

大数据的智能处理和数据可视化实践
source link: https://dbaplus.cn/news-73-4253-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
大数据的智能处理和数据可视化实践
本文根据吴仕橹老师在〖2021 Gdevops全球敏捷运维峰会-广州站〗现场演讲内容整理而成。

(点击文末“阅读原文”可获取完整PPT)
讲师介绍
吴仕橹,汇丰科技 数据分析经理。曾任职于Accenture负责对M&G的大型系统集成系统的研发和交付,主要采用Spring Integration并对其进行封装同时采用SOAP架构,近几年来,任职于HSBC Technology投资银行部,致力于大型前台系统的开发和运维,从2019年开始专注于大数据方面包括数据安全、数据处理、数据可视化等自研平台的研发以及团队的DevOps转型。
分享概要
一、业务洞察和分析
二、数据和分析执行
三、数据安全与管理
四、数据交换
五、Rapid-V
大家常经常把数据比喻成石油。但是石油真正有价值的,是通过一些相应的技术提炼后得到的产品,比如煤油、汽油、机油以及一些通过进一步催化、裂化等技术得到的像凡士林之类产品。
因此,在看大数据时,我会把石油处理的整个工业化思路套入其中,再展开去看。一方面,大数据需要有一个技术平台的支撑;另一方面,它需要有各种各样的数据。技术平台支撑数据的处理,数据通过平台去实现业务价值。也就是工艺创造可重复利用的数据资产,然后在这些数据资产的基础上进一步带来更多更长远的业务价值。
一、业务洞察和分析

这个图就是我看大数据的第三个维度:数据的流水线,也就是我们常说的data pipeline。图中的s1s2s3相当于我们的石油开采厂,负责开采数据,然后通过运输管,把采集到的数据输送到相应的目标点进行储存。在我们的场景中,这个目标点就是数据湖。
数据存储起来之后,需要有相应的工艺对它进行加工。我们的数据工厂相当于石油的炼制工厂,它会通过蒸馏、催化裂化的技术对数据进行相应的处理,产出可重复利用的数据资产。这时候的数据资产可以怎么用呢?我们可以将它应用在很多维度。比如直接使用,因为这个阶段这些数据资产就好比石油炼制出来的煤油、汽油、机油等可以直接用在燃油机上,我们可以用这些数据资产来做报表或表格的直接呈现。
往更深的数据处理维度,也就是数据的insight。一个特别的例子就是数据科学,科学家可以在这个维度入场,在这些已经清理过并且处理得很漂亮的数据上建立机器学习的模型,从中带出更多的business insight。在这里我们会有一个疑问:这时候这些insight可以用来做什么呢?答案是帮公司省钱,或者带来新的业务价值。
我们回过头来讲一讲大数据平台的搭建。大数据平台中的部件很多,包括数据的采集平台或工具等。数据采集这部分我最不喜欢,因为我觉得它比较单一,简单粗暴地讲就是把数据进行copy 和paste。但是如果想把它做好,这也可以是个技术活。设想一下,每天上千个系统的数据会通过离线和实时的方式注入数据湖中,所以它涉及到的数据量和工作流的调度,对它并发性的要求会特别高,所以喜欢做高并发的系统的小朋友们可以在这方面进行研究。
数据注入后,接着是数据的清洗、智能治理、数管理、安全性、可视化等,每一个都是可以展开讲的大话题,我今天只是拿其中的一两个来讲一讲。
二、数据和分析执行
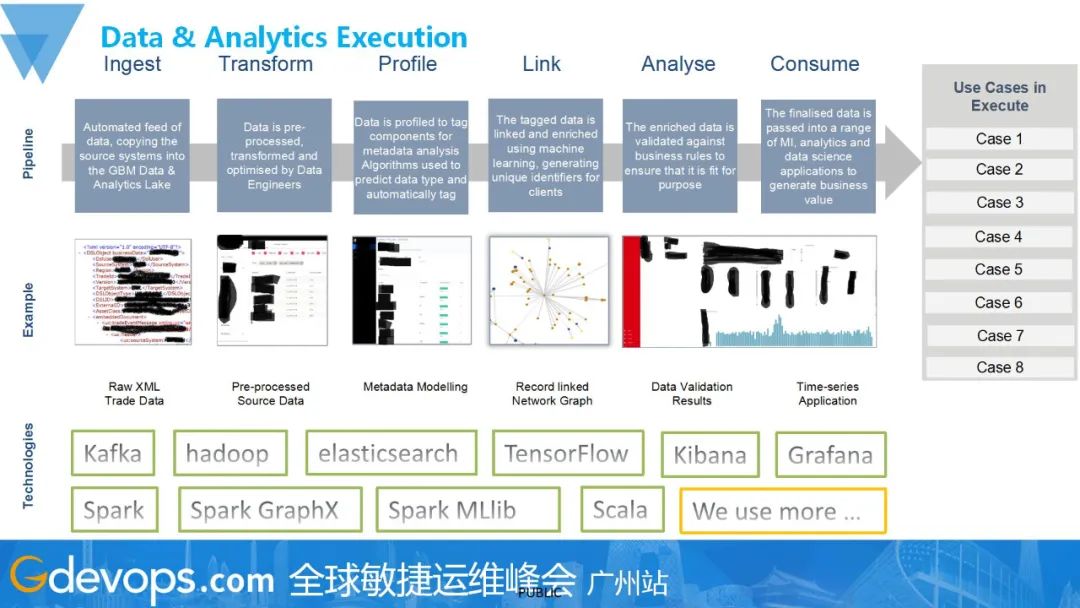
图中展示的是我们的一个data pipeline,以用户案例作为视觉切入点。在这上面,我们有数据注入、数据清洗、数据连接、数据科学家进行数据分析、将最终的insight发给用户去consume。在这里我想着重讲一下关于link的这部分。在我们的部门里,我们用到了一个技术叫做Entity Resolution,主题思想可以参考:https://www.datacommunitydc.org/blog/2013/08/entity-resolution-for-big-data。
它的理念简单来说就是:通过智能的方式实现数据连接和去重。为什么我们需要这样的技术?大多时候,我们处理的数据是没有一个唯一的ID用来连接和串起所有的数据的。Entity Resolution就是这样的一个算法,在我们没有唯一ID的情况下,把所有数据组织成一个网。比如作为一个互联网用户,我有在携程、支付宝、微信或者是其他的一些平台的数据,但这些系统很可能并不互通,我无法通过一个唯一的ID把它们连接起来。所以,Entity Resolution的作用就是:将不同系统的数据连接起来,同时给这些连接起来的数据产生一个唯一的ID。
这部分听起来有点像:对一个数据库里的表进行挑选后再 distinct一下,将数据进行合并,同时去掉重复数据。理论上的确是这样,但事实上,在做大数据的时候,比如我们公司会去外部买很多数据回来,像过年的企查查或者一些国外的关于企业的数据等。这些外部的数据再加上自己公司内部的数百个系统的数据,将会达到一个相当可观的量级,这时候我们想把这些数据进行合并就会十分困难。特别是在银行业,许多核心系统一般都有二三十岁。那些系统不像如今我们互联网的系统一样设计得非常完善,所以,当我们需要把这些系统的数据合并起来时,也没办法像关系型数据库那样,以一种链接的方式来实现。
举个例子,比如说我们对应的是一个企业级的客户,在这里我们假设它的名字是阿里巴巴集团。当然这里的阿里巴巴集团并不是指市场上的某一家大厂,我们只是做个假设。阿里巴巴它是一个集团公司,它旗下可能有几百上千个子公司,像菜鸟可能就是其他其中的一家子公司。我们整个的Entity Resolution中解决的点就是:把这些数据源里面和阿里巴巴集团相关的Entity,包括它的子公司和子公司的子公司等全部link起来,然后,我只需要找到其中一个,比如菜鸟,我就可以接着追溯到相应的父公司,它的父公司的父公司,还有它自己的子公司或者亲友公司等,这是它解决的一方面。
另一方面我们叫做 Connected Party,Connected Party就是把公司跟公司、公司跟个人等之间的关系给link起来,比如某人是某公司的总监,或者某公司在某月份付给了另外一个公司一定数额的钱等。举个例子,我跟X老师都受雇于H公司,同时,X老师是A公司的总监,我是B公司的总监,X老师的A公司给C公司转了1百万美金。

接下来讲一下Entity Resolution最后的一个功能点,以阿里巴巴为例,它也许是我们公司的客户,也许不是。如果它是我们的客户,那我们可以在我们所有内部和外部的系统中,把它所有的信息都链接起来,比如它有什么样的account、买了什么样的产品、做了什么样的交易、财务情况怎样等等,所有这些信息都可以把它们呈现、链接起来。

把数据做这样的处理,它背后的潜在价值是什么?我想以客户尽职调查做为例子。传统上来讲,对公业务的尽职调查的时长比较长,同时也需要对很多文件进行审查。在数据化之后,潜在的可能就是,能够把客户尽职调查变成秒调。
举个例子,比如说现在阿里妈妈还不是我们的客户,但有一天它突然来找我们的一个客户经理,说想跟我们银行做生意。这个时候,如果我们已经全部都数字化了,所有的信息都可以link起来,我拿阿里妈妈这个名字,通过我刚刚丢出来的这一整个模型,就可以查出它的信用评级、它在企查查的评分、有什么样的风险、是不是跟阿里巴巴有父子关系等。这样一来,操作人员就可以快速地判断这个客户从而帮它开户,客户也就不用再花一两个月的时间来等待尽职调查的结果。
通过这数据化驱动的方式,把尽调的时间缩短到最少。更进一步挖掘这数据,也许我们可以再邀请数据科学家创造出一个模型,通过模型将这些数据进行进一步提炼,给出参考评分?
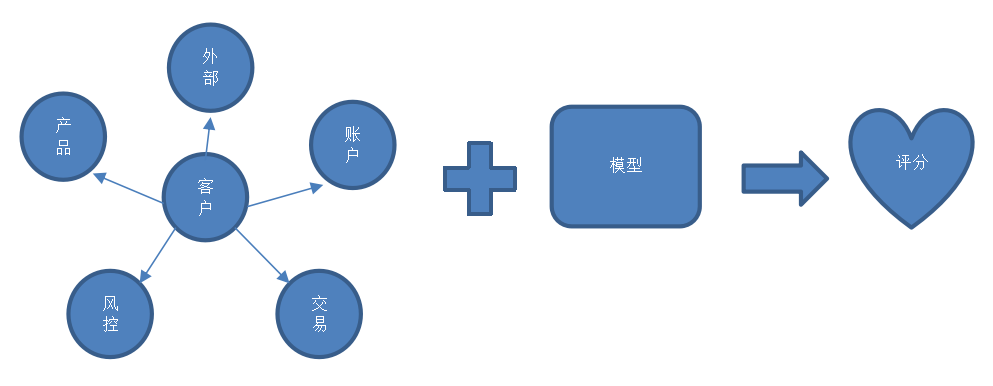
Entity Resolution里面会用到哪些技术呢?业界会推荐一些像k mean之类的model去做 linkage。我们用了Apache的Spark Graph X来进行图计算,图计算简单地来说就是:点跟点之间通过边的关系连接起来。在这个例子里,数据源就是相应的点,而边指的是数据之间的关系,我们通过这些关系实现数据的连接。
三、数据安全与管理
接下来是大家可能比较感兴趣的,关于数据安全方面和数据管理方面的内容,这两个其实也都是很大的话题。这里的数据安全主要以我们自己 build的一个叫Data Guardian的产品为例,它主要用来把控谁可以看和用到什么样的数据。举个例子,比如我现在是广州天河某支行的客户经理,手上有10位客户在由我做客户关系管理,按照整个的设计,我只能看到与这10位客户相关的一些信息,而关于收支方面的数据我不可以看到。那么我在进入系统时,我们的Data Guardian就会通过整个的数据的所有元素,从源头收集它的元数据,并对相应的特点做标签。
四、数据交换
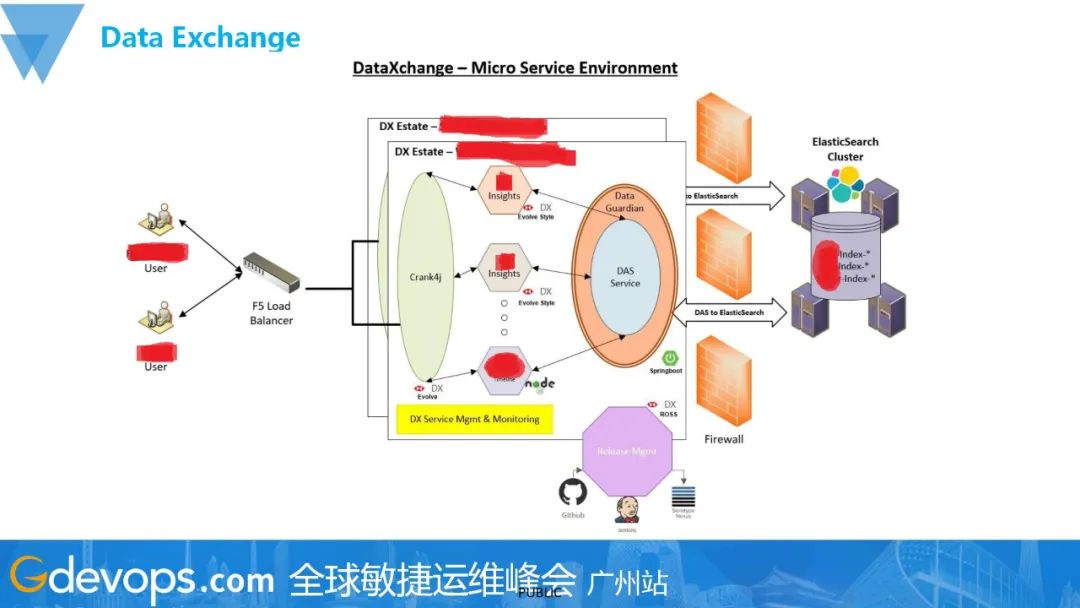
Data Exchange是一个基于微服务架构的平台,主要是一个Data Consumption层。在传统行业中,特别是在银行业,数据会由处于内部更深层的防火墙围着。数据的安全得到了保护,但这一做法也导致了对数据读取和运用的极大阻碍。一方面,从流程上需要层层安全性的审批;另一方面,技术上的实现除了不断地朝防火墙开端口,没有其它更好的做法。所以,Data Exchange应运而生。
在面向用户层,我们运用F5作为负载均衡。当用户有访问时,它会通过网络层面的负载均衡,把它路由到不同的服务中去。同时后端的服务会去访问我们的数据存储层,这里存储的就是最终被处理提炼过的数据。所以,在Data Exchange里可以发布各种各样的API以及sftp等服务,让用户或者系统consume我们的数据。
五、数据可视化
业界有很多商业或开源的数据可视化方案,比如Apache的superset,用户可以在上面配置相应的数据源,然后通过写类sql的语言来实现可视化数据;商业方面有像 Looker或 Power BI类型的产品,可以实现数据的可视化,但商业的一般很贵。后来,经过我们的思考和调研,对一些中小型的用户案例以及我们的日常需求进行分析,得出我们需要一个实用的可视化工具的结论。因此,我们开发了Rapid V,通过拉拽不同的数据源,快速配置实现相应的、各种类型的可视化图案。
这是我们当时的想法,你可以看到,它主要有4个不同的部件。一个专门用于配置不同的数据源,你可以把API、csv或者推送的文件作为数据源上传上去,也可以配一个Oracle或者 PostgreSQL,Elasticsearch。通过上面的一些部件,对相应的数据源进行拉取,这就相当于把它们给链接起来,然后我就可以在旁边做配置。像这一个图,我想通过 sum或者count等方式去做聚合。当我们将自己的可视化版面设置调配好后,就可以选择对它进行保存和发布。
Rapid V的另外一个比较重要的功能是modelling,我们能够通过它把不同的数据源以配置的方式将数据进行合并。这背后主要是用了Trino来做了一个虚拟化的层次,借助它我可以通过标准化的sql,让它把不同数据源里面的数据进行合并,从而组装成一个新的数据源。
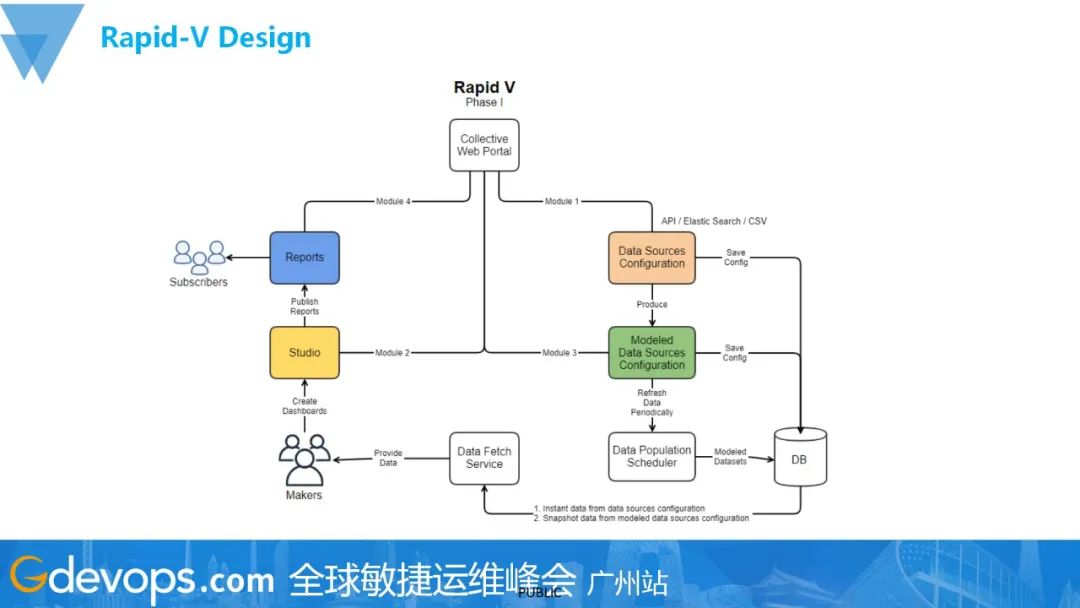
Rapid V最后一部分的功能是报表的统一管理。当用户配置好自己的报表,并将要进行发布时,用户可以选择自己的可见度,也可以把它分享给授权的人看到。
这是我们的一个例子,当时我们在驱动相应的招聘男女比例,希望通过招到更多女生从而达到更好的男女平衡。而通过这个报告,它可以带来许多insight,像收到的CV里面性别的分布是什么样的?最终通过面试比例的男女比例等。这是我们当时用来驱动整个部门在做招聘时的想法。
Q:汇丰内部有几百个系统,有一些因为年代的不同,它们的底层系统甚至数据库或数据的格式可能都不一样。汇丰如何处理这些不同数据格式之间的收集和有效数据的验证?
A1:我们其实有自己研发了一个专门用来数据采集的系统,用它来做各种不同数据源的数据采集,包括离线的和实时的。比如数据源是Oracle、PG、DB、MySQL、SQL Server、Solace、 Kafaka、普通文件、云存储等等。在我们的设计里,我们用Hdfs来做数据着陆的系统,以统一的Parquet的格式存放文件,同时会把数据加载到Hive以便于对原始数据的分析和处理。每一次数据采集后,都会经过两步数据的验证,第一步是数据的checksum,第二步是采集到的数据跟原系统数据的reconciliation,确保数据没有丢失。
Q2::银行中有很多不同的业务部门,其中有不同的业务数据,但同时它也有可能有自己的数据平台。我想请问,怎么才能有动力让它把业务数据放到你们的平台里面?
A2:举个例子,我们有 Market部门, Market部门中有product、trade,但client数据是在 banking这条线里。如果banking自己去做,它既没有Market那边的product相关数据,也没有Market那边的trade的数据。再者,风控部门拥有的是交易风险、市场风险等数据,财务部分拥有财务相关数据,各自的数据互为联系,没有了彼此,就做不到以客户为中心的360度数据。所以这就是大家的动力所在,如果我把这些所有的数据都拿进来了,我就可以做到客户的360度。
Q3:一个公司中,不同部门之间的数据往往相互独立,当我们要对这些数据进行跨部门的修改调用时,可能会涉及到一个复杂而漫长的审批流程。我们怎么才能把这个流程简化,缩短审批时间?
A3:我相信贵公司应该有一个类似 CDO的部门存在,就是Chief Data Office。在这个部门里面,比如说我们公司就有CDO这样的一个部门,Data Management就是其中的一个职能和分支,他们也会负责专门去解决像把数据上传到云端、数据跨国家分享这样的一些问题。所以问题中说到的部门与部门之间的数据跨越,这部分痛点倒不是很大。更大的痛点在于:怎么去实现数据的跨国分享?或是如何将数据上传到云端?因为这涉及到数据的外包问题,我们的这个部门就是负责跟监管打交道,同时确保我们不那么敏感的数据可以上云。
↓点这里可下载本文PPT,提取码:i9qs
阅读原文
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK