

Kafka 的架构与设计概览
source link: https://airgiser.github.io/2019/03/15/kafka-architecture/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Kafka 是一个开源的分布式流处理平台,由 Scala 和 Java 编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。
Kafka 的持久化层本质上是一个“按照分布式事务日志系统设计的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据时非常有价值。此外,Kafka 可以通过 Kafka Connect 连接到外部系统(用于数据输入/输出),并提供了 Kafka Streams(一个 Java 流式处理库)。
Kafka 主要的设计目标如下:
- 高吞吐
- 低延迟
- 提供持久化能力,并支持常数时间复杂度的访问性能。
- 同时支持离线数据处理和实时数据处理。
- 支持分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 容错性
Kafka 架构
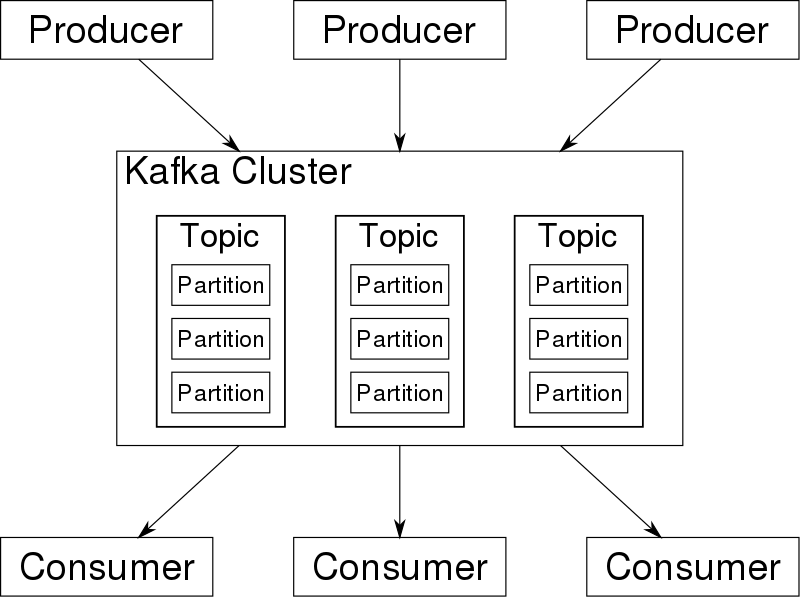
Kafka 架构中一般包含由多个 Broker 组成的 Kafka 集群,以及多个 Producer 和多个 Consumer。其中涉及的一些关键概念如下:
- Broker: Kafka 集群包含一个或多个服务器,这些服务器被称为 Broker。
- Topic: 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。也可以将每一个 Topic 理解为不同的消息队列。不同的 Topic 物理上将分开存储。
- Partition: Parition 是物理上的概念,每个 Topic 包含一个或多个 Partition。这些 Partition 可能分布在不同的 Broker 上。
- Producer: 消息的生产者,使用 push 模式将消息发布到 Broker。
- Consumer: 消息的消费者,使用 pull 模式从 Broker 订阅并消费消息。
- Consumer Group: 每个 Consumer 属于一个特定的 Consumer Group。一条消息在一个 Consumer Group 内只能被消费一次,但不同的 Consumer Group 可同时消费这一消息。
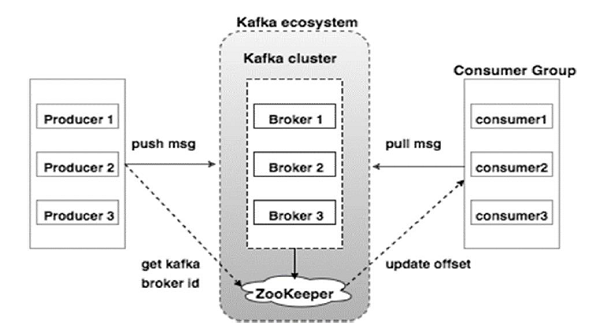
Broker 和 ZooKeeper
Kafka 集群通常会由多个 Broker 组成以实现负载均衡。Broker 上存储了日志的 Partition,一个 Topic 的各个 Partition 往往会分布在不同的 Broker上。
Broker 是无状态的,所以 Kafka 集群会通过 ZooKeeper 来管理状态和配置,选举 Leader,以及在 Consumer Group 发生变化时维持负载均衡等。
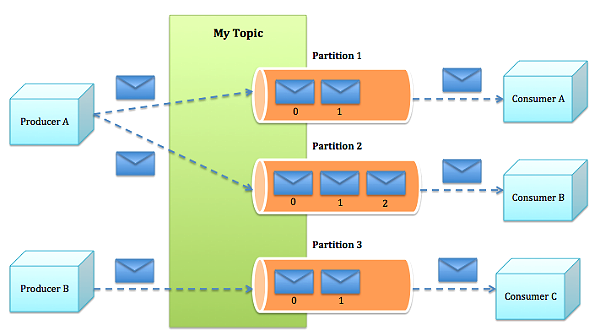
Topic 和 Partition
Topic 在逻辑上可以认为是一个队列,每一条消息都需要指定 Topic,可以理解为需要指定这条消息应该被放入哪个队列中。
Topic 会被分成一个或多个 Partition,每个 Partition 在物理上对应一个文件夹,该文件夹下存储这个 Partition 的所有消息和索引文件。由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现并行处理。这样 Kafaka 的吞吐率就有机会得到线性提升。
如果 Partition 没有备份,一旦一个或多个 Broker 宕机,则该 Broker上的所有 Partition 都无法继续提供服务。若该 Broker 永远无法恢复,则其上的数据将丢失。为了保障 Kafka 集群的高可用性及数据持久化目标,就需要引入 Replication 机制。
为了更好的做负载均衡,Kafka 应尽量将所有的 Partition 均匀分配到整个集群上。同时为了提高 Kafka 的容错能力,也需要将同一个 Partition 的 Replica 尽量分散到不同的机器。
引入 Replication 机制之后,同一个 Partition 可能会有多个 Replica,而这时需要在这些 Replication 之间选出一个 Leader,Producer 和 Consumer 只与这个 Leader 交互,其它 Replica 作为 Follower 从 Leader 中复制数据。
Kafka 在 ZooKeeper 中动态维护了一个 ISR(in-sync replicas),这个 ISR 里的所有 Replica 都跟上了 Leader。在 Leader 宕机需要重新选举 Leader 的时候,只有 ISR 里的成员才有被选为 Leader 的可能。这样就避免了需要等待最慢的 Broker 的情况。
一个 Partition 会按顺序分成多个 Segment 文件,每个 Segment 文件以该 Segment 第一条消息的 offset 命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个 segment 下包含的 log entry 的 offset 范围。Segment 文件实际上是一个 log entry 序列,一个 log entry 对应一条消息,其中包含了消息的长度、校验码及消息体等信息。
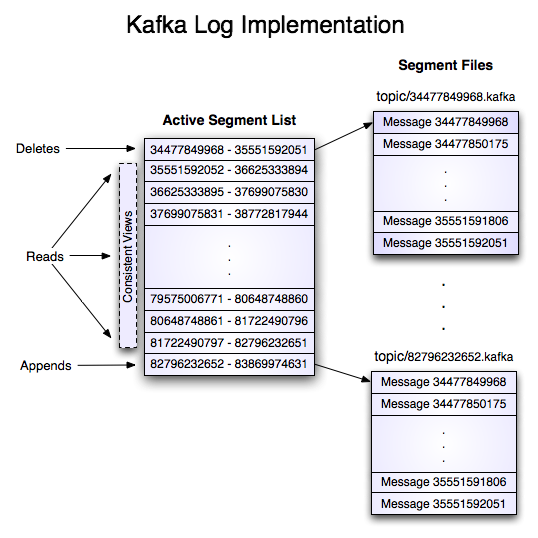
因为每条消息都是被追加到对应的 Partition 中,属于顺序写磁盘,因此效率非常高(顺序写磁盘效率可能比随机写内存还要高,这保证了 Kafka 的高吞吐率)。
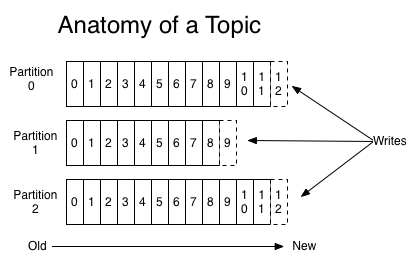
因为磁盘限制,不可能永久保留所有数据,所以有时需要删除旧数据,删除的时候是以 Segment 文件为单位进行删除的。
Producer
Producer 在发送消息到 Broker 的时候,会依据 Paritition 机制来选择将其存储到哪一个 Partition。合理的 Partition 机制可以使所有消息均匀分布到不同的 Partition 中,从而实现负载均衡。不同的消息可以并行写入位于不同 Broker 的不同 Partition 里,从而极大地提高了吞吐率。
在发送一条消息时,可以指定这条消息的 key,Producer 再根据这个 key 和 Partition 机制来判断应该将这条消息发送到哪个 Parition。
Producer 可以一次性发送多条消息,通过批量发送既可以减少了网络传输的 Overhead,提高传输效率,又可以提高了写磁盘的效率,从而提高吞吐量。在批量发送时,还可以将一批消息压缩后进行传输,从而更大程度提高网络传输效率。Broker 接收消息后,并不直接解压缩,而是直接将消息以压缩形式持久化到磁盘,Consumer 在拿到数据之后再解压缩。
Consumer 和 Consumer Group
使用 Consumer high level API 时,同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。
用 Consumer Group 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的 Topic。
实际上,Kafka 的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用 Storm 这种实时流处理系统对消息进行实时在线处理,同时使用 Hadoop 这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的 Consumer 属于不同的 Consumer Group 即可。
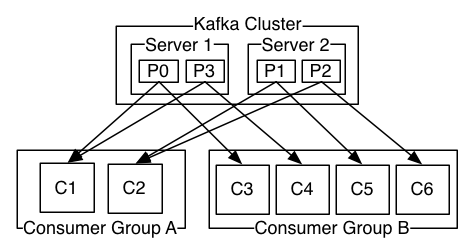
Kafka 会为每一个 Consumer Group 保留一些 metadata 信息——当前消费的消息的位置,也即 offset。这个 offset 由 Consumer 控制。正常情况下 Consumer 会在消费完一条消息后递增该 offset。当然,Consumer 也可将 offset 设成一个较小的值,重新消费一些消息。
因为 offset 由 Consumer 控制,所以 Kafka Broker 是无状态的,它不需要标记哪些消息被哪些 Consumer Group 消费过,也不需要通过 Broker 去保证同一个 Consumer Group 只有一个 Consumer 能消费某一条消息,因此也就不需要锁机制,这也为 Kafka 的高吞吐率提供了有力保障。
消息传输的语义
消息传输的语义有以下几种可能:
At most once — 消息可能会丢,但绝不会重复传输。
At least one — 消息绝不会丢,但可能会重复传输。
Exactly once — 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
消息的发布
当 Producer 向 Broker 发送消息时,一旦这条消息被 commit,Replication 机制可以它就不会丢。但是如果 Producer 发送数据给 Broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit。虽然 Kafka 无法确定网络故障期间发生了什么,但是 Producer 可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了 Exactly once。
在 0.11.0.0 版本之前,该 Feature 还未实现,因此重试(未收到响应时)可能会导致同一消息多次写入日志。在 0.11.0.0 版本之后 Kafka 已提供相应的选项可以保证Exactly once。目前在默认情况下,一条消息从 Producer 到 Broker 确保了 At least once,另外也可通过设置 Producer 异步发送实现 At most once。
消息的消费
Consumer 在从 Broker 读取消息后,可以选择 commit,该操作会在 Zookeeper 中保存这个Consumer 在对应的 Partition 中读取的消息的 offset。当 Consumer 下一次再读该 Partition 时会从下一条开始读取。如未 commit,下一次读取的开始位置会跟上一次 commit 之后的开始位置相同。当然可以将 Consumer 设置为 autocommit,即 Consumer 一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那 Kafka 是确保了 Exactly once。
但实际使用中应用程序并非在 Consumer 读取完数据就结束了,而是要进行进一步处理,而数据处理与 commit 的顺序在很大程度上决定了消息传输的语义:
- 读完消息先 commit 再处理消息。这种模式下,如果 Consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once。
- 读完消息先处理再 commit。这种模式下,如果在处理完消息之后 commit 之前 Consumer crash 了,下次重新开始工作时还会处理刚刚未 commit 的消息,实际上该消息已经被处理过了。这就对应于 At least once。在很多使用场景下,消息都有一个主键,对应的消息处理往往具有幂等性,即多次处理这一条消息跟只处理一次是等效的,那就可以认为和 Exactly once 是一样的效果。
- 如果一定要做到 Exactly once,就需要协调 offset 和消息处理后的输出。经典的做法是引入两阶段提交。如果能让 offset 和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,Consumer 拿到数据后可能把数据放到 HDFS,如果把最新的 offset 和数据本身一起写到 HDFS,那就可以保证数据的输出和 offset 的更新要么都完成,要么都不完成,间接实现 Exactly once。(目前就 high level API 而言,offset 是存于 Zookeeper 中的,无法存于 HDFS,而 low level API 的 offset 是由自己去维护的,可以将之存于 HDFS 中)
https://en.wikipedia.org/wiki/Apache_Kafka
https://kafka.apache.org/documentation
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK