复试验可能最终会得到一个比较合适的参数组合能下载到一个比较干净的版本,但是这样反复抓取有可能导致你的
IP 被该网站托管商加入黑名单(上面命令行里的
--limit-rate=20K 就是为了限制爬取速度以免不小心被禁)。
所以最后我还是放弃了 wget,采用了半自动的方法。首先我知道自己的博客的结构,例如我可以比较简单地拿到所有文章页面的链接,仅把文章页面下载下来——这时候我发现下载下来的页面都是空的,在浏览器里也只有登陆 Wordpress 之后才能稳定地正常打开页面,不知道是不是之前的 wget 已经触发了一定的保护机制的缘故。不够由于我现在只需要下载 HTML 页面本身,其它诸如图片、附件等内容可以直接从服务端 scp 下来,所以直接使用了浏览器里的批量下载插件 DownThemAll 来做了这件事情。
将 HTML
下载下来之后我直接打开其源文件,把所有页面共享的内容(头部、侧边栏等)手工抽取出来作为一个模版,然后用
Jekyll
这个静态网站生成器(当然也可以用其它类似工具)以该模版为基础建立了一个静态网站生成项目。这样我可以直接对该模版进行比较细致的修改,例如不需要评论系统之后所有
CAPTCHA 相关的 Javascript 代码都可以去掉。然后我选择性地保留了 HTML
里依赖的 CSS、图片等资源,直接将它们从服务端用 scp
拷贝到本地。最后用简单的 Python
脚本对下载下来的文章做一件正则表达式替换的批处理编辑(例如把所有动态 URL
/?p=123 替换成静态 URL
/archives/123,去掉“页面编辑”、“回复”等无效按钮等等),将处理结果放到
Jekyll 里就可以生成一个完整干净的静态网站了!
最后,serve 静态网页有一个小技巧,如果是用 Apache
服务器的话,可以使用 .htaccess
指定如下的重写规则,让你可以使用 /archives/123
这样的链接,而不需要带后缀
/archives/123.html。这样看起来会跟原来的(动态)网站更像,并且如果有从其它网站过来的旧链接也不会出现找不到页面的问题。
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^([^\.]+)$ $1.html [NC,L]
其实转化过程中的诸多不顺大都可以归因为软件消亡过程,例如如果是在多年前不在更新该博客的时候立刻就做这些事情的话可能会简单很多。静止不变的东西最终会逐渐消亡,唯有不断地改变和适应才能持续生存下去,突然觉得,也许生物的进化过程并不是为了去实现一个“终极进化形态”这样的目标,而只是为了不随时间消亡而必须采取的生存措施,进入了一场没有终点的赛跑。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK