

计算机网络笔记-网络层
source link: http://cbsheng.github.io/posts/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%E7%AC%94%E8%AE%B0-%E7%BD%91%E7%BB%9C%E5%B1%82/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
计算机网络笔记-网络层
因特网的网络层是提供了单一的服务,称为尽力而为服务。网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。网络层不提供服务质量的承诺。
因特网的网络层有三个主要的组件:
- IP协议 (数据包格式、编址规则、分组处理规则)
- 选路协议 (路径选择、 RIP,OSPF,BGP)
- 差错和信息报告协议(ICMP) (差错报告,路由器指令)
1. IP协议
IP数据报的格式
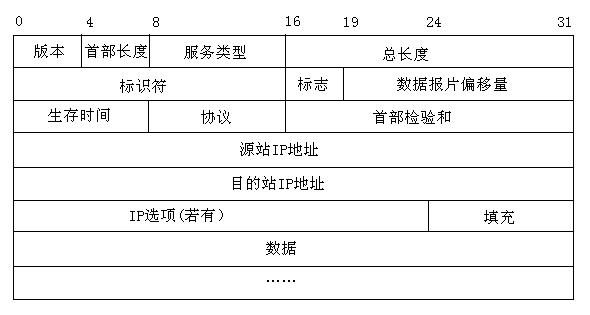
版本号(4位): IP协议版本。(IPV4/IPV6) 首部长度(4位): 该字段最大值为15。首部长度字段所表示数据的单位是32位字(4个字节),首部长度字段最小值为5(0101),相当于5*4=20字节。所以15*4=60字节就是首部的最大长度。因此IP数据报的数据部分永远在4字节的整数倍时开始,所以通过该字段可以得到部分的起始位置。 服务类型(8位): 服务类型(TOS)用来是区别不同类型的IP数据报(例如:低时延、高吞吐量或可靠性的数据报)。 总长度(16位): 首部和数据之和的长度。 标识符(16位): IP软件维持一个计数器,每产生一个数据报,计数器加一并赋值给标识字段。标识并不是序号。两个不同的IP数据报这个字段的值不一样。 标志(3位): 目前只有两位有意义。MF=1:还有分片。MF=0:分片的最后一个。DF=1:不能分片。DF=0:允许分片。 片偏移(13位): 标识分片之后的数据报在未分片的数据报的哪个位置开始。片偏移以8个字节为偏移单位。也就是每个分片长度是8字节的整数倍。 生存时间(8位): TTL表明数据报在网络中的寿命。每经过一个路由器就会被减一,如果在到达目的主机前就为零就会被丢弃。 协议(8位): 指出数据报携带的数据是使用何种协议,以便使目的主机的IP层知道如何上交给哪个处理过程。 检验和(16位): IP层只对IP首部进行检验,不检验数据部分。 源IP地址或目的IP地址(32位): 略。 选项: 选项字段允许IP首部被扩展。当添加选项之后整个首部不足4字节的整数倍时要进行填充。这个字段在IPV6已经不再采用了。
IP数据报为什么会分片
并不是所以的链路层协议度能承载相同长度的网络层分组。 一个链路层帧能承载的最大数据量叫做最大传输单元(MTU)。例如:以太网数据字段最大长度是1500B。
所以当数据报由于长度超过网络的MTU时就必须进行分片。为坚持使网络内核保持简单的原则,IPV4的设计者决定将数据包的重新组装工作放到端系统中,而不是放在网络路由器中。
为了让目的主机执行这些重装任务,IPV4设计者将标识符、标志和片偏移字段放在IP数据报中。在接收方数据报的有效载荷仅当IP层已完全重构为初始IP数据报时,才被传递给运输层。
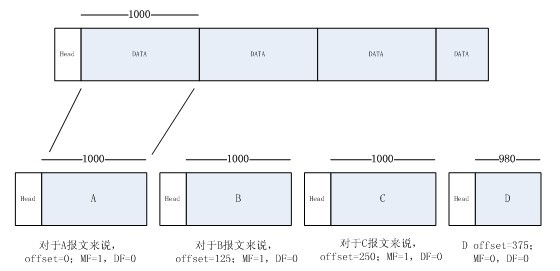
分片可能引起致命的DoS攻击,即攻击者发送一系列古怪的片。IPV6从根本上废止了分片,从而简化了IP分组的处理。
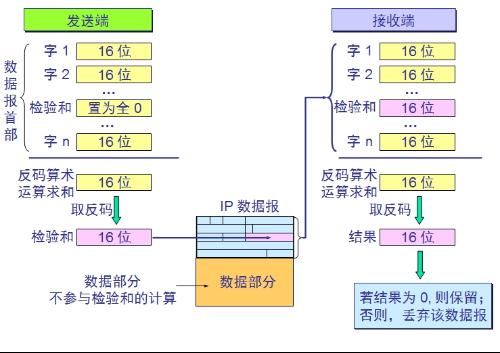
检验和的求法
在求检验和中需要用到反码算术运算。
反码算术运算是从低位到高位逐列进行计算,若最高位相加后产生进位,则最后得到的结果要加1,然后再求结果的反码。
检验和的计算方法: 在发送方,先把IP数据报首部划分为许多16为字的序列,并把检验和字段置零。用反码算术运算把所有16位字相加后,将得到的和的反码写入检验和字段。 在接受方,收到数据报后,将首部的所有16位字再使用反码算术运算相加一次。将得到的和取反码,即得出接收方的检验和的计算结果,若首部未发生变化,则此结果必为0。否则则认为出差错,将数据包丢弃。注意,IP的差错检测只检验首部,不检验数据部分。
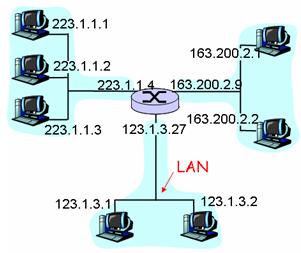
IPV4编址
因特网的编址是以接口为主的。 主机与物理链路之间的边界叫做接口。 路由器与它的任意一条链路之间的边界页叫做接口。
因此,一个IP地址在技术上是与一个接口相关联的,而不是与包括该接口的主机或路由器相关联的。
在全球的因特网中,每台主机和路由器上的每个接口都必须有一个全球唯一的IP地址。这些地址不能随意方式自由选择。一个接口的IP地址的组成需要由其链接的子网来决定。
因特网的地址分配策略被称为无类别域间选路(CIDR)。 其形式如:a.b.c.d/x。地址中的x最高比特构成来IP地址的网络部分,并且经常被称为该地址的前缀(或网络前缀)。
在采用CIDR之前,IP地址的网络部分被限制长度为8,16,24等比特,这三类长度对应的网络分别被称为A,B,C类网络,所以这种编址的方案称为分类编址。 要求一个IP地址的网络部分正好为1,2,或3个字节,已经在支持迅速增加的具有小、中规模子网的组织数量方面出现了问题。所以最后推出来CIDR。
由于在CIDR中使用了网络前缀,所以路由表(用于选路)中每个项目就由“网络前缀:下一跳地址”组成。这样的话,路由器为某个到来的分组中的IP地址查找路由表时就可能得到不止一个匹配结果了。 例如IP地址D为206.0.71.130, 路由表中有两项分别为1. 206.0.68.0/22:下一跳地址。 2. 206.0.71.128/25:下一跳地址。 当D 和 11111111 11111111 11111100 00000000 相与时就 = 206.0.68.0/22 当D 和 11111111 11111111 11111111 10000000 相与时就 = 206.0.71.128⁄25
为了解决这个问题,在路由表查找时候采用最长前缀匹配的方法从多个匹配结果中选择其一。所以对应上面的例子就会选择后者。
考虑到性能问题,在路由器中查表的操作需要很快,不能造成性能的瓶颈。那么可以利用二叉线索树去查找路由表。为了简化二叉树的结构,可以使用每个IP地址的唯一前缀去构造。

2. 选路协议
因特网采用的路由选择协议主要是自适应的(即动态的)、分布式路由选择协议。原因是因特网的规模非常的大,而且很多单位是不愿外界去了解自己的单位网络的布局细节和采用的路由选择协议。所以,因特网将整个互联网划分为许多较小的自治系统(AS)
一个AS可以使用多种内部路由选择协议和度量,但是一个AS对其他AS表现出的是一个单一的和一致的路由选择策略。
在目前的因特网中,一个大的ISP就是一个自治系统。因特网把路由选择协议划分为两大类:
- 内部网关协议IGP。如RIP, OSPF。
- 外部网关协议EGP。如BGP。
一个AS内的一台或多台路由器有另外的任务,就是负责向本AS之外的目的地转发分组。这些路由器被称为网关路由器。
自治系统之间的路由选择也叫做域间路由选择,而在自治系统内部的路由选择叫域内路由选择。
RIP协议
RIP是一种分布式的基于距离向量的路由选择协议。
关于RIP的一些重要的概念:
- RIP要求每个路由器度维护从自己到每一个目的网络的距离记录(即距离向量)。
- RIP的“距离”也称为“跳数“。
- RIP允许一条路径最多只能包含15个路由器,超出来就相当与不可达。可见RIP值适用于小型互联网。
- RIP选择一个具有最少路由器的路由,哪怕还存在一条高速低时延但路由器较多的路由。
RIP的特点:
- 仅和相邻路由器交换信息。只要两个路由器之间不需要经过另一个路由器就说明是相邻的。
- 路由器交换的信息是当前本路由器的路由表。
- 按固定时间间隔交换路由信息。
当相邻路由器在交换路由表信息时,也就是本路由器根据相邻路由器发来的路由表进行更新自己的路由表时,更新的原则是找出每个目的网络的最短距离。这种算法又称为距离向量算法。
路由器上执行的距离向量算法的步骤:
- 修改地址为X的相邻路由器发来的RIP报文中的所有路由项目:把下一跳改为X,把距离值增一。
- 判断,若本地路由表没有目的网络N,则添加。
- 判断,若本地路由表有目的网络N,则比较下一跳是否相同。相同的话就用新的路由项目覆盖掉本地的项目。
- 判断,若本地路由表有目的网络N,而且下一跳也不相同时,则在两者中选择距离最少的。
- 判断,若距离大于15的路由项目记为不可到达。
RIP协议的报文结构:
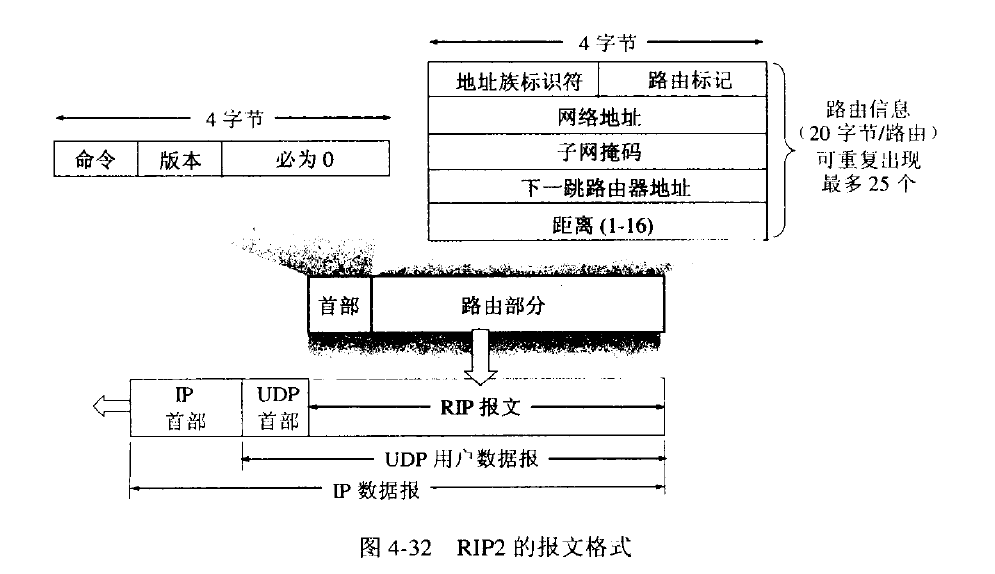
报文结构说明:
- 命令字段=1表示请求路由信息,=2表示对请求路由信息的响应或未被请求而发出的路由更新报文。
- “必为0”的部分是为了4字节对齐。
- 地址族标识符字段用来标志所使用的地址协议。路由标记填入自治系统号ASN。
- 一个RIP报文最多可包括25个路由,因而报文最大长度是4+20*5=504字节。
RIP协议的优缺点: - 优点是协议实现简单,开销较小。 - 缺点是协议对于好消息传播得快,而坏消息传播得满。网络出现故障的传播时间往往需要数分钟。
OSPF协议
开放最短路径优先OSPF是为了克服RIP的缺点而开发出来的。它使用的是分布式的链路状态协议,而不是RIP的距离向量协议。
OSPF与RIP的区别:
- 使用洪泛法向本自治系统中所有路由器发送信息。
- 发送的信息就是与本路由器相邻的所有路由器的链路状态。所谓链路状态就是说明本路由器都和哪些路由器相邻以及该链路的度量(表示费用、距离、时延、带宽等),有时称这个度量为代价。
- 只有当链路状态发生变化时,路由器才向所有的路由器用洪泛法发送此信息。
由于各路由器之间频繁地交换链路状态信息,因此所有的路由器最终都能建立一个链路状态数据库,这个数据库实际就是全网的拓扑结构图。 每个路由器使用链路状态数据库中的数据构造出自己的路由表。
OSPF将一个自治系统再划分为若干个称为区域的更小的范围。这样做就可以有效的减少利用洪泛法交换链路状态信息时网络上的通信量。
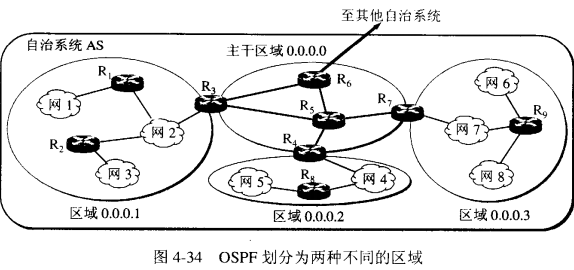
不同的区域使用32位的的区域标识符进行区别。一个区域内的路由器最好不要超过200个。 上图的R3, R7, R4被称为区域边界路由器。在主干区域内的所有路由器都称为主干路由器。R6称为自治系统边界路由器。 一个主干路由器可以同时是区域边界路由器。
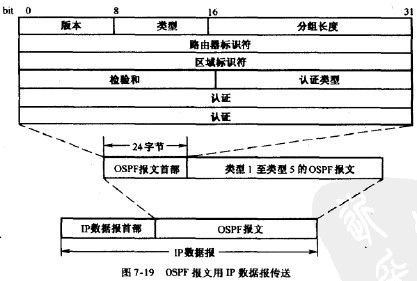
OSPF报文的结构:
BGP协议
RIP、OSPF与BGP
RIP使用的是UDP,OSPF使用的IP,而BGP使用的是TCP。
RIP需要周期性地与邻站交换信息才能使路由信息及时得到更新,所以可以使用不可靠的UDP,并且UDP开销小。
OSPF使用可靠的洪泛法,直接使用IP好处是灵活性号和开销更小。
BGP需要交换整个的路由表和更新信息,所以需要TCP提供可靠的交付服务。
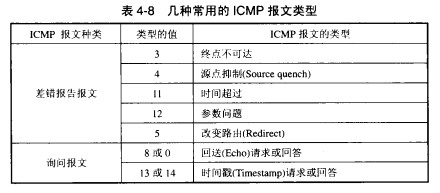
3. 差错和信息报告协议(ICMP)
ICMP协议用于主机和路由器彼此交互网络层信息。ICMP报文的种类有两种:差错报告报文和询问报文。
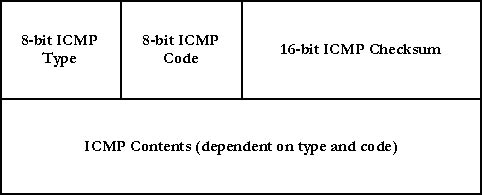
ICMP通常被认为死IP的一部分,但从体系上讲它是位于IP之上,因为ICMP报文是承载在IP分组中的。这就是说,ICMP报文是作为IP有效载荷承载的。
几种常用的ICMP报文类型:
文章中使用到的图片均来源于网络
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK