

零样本学习超越CLIP!谷歌提出首个多模态稀疏化模型LIMoE,还能降低计算成本
source link: https://www.51cto.com/article/711451.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
零样本学习超越CLIP!谷歌提出首个多模态稀疏化模型LIMoE,还能降低计算成本-51CTO.COM

本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
多模态模型常见,但是基于稀疏化的还是头一个。
谷歌带来最新成果LIMoE,首次将稀疏化方法用在了图像文本混合模型上。
要知道,随着大模型参数呈指数级增加,训练成本也是一路飙升。
所以如何降低训练成本,成为了目前学界重点关注的一个问题。
谷歌想到的办法,不是拼硬件,而是从模型本身入手。
利用稀疏化的方法,让每次输入只需激活部分网络就能完成任务。
它们在模型内部设置了很多“专家”,每个“专家”只需处理对应部分的输入,根据任务情况按需使用“专家”就好。
这样一来,尽管模型容量很大,但是计算成本并没有暴增。
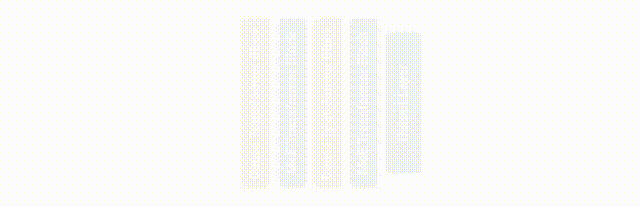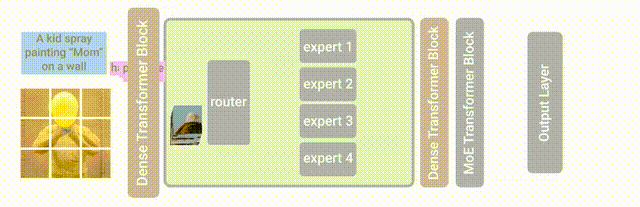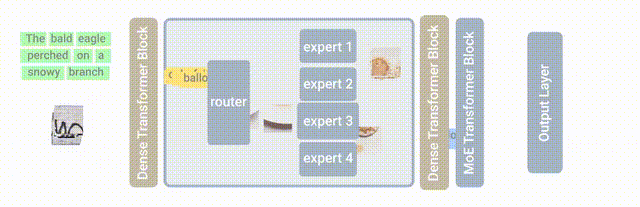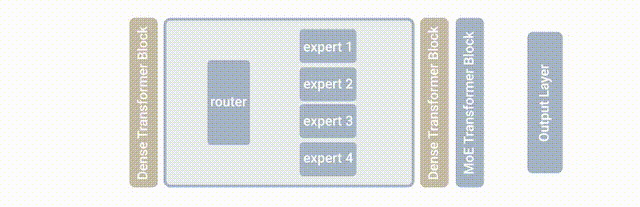
而且还不会降低性能。
新方法LIMoE零样本学习任务中,可是直接超越了CLIP。
怪不得网友高呼:
快分享给我们API!
让不同“专家”处理不同任务
对于深度学习来说,能同时处理文本图像任务其实已经不稀奇。
不过过去常见的多模态学习方法,往往是单个输入就需要激活整个网络。
谷歌这次提出的新方法,最大亮点就是首次在这一领域采用了稀疏化模型。
稀疏化的方法便是无需让整个模型来处理所有的输入。
通过对神经网络进行划分,它让神经网络也“专业对口”,不同的子模型只处理固定类型的任务或数据。
但也不是完全割裂开来,模型内部仍有可共享的部分。
此次基于的模型是MoE(Mixture-of-Experts layer),它被称为专家混合模型。
也就是在Transformer架构的基础上,加设了“专家层”。
它是一个并行的FNN,取代了原本的前馈网络。
这里的“专家”,也就是模型内部的不同子模型。
每个子模型专门用于不同的输入。
每一层中的专家由门控网络控制,该网络根据输入数据激活专家。
对于每个标记,门控网络选择最合适的专家来处理数据。
此次新提出的LIMoE,其实就是让MoE能同时处理图像文本。
具体来看,就是让LIMoE进行对比学习。
在利用大量图像-文本对训练时,网络内部的图像模型提取图像表示,文本模型提取文本表示。
针对相同的图像-文本对,模型会拉近图像和文本表示的距离。
反之,对于不同的图像-文本对,则会让相应的表示彼此远离。
这样一来的直接好处,就是能实现零样本学习。
比如一张图像的表示更接近文本“狗”的表示,那么它就会被归类为狗。
这种思路可以扩展到数千种情况。
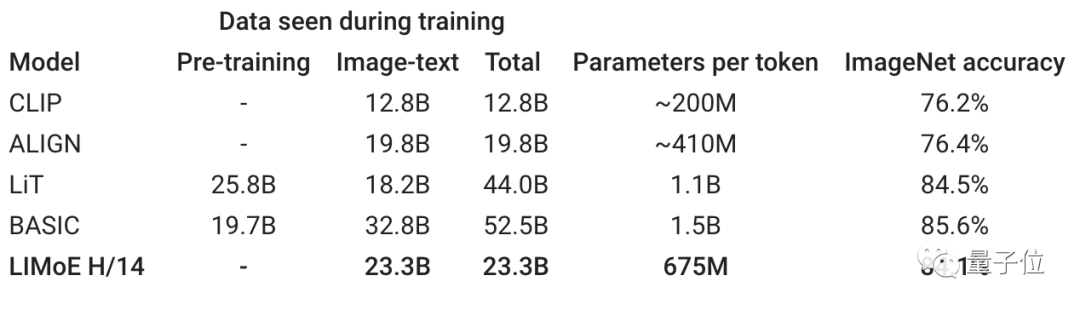
实际上,CLIP和ALIGAN采用的都是这个思路,它们在ImageNet数据集上的精度分别是76.2%、76.4%。
而LIMoE-L/16可以达到78.6%,已经超过了CLIP。
未经过预训练的LIMoE H/14则能达到84.1%的精度。
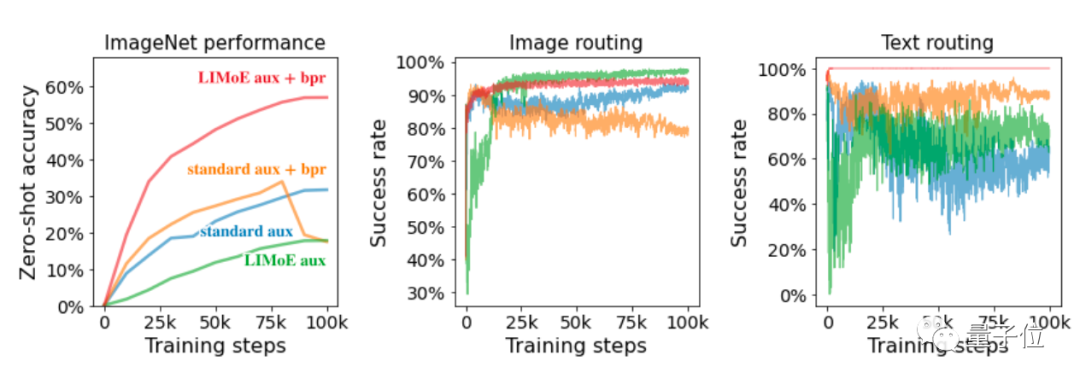
而在LIMoE的专家层中,谷歌表示还发现了一些有趣的现象。
比如在训练设置中,图像标记比文本标记要多很多,因此所有专家都会在在任务中多少处理些图像。
只不过有的会主要处理图像,有的主要处理文本,或者二者兼具。
还有在大多数情况下,都会有一个专家来处理所有包含文本表示的图像patch。

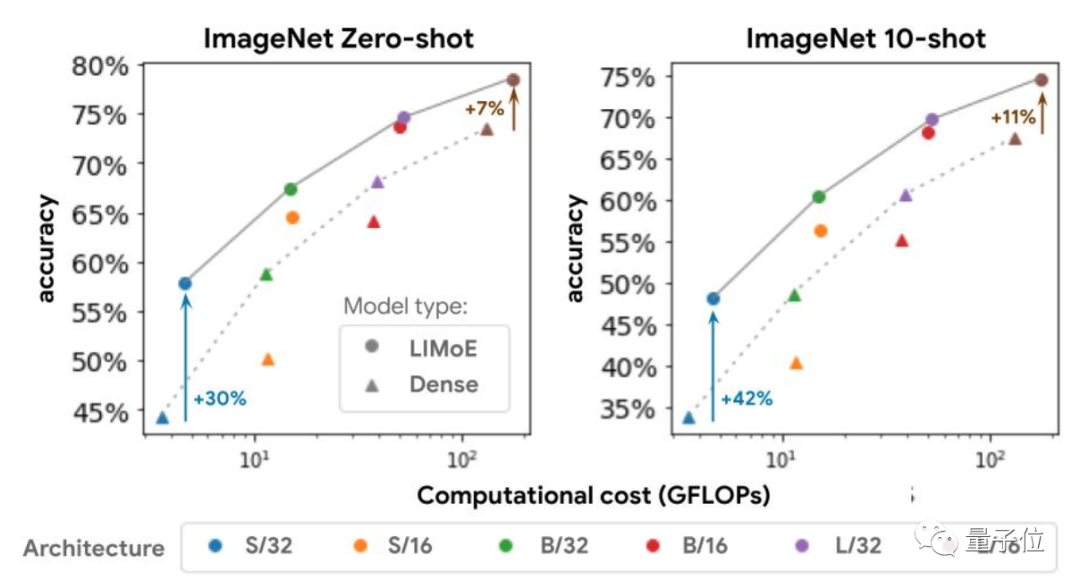
除了性能上的提升,使用稀疏化模型的好处还体现在降低计算成本上。
因为“多专家”的模式意味着,尽管多设了很多子模型,模型容量显著增加,但是实际计算成本并没有明显变化。
如果一次任务中只使用了一个子模型,那它的成本和标准Transformer的差不多。
比如LIMoE-H/14总共有5.6B参数,但是通过稀疏化,它只会使用每个token的675M参数。
One More Thing
稀疏化模型一直是谷歌深度研究的一个方向,已经提出了MoE、GLaM在内的多个模型。
这次LIMoE也不是谷歌第一次魔改MoE。
去年6月,他们提出了V-MoE,是一种新型的视觉架构,今年已将全部代码开源。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK