

Detecting Rumors from Microblogs with Recurrent Neural Networks(IJCAI-16) - Le...
source link: https://www.cnblogs.com/justLittleStar/p/16448904.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
记录一下,很久之前看的论文-基于RNN来从微博中检测谣言及其代码复现。
1 引言
现有传统谣言检测模型使用经典的机器学习算法,这些算法利用了根据帖子的内容、用户特征和扩散模式手工制作的各种特征,或者简单地利用使用正则表达式表达的模式来发现推特中的谣言(规则加词典)。
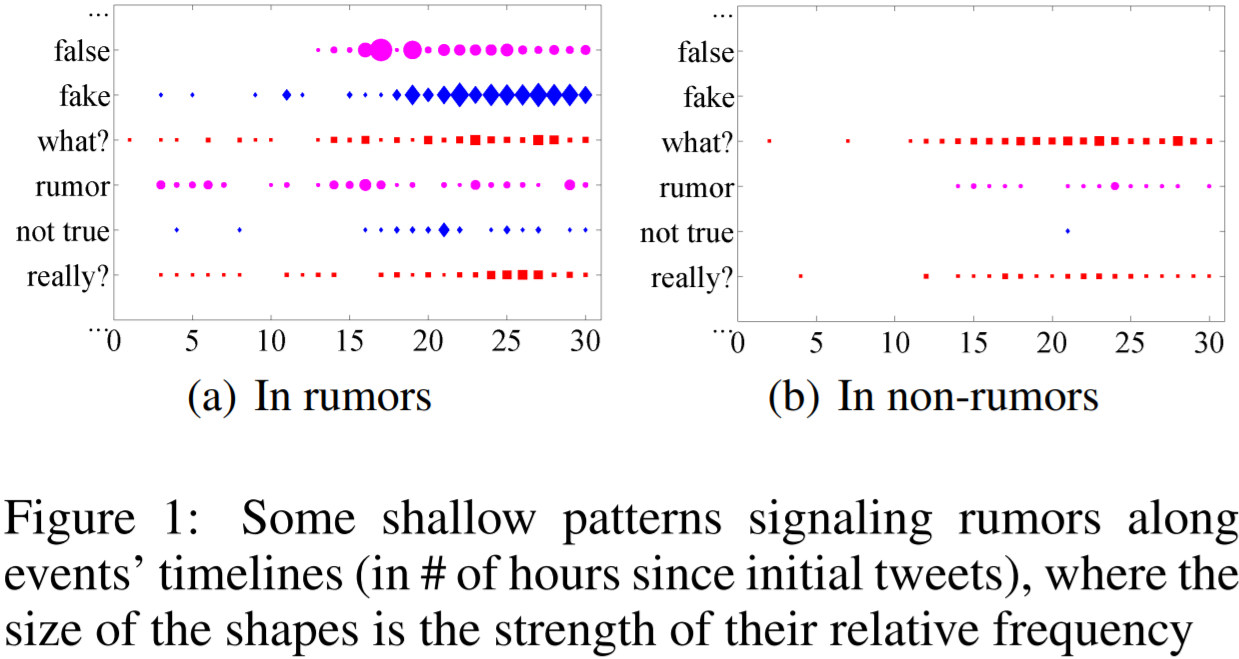
特征工程是至关重要的,但手工特征工程是繁琐复杂、有偏见和耗时费力的。例如,图1中的两个时间序列图描述了典型的谣言信号的浅层模式。虽然它们可以表明谣言和非谣言事件的时间特征(微博文本中关键词的时序变化),但这两种情况之间的差异对于特征工程来说既不明确,也不明显。
另一方面,深度神经网络在许多机器学习问题上已经显示出了明显的优势。本文利用了循环神经网络RNN来进行有效的谣言检测。RNN适用于处理社交媒体中的文本(retweet)流的序列性质 。这是因为RNN可以捕获谣言传播的动态时序特性。
本文提出基于RNN的方法,将谣言检测视为一个序列分类问题。具体地,本文将社会上下文信息(源微博的转帖文本或相关帖子文本)建模为可变长度的时间序列,然后用RNN来学习捕获微博相关帖子的上下文特征随时间的变化。
2.1 问题描述
-
基于事件的谣言检测(单个微博帖子都很短,上下文非常有限。Claim通常与一些与Claim相关的帖子有关)
-
事件集E={Ei}E={Ei}, Ei=(mi,j,ti,j)Ei=(mi,j,ti,j),事件EiEi由时间戳ti,jti,j内的帖子mi,jmi,j组成。
-
任务是判断每一个Event是谣言还是不是谣言
2.2 数据预处理-构造可变长度时间序列
将输入的序列中的post进行划分,从而将处理后的序列长度限定在在一定范围。
可将每个帖子建模作为一个输入实例,并构建一个序列长度等于帖子数的时间序列的用于RNN建模。然而,一个流行的事件可能会有成千上万个的帖子。我们只有一个输出单元(仅适用最终隐状态,有信息瓶颈问题)来指示在每个事件的最后一个时间步长中的类。通过大量的时间步长进行反向传播,而只有一个最后阶段的损失,计算代价高昂且无效的。(处理长序列时,RNN的BPTT存在的梯度消失问题会导致有偏的权重,即离Loss越远的时间步的梯度对参数的贡献越小,从而使其难以建模好长期依赖)
因此,为了妥善处理短时间内密集的帖子序列,本文将一批帖子构成一个时间间隔,并将它作为一个时间序列中的一个输入单元,然后使用RNN进行序列建模。简而言之,就是将原始的帖子序列按相对时间间隔划分成固定长度(例如k个)的子序列,其中子序列中帖子的数量不一定相同。
具体地,给定事件相关帖子的数据集,先将每条帖子视为输入实例,其序列长度等于帖子数量。进一步将帖子按照时间间隔进行批处理,视为时间序列中的单元,然后使用RNN序列进行建模,采用RNN序列的参考长度来构造时间序列。
动态时间序列算法:
1. 将整个事件线均分为N个internal,形成初始集合U0;
2. 遍历U0,删除没有包含帖子的internal,形成U1;
3. 从U1中选出总时间跨度最长的连续internal,形成集合U2(找到一个最长的时间序列);
4. 如果U2中internal的数量小于N且大于之前一轮,将internal减半,返回步骤1,继续分区(使最终internal数量接近N);
5. 否则,返回该总时间跨度最长的连续internal集合U2。
根据上述算法,其实现如下所示(针对常用的微博数据集,其每一个样本的原始信息存储在JSON文件中):
if len(max_inters) == 0:max_inters = temp_intersreturn max_intersif len(max_inters) == 0:max_inters = temp_intersreturn max_intersif non_empty == 0:output.append([]) # 空间隔不会记录其索引else:if tweet_list[-1][1] == start_time + time_interval:interval_post.append(tweet_list[-1][0]) # add the last tweetinter_index.append(inter)output.append(interval_post)start_time = start_time + time_interval # 更新间隔开始时间return output, inter_index |
以下代码为动态时间序列算法主函数,其中N为RNN的参考长度,即超参数:
k = 0pre_max_inters = [] # U_(k_1)while True:# Spliting series by the current time intervalk += 1interval_num = int(total_timespan / time_interval)output, inter_index = ConstructSeries(tweet_list, interval_num, time_interval)max_inters = GetContinueInterval(inter_index) # maximum continue interval indexif len(pre_max_inters) < len(max_inters) < N:time_interval = int(time_interval * 0.5) # Shorten the intervalspre_max_inters = max_intersif time_interval == 0:output = output[max_inters[0]:max_inters[-1] + 1]breakelse:output = output[max_inters[0]:max_inters[-1] + 1]breakreturn output</pre>k = 0pre_max_inters = [] # U_(k_1)while True:# Spliting series by the current time intervalk += 1interval_num = int(total_timespan / time_interval)output, inter_index = ConstructSeries(tweet_list, interval_num, time_interval)max_inters = GetContinueInterval(inter_index) # maximum continue interval indexif len(pre_max_inters) < len(max_inters) < N:time_interval = int(time_interval * 0.5) # Shorten the intervalspre_max_inters = max_intersif time_interval == 0:output = output[max_inters[0]:max_inters[-1] + 1]breakelse:output = output[max_inters[0]:max_inters[-1] + 1]breakreturn output</pre> |
2.3 模型结构(two-layer GRU)
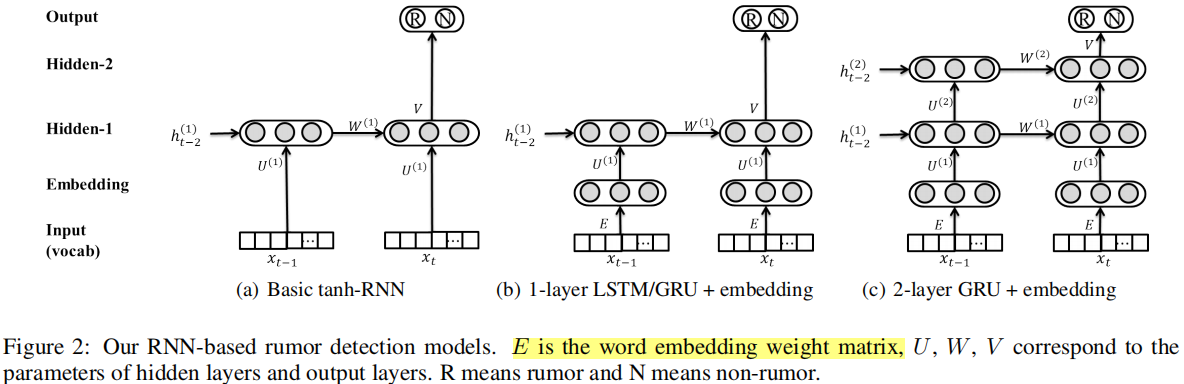
首先,将每一个post的tf-idf向量和一个词嵌入矩阵相乘,这等价于加权求和词向量。由于本文较老,词嵌入是基于监督信号从头开始学习的,而非使用word2vec或预训练的BERT。
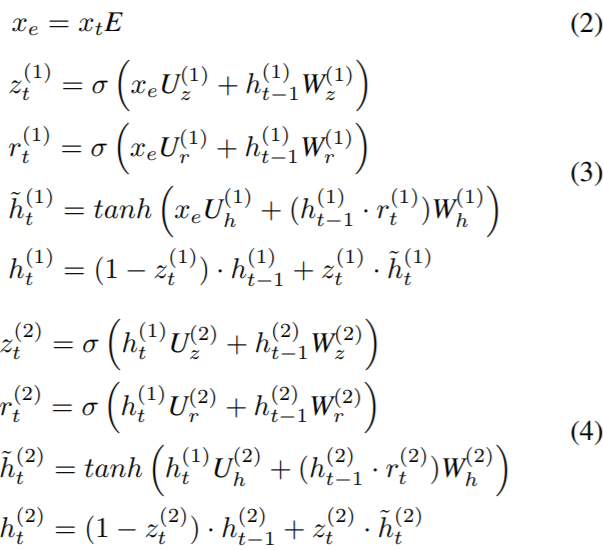
以下是加载数据的部分的代码。为了便于实现,这里并没有使用torch自带的dataset和dataloader,也没有没有对序列进行截断和填充。
def get_wordindices(self):return [torch.from_numpy(inter_text) for inter_text in self.text_data]def get_wordindices(self):return [torch.from_numpy(inter_text) for inter_text in self.text_data] |
模型代码:本文的模型对每一个时间间隔内的post的embedding直接使用了最大池化操作。
def forward(self, x):return torch.max_pool1d(x, kernel_size=x.shape[2])def forward(self, x):return torch.max_pool1d(x, kernel_size=x.shape[2]):Params:dim_in (int): post的初始输入特征维度 kdim_word(int): word嵌入的维度dim_hid (int): GRU hidden unitdim_out (int): 模型最终的输出维度,用于分类"""super(GRU2_origin, self).__init__()self.word_embeddings = nn.Parameter(nn.init.xavier_uniform_(torch.zeros(dim_in, dim_word, dtype=torch.float, device=device), gain=np.sqrt(2.0)), requires_grad=True)# GRU for modeling the temporal dynamicsrnn_num_layers = 2self.MaxPooling = GlobalMaxPool1d()self.GRU = nn.GRU(dim_word, dim_hid, rnn_num_layers)self.H0 = torch.zeros(rnn_num_layers, 1, dim_hid, device=device)self.prediction_layer = nn.Linear(dim_hid, dim_out)nn.init.xavier_normal_(self.prediction_layer.weight)def forward(self, text_data):batch_posts = []for idx in range(len(text_data)):# words_indices is a sparse tf-idf vector with N * 5000 dimensionwords_indices = text_data[idx].to(device)tmp_posts = []for i in range(words_indices.shape[0]):word_indice = torch.nonzero(words_indices[i], as_tuple=True)[0]if word_indice.shape[0] == 0:word_indice = torch.tensor([0], dtype=torch.long).to(device)words = self.word_embeddings.index_select(0, word_indice) # select out embeddingsword_tensor = words_indices[i][word_indice].unsqueeze(dim=0) # select out weightspost_embedding = word_tensor.mm(words).squeeze(dim=1)tmp_posts.append(post_embedding)# Interval中的post batch取平均 (矩阵乘法)tmp_embeddings = torch.cat(tmp_posts, dim=0).unsqueeze(1)batch_embedding = self.MaxPooling(tmp_embeddings.transpose(0, 2)) # transpose(0, 2)batch_posts.append(batch_embedding.squeeze(1).transpose(0, 1))x = torch.cat(batch_posts, dim=0)gru_output, _ = self.GRU(x.unsqueeze(1), self.H0)return self.prediction_layer(gru_output[-1]) # Using the last hidden vector of GRU |
后续的完整的数据加载、模型初始化、训练和评估,可自行添加。
模型训练设置:
- 使用TF-IDF来获取post的初始文本表示
- AdaGrad算法进行参数更新
- 根据经验,将词汇量大小设为k=5000,待从头学的词嵌入维度为100,隐藏单元的尺寸为100,学习率为0.5
论文中报告的实验结果(复现的结果与其相差不大):
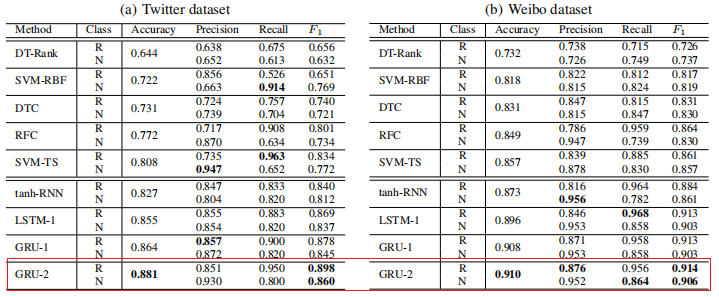
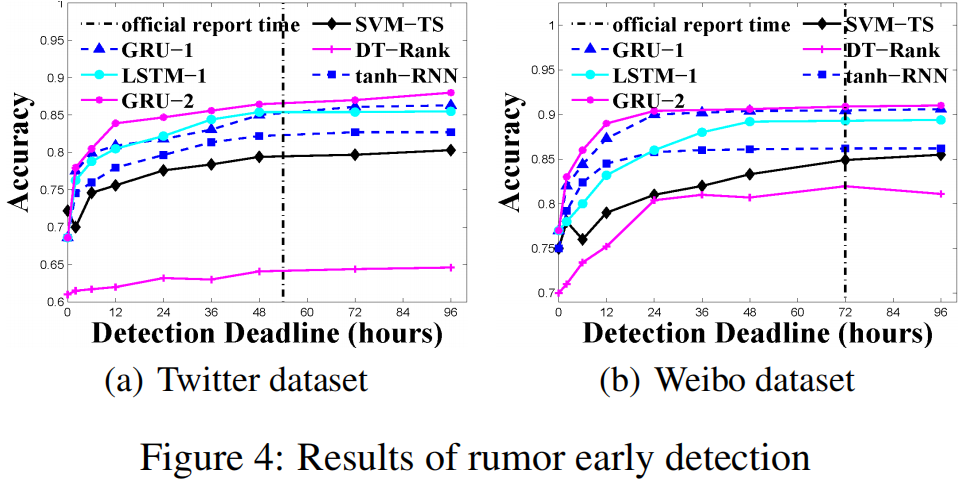
这篇文章算是将深度学习用于虚假信息检测的开山之作,开始了利用深度网络来自动提取具备判别性的高阶特征的范式,后续很多文章都是在此基础上改进的。
由于文章较老,所以在目前看,待改进的点其实挺多的。首先要注意,原始的TF-IDF特征一般不能在全局数据上提取(训练集、验证集和测试集,暂不考虑半监督的情况),相同的词的在验证集和测试集的TF-IDF特征和训练集取同样的值。而对于新出现的词,取默认值。推广到一般情况,如果提取特征时,不区分训练测试,或许使用了相应特征的对比方法取得的结果过于乐观,并不符合实际情况。
此外,可以考虑文本特征的获取、序列的层次化建模、注意力机制、其他特征的使用(用户信息、传播结构特征)、外部知识的引入(知识图谱)、非线性传播结构的利用、多任务学习(结合立场分类)等等。
值得注意的是,当算法实际应用时,并不是越复杂的模型的效果就越好,而且需要考虑实际的业务需求和数据。有时候,或许假设简单、模型结构简单的算法或许在大量人工特征的引入和大量数据的支持下,也能取得不错的效果,毕竟数据决定算法的上限。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK