

腾讯优图&厦门大学提出无需训练的ViT结构搜索算法
source link: https://www.51cto.com/article/705395.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
近期,ViT 在计算机视觉领域展现了出强大的竞争力、在多个任务里取得了惊人的进展。随着许多人工设计的 ViT 结构(如Swin-Transformer、PVT、XCiT 等)的出现,面向 ViT 的结构搜索(TAS) 开始受到越来越多的关注。TAS 旨在以自动化的方式在 ViT 搜索空间(如MSA 的 head 数量、channel ratio 等)中找到更优的网络结构。基于 one-shot NAS 的方案(如AutoFormer、GLiT 等)已经取得了初步进展,但他们仍然需要很高的计算成本(如24 GPU days 以上)。主要原因有以下两点:
1.在空间的复杂度上,ViT 搜索空间(如,GLiT 空间的量级约 10^30)在数量上远远超过 CNN 搜索空间(如,DARTS 空间的量级约 10^18);
2.ViT 模型通常需要更多的训练周期(如300 epochs)才能知道其对应的效果。
在近期的一篇论文《Training-free Transformer Architecture Search》中,来自腾讯优图实验室、厦门大学、鹏城实验室等结构的研究者回顾近些年 NAS 领域的进展,并注意到:为了提高搜索效率,研究社区提出了若干零成本代理(zero-cost proxy)的评估指标(如GraSP、TE-score 和 NASWOT)。这些方法让我们能够在无需训练的条件下就能评估出不同 CNN 结构的排序关系,从而极大程度上节省计算成本。

- 论文地址:https://arxiv.org/pdf/2203.12217.pdf
- 项目地址:https://github.com/decemberzhou/TF_TAS
从技术上来说,一个典型的 CNN 模型主要由卷积模块组成,而一个 ViT 模型主要由多头注意力模块(MSA)和多层感知机模块(MLP)组成。这种网络结构上的差异会让现有的、在 CNN 搜索空间上验证有效的零成本代理无法保证其在 ViT 搜索空间上模型评估效果(见下图 1)。
因此,研究一种更适合 ViT 结构评估、有利于 TAS 训练效率的零成本代理指标是有必要且值得探索的。这一问题也将促使研究者进一步研究和更好地理解 ViT 结构,从而设计一种有效的、无需训练的 TAS 搜索算法。
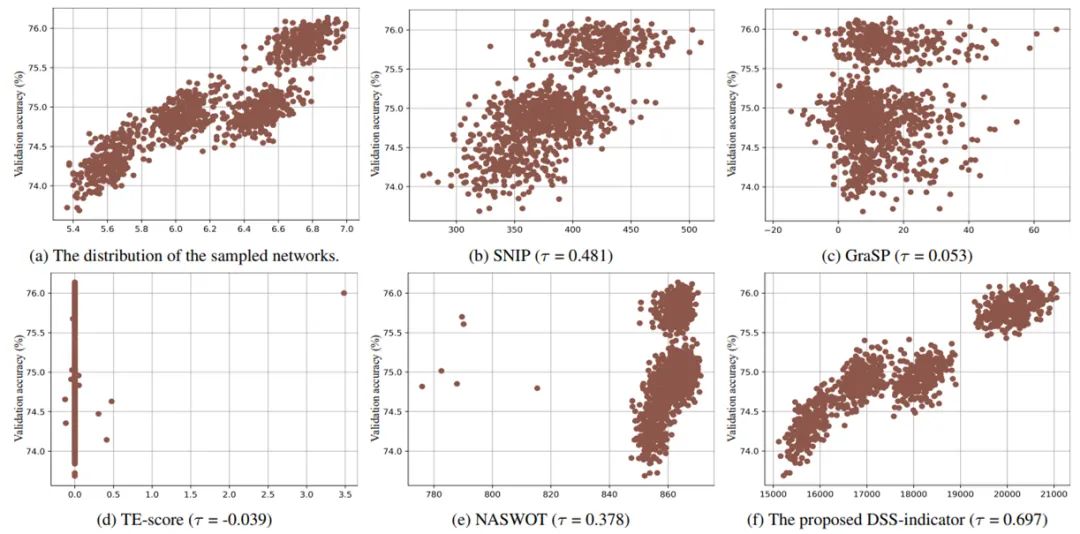
图 1. (a)研究者采样的 1000 个 ViT 模型的参数量和效果分布。(b-e)在 CNN 搜索空间效果好的 zero-cost proxy 方法并不适用于 ViT 搜索空间。(f)他们的 DSS-indicator 更适合用来评估不同的 ViT 模型。
为了达到这个目的,研究者对 MSA 和 MLP 模块进行了理论分析,希望找到某种可量化的属性来有效地评估 ViT 网络。
基于量化结果,他们观察到:在 ViT 中,MSA 和 MLP 确实具有各自不同的、适合用来揭示模型效果的性质。研究者有如下定义:衡量一个 MSA 的秩复杂程度,将其计作突触多样性(synaptic diversity);估计一个 MLP 内重要参数的数量,将其计作突触显著性(synaptic saliency)。当 MSA 拥有更高的突触多样性或者当 MLP 有更多的突触显著性时,其对应的 ViT 模型总是拥有更好的效果。
基于这个重要的结果,研究者设计了一个有效且高效的零代价代理评估指标 DSS-indicator(下图 2),并基于此设计了一个包含模块化策略的无训练 Transformer 结构搜索算法(Transformer Architecture Search,TF-TAS)。
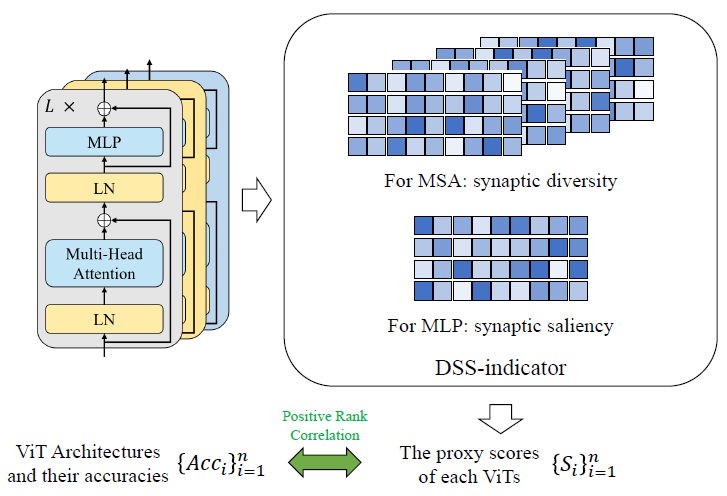
图 2. 方法的整体框架图。
具体来说,DSS-indicator 通过计算 MSA 的突触多样性和 MLP 的突触显著性来得到 ViT 结构的评价分数。这是学术界首次提出基于 MSA 的突触多样性和 MLP 的突触显著性来作为评价 ViT 结构的代理评估指标。而且需要注意的是,TF-TAS 与搜索空间设计和权值共享策略是正交的。因此,可以灵活地将 TF-TAS 与其他 ViT 搜索空间或 TAS 方法相结合,进一步提高搜索效率。
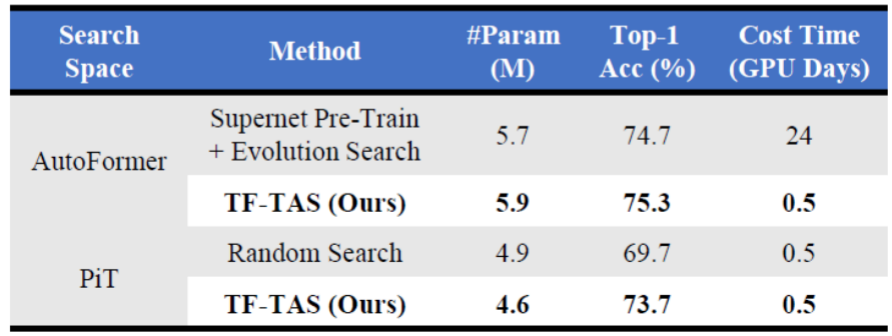
与人工设计的 ViT 和自动搜索的 ViT 相比,研究者设计的 TF-TAS 实现了具有竞争力的效果,将搜索过程从 24 GPU 天数缩短到不到 0.5 GPU 天数,大约快 48 倍。
MSA 的突触多样性
MSA 是 ViT 结构的一个基本组件,其多样性对 ViT 效果有重要意义。基于已有的工作可以知道:MSA 模块学到的特征表示存在秩崩溃(rank collapse)的现象。随着输入在网络中前向传播和深度的不断加深,ViT 中 MSA 的输出会逐渐收敛到秩为 1、并最终退化为一个秩为 1 的矩阵(每一行的值不变,即多样性出现稀疏的情况)。秩崩溃意味着 ViT 模型效果很差。因此,我们可以通过估计秩崩溃的程度来推测 ViT 模型的效果。
然而,在高维空间中估计秩崩溃需要大量计算量。实际上,已经被证明矩阵的秩包含特征中多样性信息的代表性线索。基于这些理解,MSA 模块中权重参数的秩可以作为评价 ViT 结构的指标。
对于 MSA 模块,直接对其权值矩阵的秩进行度量,存在计算量较大的问题。为了加速计算,研究者利用 MSA 权重矩阵的核范数近似其秩作为多样性指标。理论上,当权重矩阵的 Frobenius 范数(F 范数)满足一定条件时,权重矩阵的核范数可视为其秩的等价替换。具体来说,研究者将 MSA 模块的权值参数矩阵表示为
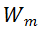
。m 表示 MSA 中第 m 个线性层。因此,
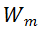
的 F 范数可以定义为:
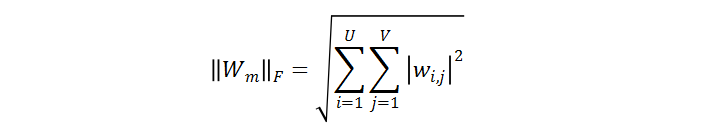
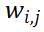
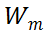
中第 i 行 j 列的元素,根据算术均值和几何均值的不等式,
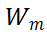
的上界为:
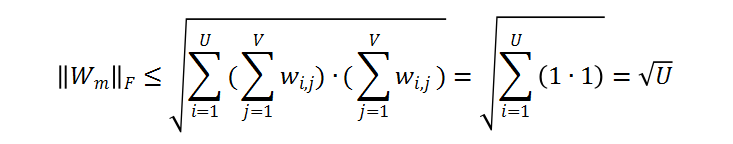
的上界即为
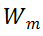
的最大线性独立的向量数,即矩阵的秩。随机给定
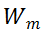
中的两个向量
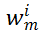
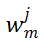
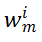
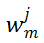
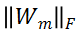
的值相应的会更大。这表明:
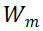
的 F 范数越大,
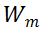
的秩越接近
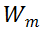
的多样性。当
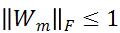
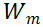
的核范数可以是
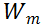
秩的近似。形式上,
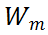
的核范数被定义为:
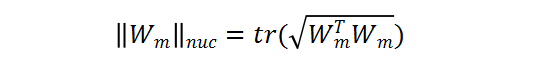
表示相应矩阵的迹,从而容易得到:
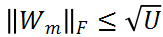
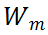
的秩可近似为
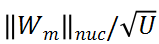
。理论上,
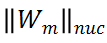
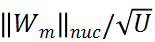
成正比,这也表明利用的核范数可以测度
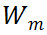
的多样性。为了更好地估计权重随机初始化的 ViT 网络中 MSA 模块的突触多样性,研究者在每个 MSA 模块的梯度矩阵
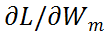
(L 为损失函数) 上进一步考虑上述步骤。
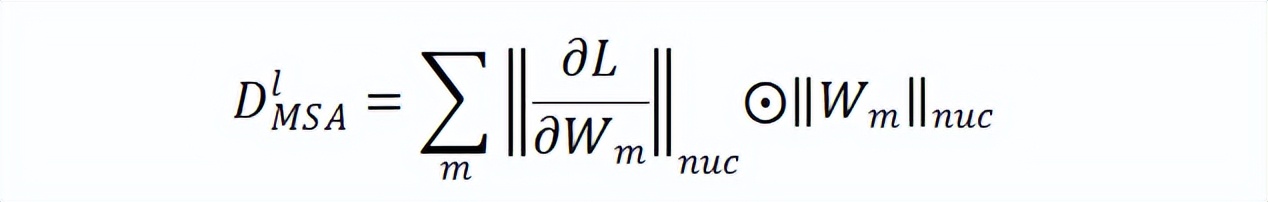
总的来说,研究者对第 l 个 MSA 模块中权重参数的突触多样性定义如下:
为了验证 MSA 的突触多样性与给定 ViT 架构的测试精度之间的正相关关系,研究者对从 AutoFormer 搜索空间中采样的 200 个 ViT 网络进行完整的训练,得到其对应的 MSA 模块的分类效果和突触多样性。它们之间的 Kentall’s τ 相关系数为 0.65,如下图 3a 所示。表明 MSA 的突触多样性与每个输入 ViT 架构的效果之间的正相关联系。
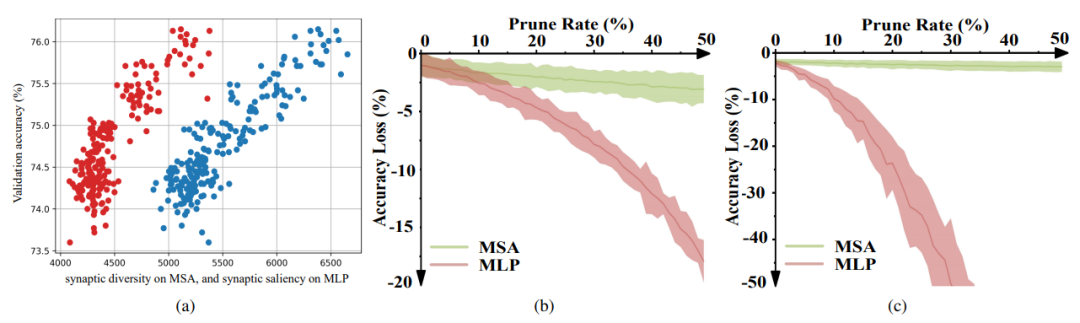
图 3. (a)MSA 的突触多样性(红)以及 MLP 的突触显著性(蓝)的评估效果;(b-c)MSA 和 MLP 具有不同的剪枝敏感性。
MLP 的突触显著性
模型剪枝对于 CNN 领域已经取得了很多进展,并开始在 Transformer 上得到应用。目前已经有几种有效的 CNN 剪枝方法被提出用来衡量早期训练阶段模型权重的重要性。主要有以下两派方法:
- 测量在初始化状态下衡量突触的显著性用于 CNN 模型的剪枝;
- 由于 Transformer 中不同模块在初始化阶段也有不同程度的冗余,因而可以通过对不同大小的 Transformer 进行剪枝。
与剪枝相似,TAS 主要搜索几个重要维度,包括注意力头数量、MSA 和 MLP 比值等。受这些剪枝方法的启发,研究者尝试使用突触显著性来评估不同的 ViT。然而, MSA 和 MLP 的结构差异较大,因此需要分析剪枝敏感性对度量 ViT 中不同模块的影响。
为了进一步分析 MSA 和 MLP 对剪枝的敏感性不同对评估 ViT 模型的影响,研究者通过剪枝敏感性实验给出了一些定量结果。如图 3b 所示,他们从 AutoFormer 搜索空间中随机抽样 5 个 ViT 架构,分析 MSA 和 MLP 对剪枝的敏感性。结果显示,MLP 对修剪比 MSA 更敏感。他们还对 PiT 搜索空间进行了分析,得到了类似的观察结果 (图 3c)。
此外,研究者采用 MSA 和 MLP 模块上的突触显著性作为代理,分别计算代理 ViT 基准上的 Kendall’s τ 相关性系数。最终结果表明在 MLP 上突触显著性的 Kendall’s τ 为 0.47,优于 MSA (0.24)、MLP 和 MSA (0.41)。
由于突触显著性通常以总和的形式计算,冗余的权重往往带来负面的累积效应。MSA 模块对剪枝不敏感,说明 MSA 的权值参数具有较高的冗余性。在剪枝领域中被证明冗余权参数的值要比非冗余权参数的值小得多。尽管这些冗余参数的值相对较小,但超过 50% 的冗余往往会产生较大的累积效应,尤其是在区分相似的 ViT 结构时。
对于累积效应,一般的零成本代理中不加区分地将 MSA 的冗余权重参数考虑在内来衡量显著性,导致相应的零成本代理中的累加形式存在 MSA 的累积效应。累积效应可能会使零成本代理给差的网络更高的排名。同时,权重冗余对 MLP 模块突触显著性的影响较小,因此可以作为评估 MLP 模块权重次数秩的复杂性的一个指标,从一个方面指示模型的优劣。
为了评估 ViT 中的 MLP,研究者基于突触显著性设计了评估的代理指标。在网络剪枝中,对模型权值的重要性进行了广泛的研究。由于神经网络主要由卷积层组成,有几种基于剪枝的零成本代理可以直接用于测量神经网络的突触显著性。另一方面,ViT 体系结构主要由 MLP 和 MSA 模块组成,它们具有不同的剪枝特性。通过对 MSA 和 MLP 模块的剪枝敏感性分析,他们验证了 MLP 模块对剪枝更加敏感。因此,突触显著性可以更好地反映 MLP 模块中权重重要性的差异。相比之下,MSA 模块对剪枝相对不敏感,其突触显著性往往受到冗余权重的影响。
基于 MLP 的修剪敏感性,研究者建议以模块化的方式测量突触显著性。具体来说,所提出的模块化策略测量了作为 ViT 结构的一个重要部分的 MLPs 的突触显著性。给定一个 ViT 架构,第 l 个 MLP 模块的显著性得分为:
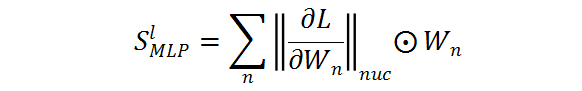
其中 n 为指定 ViT 网络中第 l 个 MLP 的线性层数,通常设为 2。图 3a 显示了一些定性结果,以验证
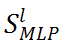
在评估 ViT 架构方面的有效性。
无需训练的 TAS
基于上述分析,研究者设计了一种基于模块化策略的无需训练的 TAS(TF-TAS),来提高搜索 TAS 的搜索效率。如下公式所示,DSS-indicator 同时考虑 MSA 的突触多样性和 MLP 的突触显著性来对模型进行评分:
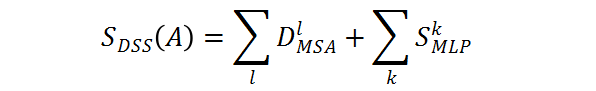
总的来说,DSS-indicator 从两个不同的维度评估每个 ViT 结构。TF-TAS 在输入模型经过一个前向传播和后向更新后计算
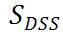
,作为相应的 ViT 模型的代理分数。研究者保持模型的输入数据的每个像素为 1,以消除输入数据对权重计算的影响。因此,
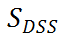
对随机种子具有不变性,与真实的图片输入数据无关。
1.Image-Net
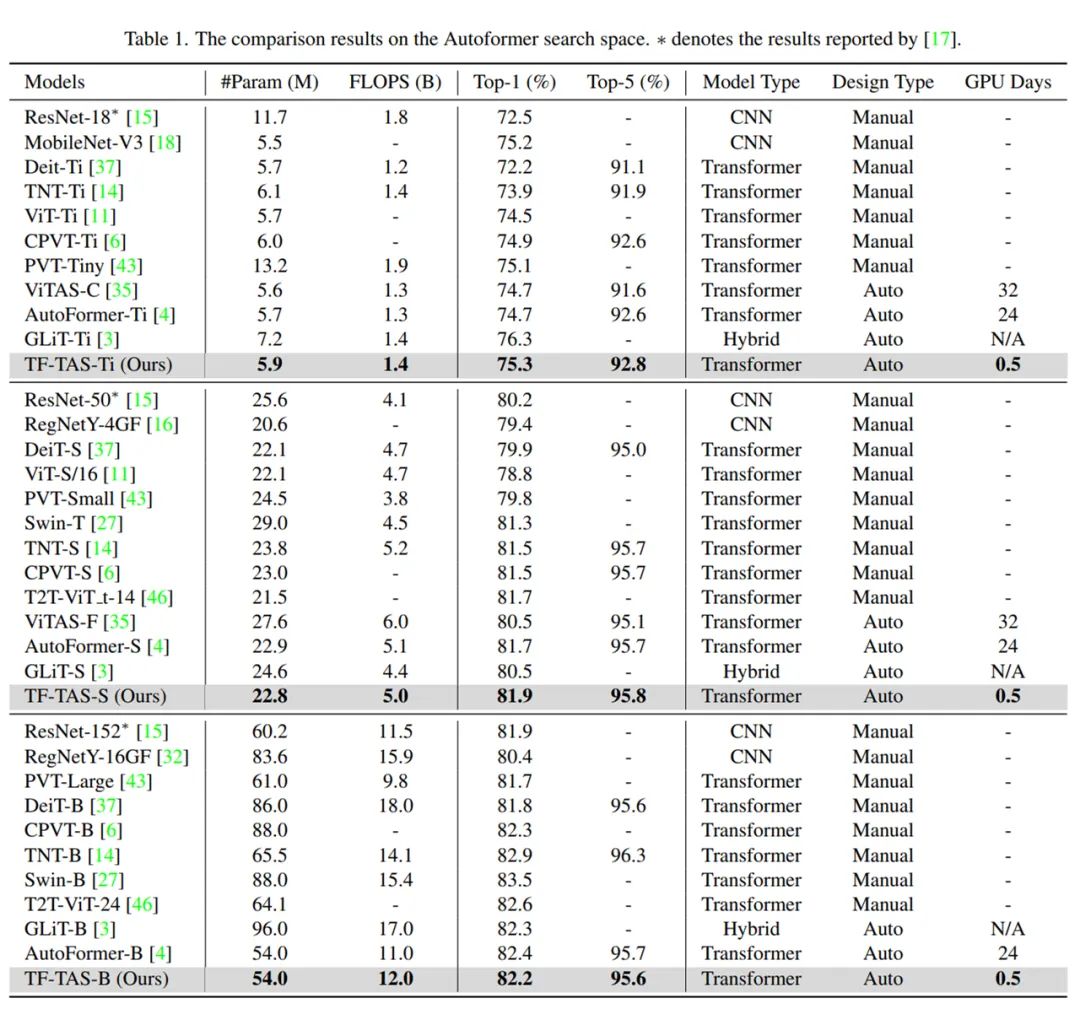
研究者首先在 ImageNet 数据集上进行搜索效果测试,结果如下所示。在三种参数量级上,研究者都能找到不亚于、甚至比基于 one-shot NAS 的 TAS 方法更好的模型结果。而且所需要的耗时(0.5 GPU days)要远小于现有 TAS 方法所需的计算成本(24 GPU days 以上)。
2. 迁移实验
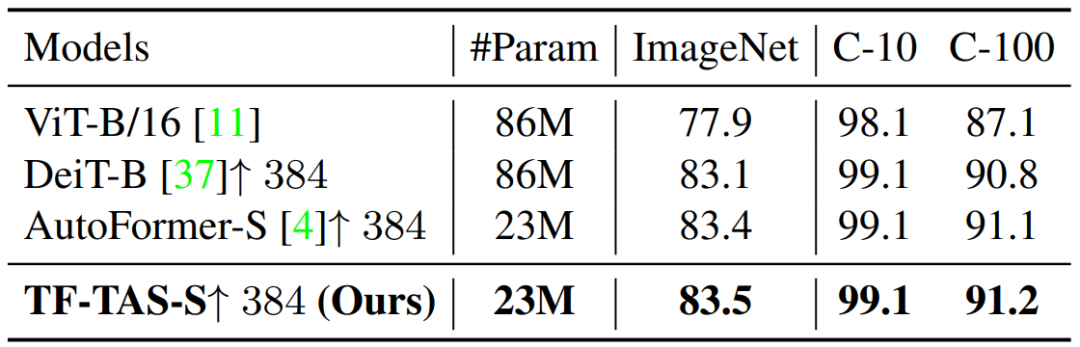
为了进一步验证搜索得到的模型的效果,研究者在 CIFAR-10、CIFAR-100 数据集上验证其迁移性。按照 AutoFormer 论文的设定,他们将模型在 384 x 384 大小的图像上进行 fintune,效果如下所示。基于 DSS-indicator 找到的模型与基于 one-shot NAS 找到的模型在迁移性上不相上下。
3. 在其他 ViT 搜索空间的搜索效果
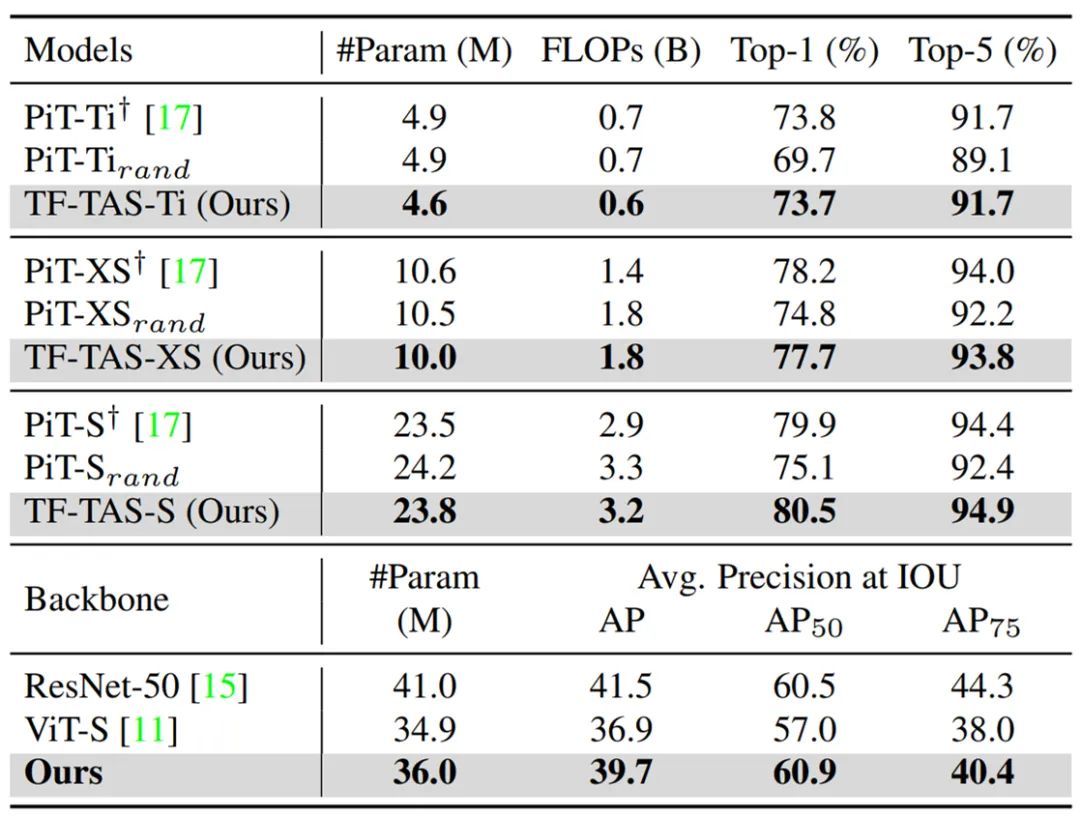
此外,研究者也在 PiT 搜索空间上进行了搜索测试,并按照论文的设定,在 COCO 数据集上测试了搜索到的模型结果对应的检测效果。结果如下表所示:他们搜索找到的 PiT 模型 TF-TAS-Ti、TF-TAS-XS 和 TF-TAS-S 和基于手工设计的 PiT 的效果不相上下,而且远好于随机搜索的模型结果。并且在检测效果上,研究者的方法也有一定的优势。这些结果验证了该方法的有效性和普适性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK