

元数据管理拉垮得一批,还谈啥数据治理???
source link: https://dbaplus.cn/news-73-4202-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
元数据管理拉垮得一批,还谈啥数据治理???
导读:本文的主题为小米数据管理与应用实践,主要介绍小米在数据管理建设方面的理解和探索。数据管理的核心重点在于元数据平台的建设,用以支撑数据管理的上层应用,包括数据地图、数据规范治理、数据成本治理及数据质量建设,以及未来的规划。将围绕以下三个方向展开:① 元数据平台的建设;② 元数据应用;③ 未来规划。

图1 元数据平台包含的内容
一、元数据平台的建设
小米元数据平台的建设内容,主要包括数据管理架构的现状、以及架构的演化过程。在建设元数据技术平台的过程中,针对以下三个方面进行了改进,也是平台进化的三个关键点:
-
实现全域元数据
-
实现实时血缘
-
实现精准计量
元数据是用来描述数据的数据。请参见图2 。从抽象来看,包括分为实体、实体的属性以及实体与实体之间的关系三个方面来进行分类。实体主要指表元数据和作业元数据,来自于工程师在ETL的实际工作中所涉及到的系统。如:Hive、Doris、Kudu、MQ、ES、Iceberg,即传统的数仓及上下游。
比如:实体包含了技术元数据和生产元数据。其中技术元数据用于支撑数据资产管理的资产地图;生产元数据,主要是作业的一些调度信息和运行信息,用于支撑数据资产管理的数据质量和成本治理的服务。
实体的属性,包含业务元数据和衍生元数据。
业务元数据包括数仓分层、数据分类、指标关联、应用信息、隐私分级等内容。内容来源于建模规范、业务、指标系统、BI看板、数据报表,以及来自于业务的隐私分级定义等。业务元数据用于支撑资产管理的资产价值、安全治理以及规范治理。
衍生元数据包含元数据的存储计量和访问计量。存储计量是服务于存储层面的成本治理;访问计量用于描述数据的使用情况,从技术角度去衡量资产的价值。衍生元数据来源于ETL工作中涉及的HDFS-Image、Doris、Kudu、MQ、ES以及HDFS-Log、SQL-Log。
描述实体的关系,包括血缘元数据,用于描述元数据之间的关联关系,用于支撑数据资产管理中的影响分析和资产地图服务。

图 2 元数据分类
2、元数据平台技术架构小米元数据平台的技术架构如图3所示,整体架构与Apache的Atlas非常相似。
整体上可以划分为三层。最上层是数据采集的源头,以及最终数据支撑的应用,包括Metadata Source、Lineage Source、Log Source和应用Application。中间层是集成层,集成层是由Metacat、MQ以及API层组成。最底层是核心的存储层。
最上层的Metadata Source用于对表元数据采集。最早只限于Hive表,后来实现了全域元数据的采集。主要包括ETL整个生产链路及上下游的全链路。比如:元数据采自于业务的Mysql数据库。其中消息队列采用了小米自研的Talos,简单说实现了数据集成与分发的总线。而下游元数据的采集由Hive、Doris、ES、Kudu等实现。

图 3 元数据平台技术架构
Lineage Source实现血缘信息采集。血缘元数据是来自于从各个计算引擎。通常血缘元数据是通过SQL的查询入口或者调度入口去采集。由于小米的业务特别多,且部门各自独立,因此入口也特别多,很难通过常规的入口采集的方式提升数据采集覆盖率。考虑到各部门的计算引擎都是在部门的计算平台进行维护,从而可以在引擎侧打点,实现血缘元数据的采集。同时结合SQL入口对SQL的审计日志做补充,两者的数据进行合并,得到较为满意的血缘元数据采集及采集覆盖率。
Lineage Source中的DataHub是小米内部的数据集成平台,包括离线整理集成和实时集成。DataHub集成平台也有上下游的血缘关系,也进行血缘元数据的采集。
日志层面调度日志、计量日志以及运行日志。这些日志跟质量建设和访问相关。Application应用,包含数据平台的上层应用、数据地图、成本治理、规范治理等内容。
在中间层的Metacat,是在采集诸多原图的元数据时,提供一个统一元数据的视角。所以通过基于Metacat进行二次定制开发,实现内部的各个系统的适配。元数据的采集统一通过Metacat实现,包括T+1和增量变更,都要通过Metacat来实现。因此,Metacat与Messaging连接起来,Metacat把每天增量变更送到Messaging。之后包含血缘信息的日志通过Messaging送到数据总线,使下游层面可以使用这些数据,通过API为上层应用提供数据服务和支撑。
最底层的存储部分,基本信息都存储在Mysql中;T+1的快照存储在Hive中;血缘图关系存储在JanusGraph。元数据的检索,包括权限的检索过滤、审计检索等都放在ElasticSearch。
3、全域元数据元数据平台进化过程中,关键的演化点之一是全域元数据。之前提到元数据都是基于Hive进行管理,显然只能看到Hive层的数据,无法知道产生的Hive表,到下游后最终有没有被使用。举例来说,有一堆数据给上层应用,用于看板或者指标,产生了一张Doris表;但对应的看板可能并没有人看,所以可以通过倒推,把链路中的这一条链路进行优化或者治理。而实现这样的场景,就需要打通全链路,包括看板信息,搜索等,都需要全域元数据进行支撑。此时就需要进行域拓展。以Hive为中心去看上下游,包括上游的业务数据库、Messaging,下游的Doris、Kudu、ES,包括内部重构传统Hive 数仓的Iceberg,都要采集元数据。在实现全域的过程中,同时打开统一元数据的Hive Metastore,实现统一的表数据视角和管理。请参见图4。
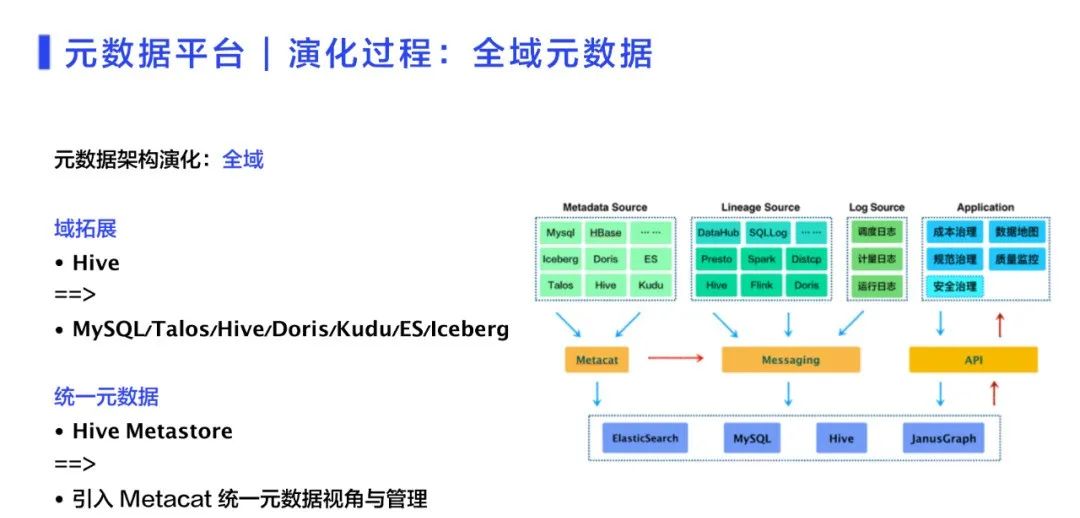
图 4 实现全域元数据
4、实时血缘关键的演化点之二是实时血缘。如前所述,小米入口非常多,血缘关系采集很难实现面面俱到。最早采用解析HDFS日志的办法,存在血缘很难正确解析的问题。例如:读一个表,可能会有很多open操作,这些Open操作很难对应表和表之间的关系,就会带来血缘关系不准的问题。早期的解决方案是找出所有的读和写操作后,做一个笛卡尔乘积,但这样就会产生大量不存在的血缘。
以上这些痛点严重影响了上层的数据治理,影响了解决问题的溯源过程。此外解析日志,由于只能T+1,认知量也比较大;而如果出现一个流式数据,就根本无法解析。这些都与通过SQL解析、能确定血缘的情况完全不同。
所以在进化版的新版方案中,考虑到 了入口问题和引擎接入的改造成本问题。方案最终采用实时引擎MQ埋点的方案。同时各个引擎本身要去执行这个SQL,比如Hive、Flink、Spark等,包括Presto、Distcp。因为需要执行这种操作,本身就需要去解析执行计划。而Spark、Flink也都支持对这些操作。通过对血缘关系的解析进行了内部改造(请参见图5),整体运行流畅。同时结合SQL Proxy Log去做血缘关系整合,从而实现血缘关系的精准解析。
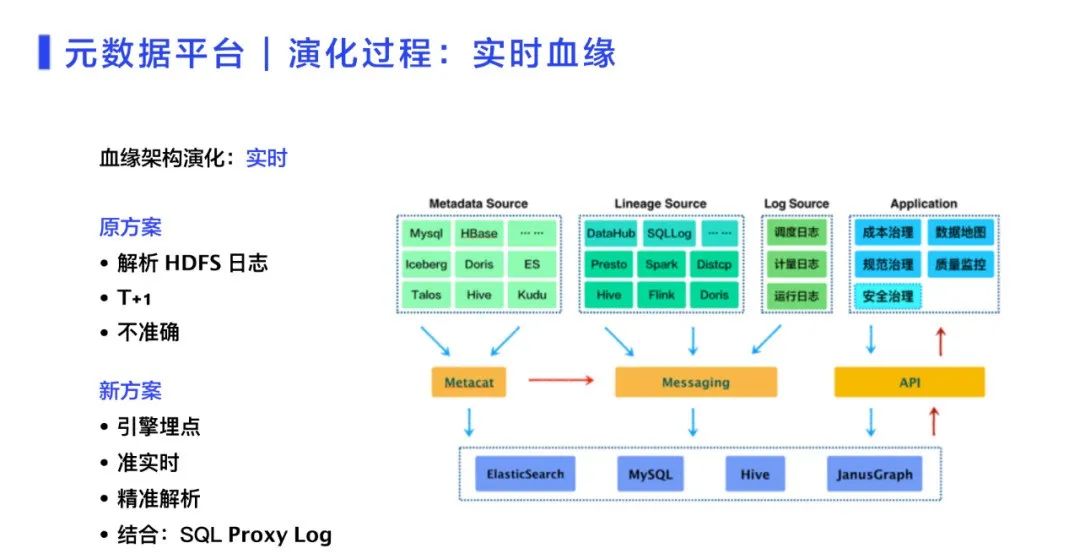
图 5 元数据实时血缘
5、精准计量关键的演化点之三是精准计量。精准计量目前还不能做到完全精准的计量,但是解决了计量的零和一的问题。在最早的入口问题中,计量不准就无法对数据的冷热程度进行判断。比如用户操作Hive表,会有各种各样的形式,通过各种各样的SQL。
尤其研发的种查询需求就很难应对。比如:Spark SQL分为常驻服务和非常驻服务,都是为了解决Spark SQL作业执行的启动问题。非常驻服务与Hive SQL一样,每次都要有一个启动过程。常驻服务则可以及时响应SQL需求,直接执行,减少了几分钟的启动过程,其查询过程能够快速响应。还有Flink SQL、Beeline、Flink Jar和Spark Jar,包括Distcp想去覆盖这些入口的计量,访问情况的确定也是解析HDFS日志。通过这些日志解析血缘存在的问题,就是在Hive Jar的层面,无法确定上层谁提交的访问。
计量部分现阶段解决了零和一的问题。简单的说当数据被访问后,能基本保证打上数据访问的标记。同时,通过与HDFS日志提供的足够信息、进行精准的统计和整理,并结合顶层的SQL审计进行修正后,可以得到具体被访问次数的精准计量。请参见图6。
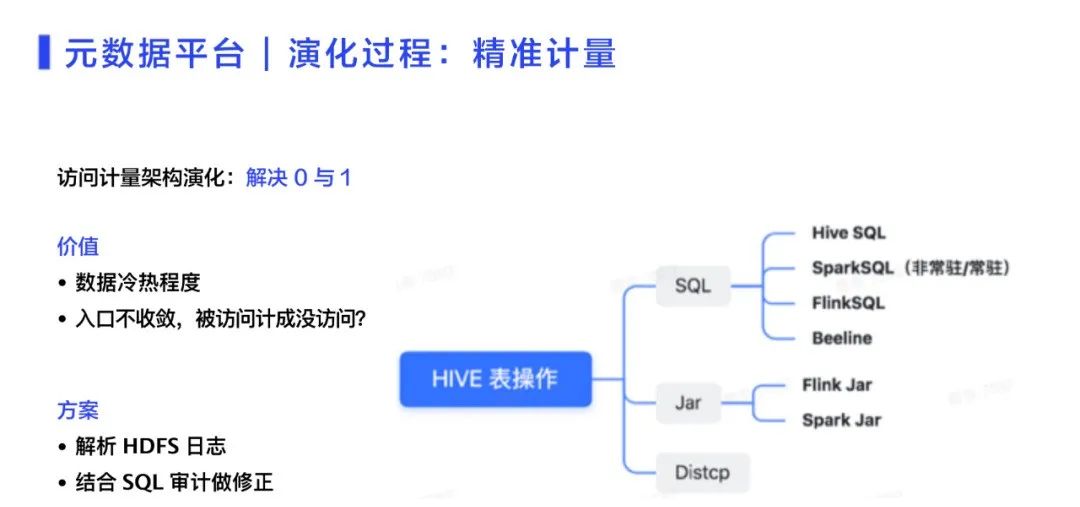
图 6 元数据精准计量
下面在元数据平台建设的基础上,讲述小米元数据应用在以下四个方面的进展:
-
数据规范治理
-
数据成本治理
-
数据质量建设
二、数据地图
数据地图是元数据应用的典型应用,包含两个方面的内容:数据地图中数据的搜索和血缘关系。
1、数据地图-搜索数据地图在业界已经是比较成熟的服务,小米的数据地图建设目前处在追赶阶段。数据地图需要支持元数据的搜索与发现,具体包括以下三个方面的内容:
-
支持表、字段、描述信息、数仓分层、数据分类、标签、部门等信息搜索,即实现可对实体属性再加关系的数据进行的全域搜索;
-
除了Hive 表,完善全域元数据概念中的其它引擎,如:Talos、Doris、Kudu、Iceberg、ES、MySQL等数据引擎;
-
实现支持对指标、维度、看板等信息的搜索。
例如:一个新零售的搜索,如图7的左侧所示。根据用户的收藏数据域分类打了标签。将大权重记录放在上面,搜索的结果更多的作为展示产品的形式。
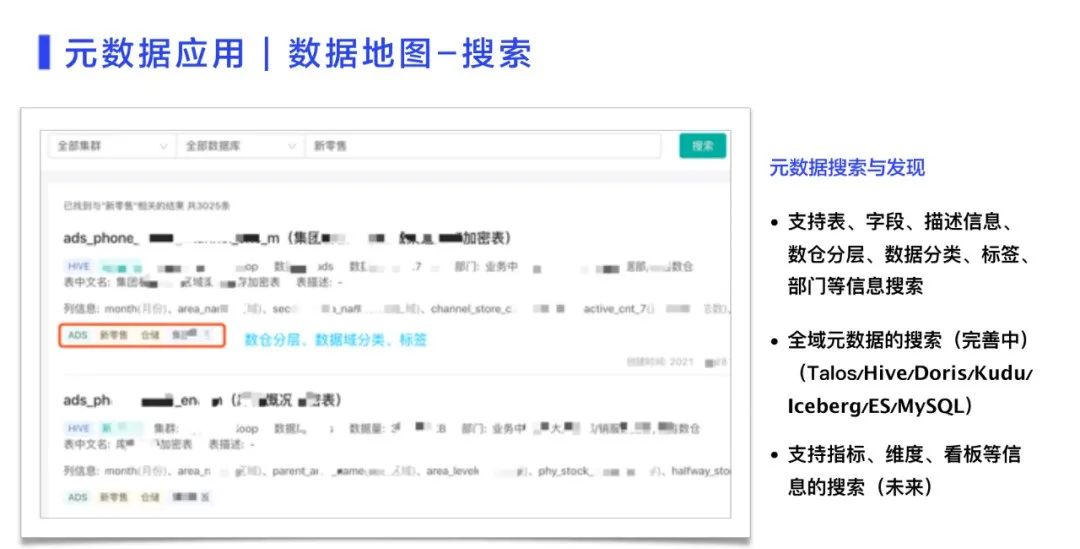
图 7 数据地图-搜索结果
2、数据地图-血缘通过数据地图,可以更清晰展现数据之间的血缘关系。通过技术架构改造,实现了全链路的数据血缘,使不同系统的链路关系都能展示(如图8),包括 MySQL/MQ/Hive/Iceberg/Doris 等。这样用户就能很方便的从数据最早的源头,一直追溯到最上层的应用。大大方便了对问题的追溯,也更方便的实现对整体数据价值的评估。
数据地图的后续建设会增加对血缘的搜索和变更通知。
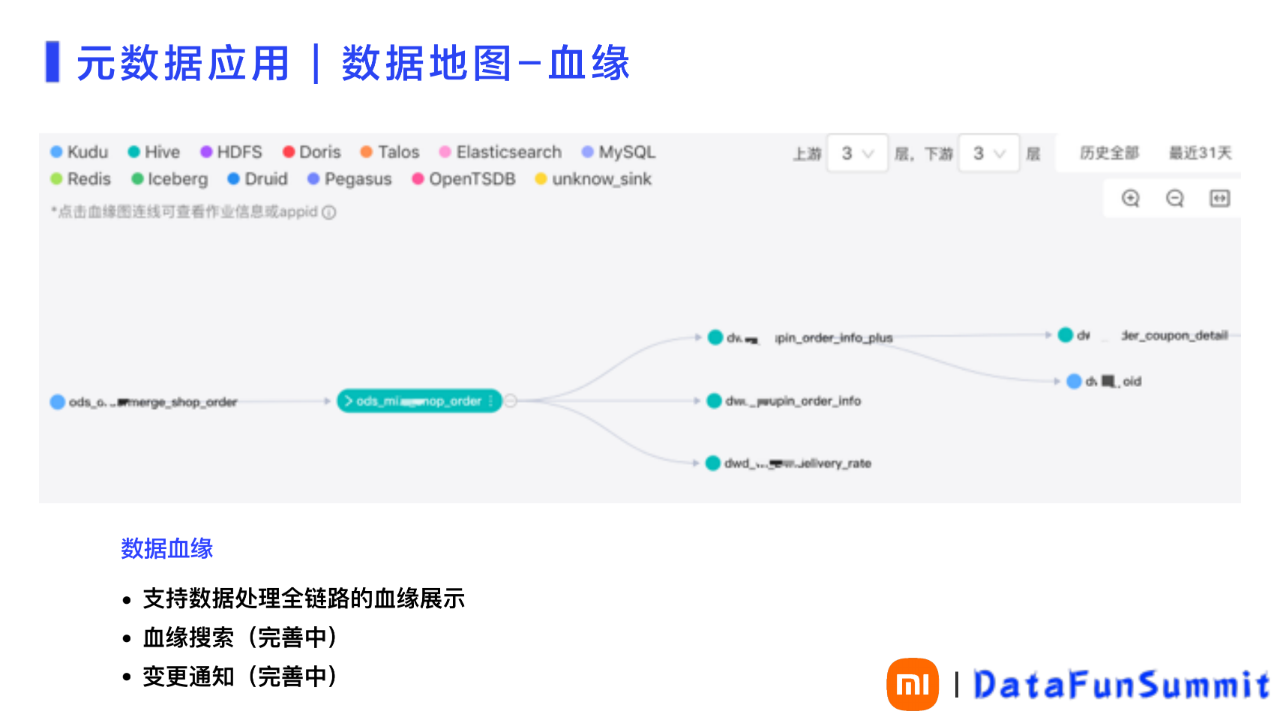
图 8 数据地图-血缘关系
三、数据规范治理
元数据应用中的重点应用是数据规范治理,对元数据的生态健康起到至关重要的作用。数据规范治理分为两个度量维度:
-
建模规范度;
-
建模完善度。
数据规范治理通过以上两个维度作为指标,量化数据健康完善的程度。

图 9 元数据应用-数据规范治理
1、建模规范度建模规范度又分为以下三个方面:
-
命名,是指表的命名是否符合收藏的规范;
-
分层,是指表需要按照收藏的规范进行分层。比如:目前有超过70%的表是没有按照收藏的规范来分层。希望能结合一系列的整改措施,配合整体的数据治理,推动用户进行分层治理或者整改;
-
打标,是对业务板块数据域、标签等进行标记。
建模完善度包括以下二个方面:
-
跨层引用:是指用户的作业在DWS、ADS层,直接去访问ODS。这样的形式定义为跨层引用。这种现象说明底层DWD的建设不足,不足以支撑上层。
-
查询覆盖:是用来衡量上层的建设情况。例如:ID号的查询到底是否命中DWS或者ADS层。如果是命中ODS,则说明上层的建设不够好。
四、数据成本治理
元数据应用中数据成本治理是优化数据使用成本最直接的部分。数据成本治理在元数据应用中是重点投入。因为小米的数据量增长比较快,整体的业务成本就上涨也比较多,对成本的诉求也比较高。

图 10 元数据应用-成本治理
1、数据成本治理的起因成本治理是从商务的角度出发,成本的根因最终回归到底层,即主机和整个网络这样的资源;再往上层应用追寻则是存储计算的资源。对主机的成本来说,从商务谈判层面,包括折扣已经做了很大的努力,单纯的再依赖商务层面,无法再挖掘成本优化的潜力。
存储计算的技术也在追赶阶段,尤其涉及到成本,比如:分层存储。此外计算层面的弹性算力也在建设过程中,很难快速把成本治理做到位,把成本降下来。
在当商务已经达到极限,技术层面也在追赶业务,此时从元数据的角度思考成本优化,面临一个简单问题,业务不知道自己有多少数据,这些数据好比就是花了多少钱,最后这些钱到底花在哪里了,应该怎么优化,优化了之后会有什么反馈?。
针对这个问题做了产品层面的分析优化的闭环,即成本分析优化闭环。这个闭环的关键环节简单称作:观现状、查问题、做优化、拿反馈。
-
观现状,就是看有什么数据,花了多少钱;
-
查问题,就是看这些数据到底有没有什么问题,哪些是浪费的,或者钱主要花去处;
-
做优化,就是寻找应该怎么去优化的突破点;
-
拿反馈,就是通过这些优化,确定到底能省多少钱?
为了支撑成本分析优化闭环,对数据成本治理进行了改造。改造主要包括以下四个方面内容:
-
数出一孔,指是使用的数据要跟底层HDFS存储的数据进行对齐,保证数据量的统一计量口径。在成本治理存储在计算中是指存储维度,存储本质上要回归到底层的数据存储。比如:HDFS层面存储的数据, 通过HDFS-Image计量最精确。它会精准的描述每一个文件到每一个路径、以及存储量。数据成本治理的首要工作就是数据与底层HDFS存储的数据对齐,保证存储量的数出一孔;
-
天级账单,由于数据太多,需要及时跟踪数据的费用优化情况。否则选定了数据,过一个月才说这个数据优化能省多少钱,反馈太长,难以完成闭环;
-
按人归属,明确数据对应的使用人。使用数据频度高的人,其名下的表也比较多,对应的的费用也比较高;
-
及时预估,对于任何一个数据相关的操作,都应该能及时预估、反馈数据量及成本。
这些优化,确定到底能省多少钱?
3、数据成本治理成果通过提供成本分析优化的闭环能力,成本治理短期取得了不错的成果,合计优化了 40% 的数据,如图11所示,可以清晰的描述成本治理的效果:
最上侧的曲线表示过去一年公司离线数据的增长趋势;下面的分叉线左侧黑色部分表示治理之前的历史成本曲线;右侧红色线表示顺着历史成本曲线,使用最小二乘模拟出未来业务正常增长情况下的成本曲线;蓝色横线表示假设业务不增长的成本控制线;最下面的橙色表示成本治理后实际的成本曲线;
橙色线与红色线之间的 gap 就是成本治理的价值所在。
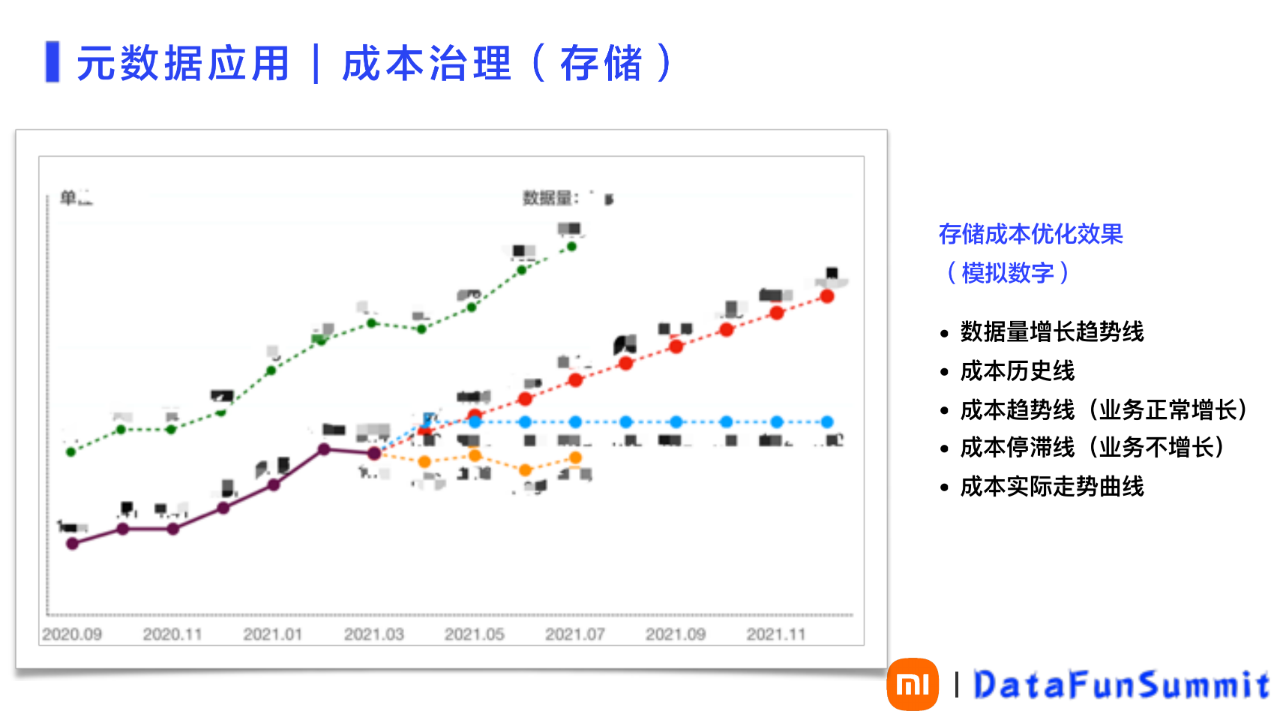
图 11 元数据应用-成本治理
五、数据质量建设
1、数据质量建设的内容首先数据质量建设中,采用了业界比较成熟的一些质量管理方法。如图12所示。
小米的数据质量建设强调以下两方面:
-
数据生产的及时性,指在一个workflow或者一个DAG生产的数据,要保证在限定时间内,或限定时间点必须产出,即数据生产的及时性,强调了对数据生产的保障。数据生产保障包含较多相关因素,如:调度,计算资源等。
-
数据内容质量检查,指生产出来的数据内容产出是否符合要求,是否经过质量检查。
合格的数据产品具有以下特征:
-
唯一性,即主键唯一准确;
-
准确性,即数值要在一个范围内,符合预设数值要求,必须非空等条件;
-
完整性,即每天产出数据的波动情况。如果出现较大的波动率,会影响完整性;
-
一致性,即数据在上下游的链路系统中,对特定字段进行一致性校验。

图 12 元数据应用-质量建设
2、质量建设的技术架构数据质量建设的技术架构,没有采用开源的技术架构,而是采用内部开发的方式。架构示意图所图13所示。
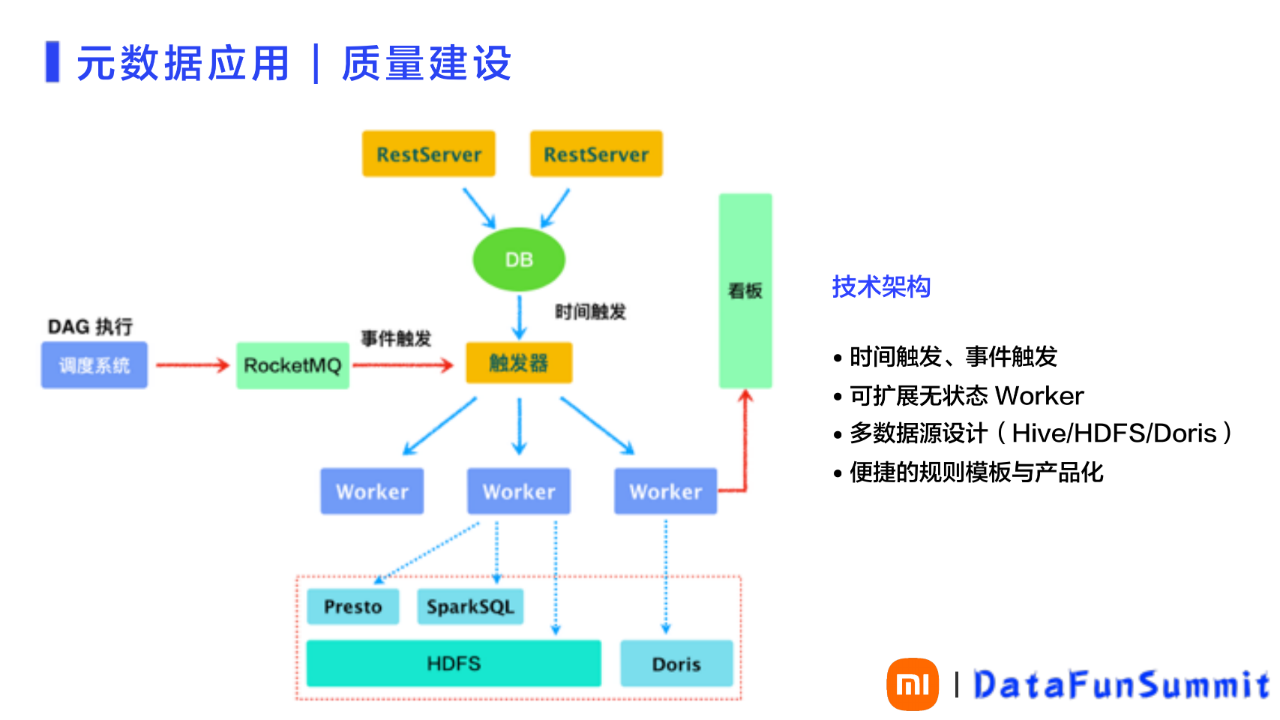
图 13 元数据应用-质量建设之技术架构
1)事件触发
在图12中,最左侧是调度系统对DAG(有向无环图)执行完成、产出DAG对应的表后,专设用户会配置事件触发条件、触发对表的内容进行质量检查,以确定产出的表是否符合质量要求。进行的事件触发配置会把检查事件放在MQ中,质量系统则从消费视角,实现实时的事件触发。即把对内容的质量检查任务,直接挂载到调度系统DAG,在数据产出后,通过事件触发,实现自动对产出数据进行质量检查。
2)时间触发
在图12中,架构的最上层就是RestServer,它是一个可扩展的接收器,接收上述质量规则的配置,或者查询及对结果的查询等。通过DB层面,触发触发器,实现时间触发。比如:业务不是通过DAG实现事件触发,而是可以通过设置的时间点去触发。
3) 可扩展无状态Worker
触发器连接下层的Worker实现服务的执行。Worker是无状态的、可扩展执行机。通过Worker可以实现支持多个数据源,比如:检查HDFS。通过Presto、Spark SQL以及Doris,实现对表的检查。
六、未来规划
根据元数据平台及元数据应用的需求,未来的规划包括三个方面:
-
生产保障联动资源调度;
-
元数据建设的长期路线;
-
业务赋能。
生产保障联动资源调度,是将生产保障从基线、到作业、到调度、到Yarn的全链路打通。包括基线管理、生产执行,还有监控预警等。
计算资源治理,目前还在开发进展中。如图14所示。

图 14 数据管理与应用的未来规划
2、元数据建设的长期路线元数据建设的长期路线就是数据管理,需要回答好两个问题:
如何定义数据的健康定义,如何评判数据的健康程度;
如何治理不够好或者不健康的数据,之后能有什么样的收益。
综合元数据平台和元数据应用中的经验,要回答上述问题,需要从数据治理、数据模型规范、资源的使用与计量、数据安全与防范、数据价值及其挖掘等多方面考虑,进行规划和建设。
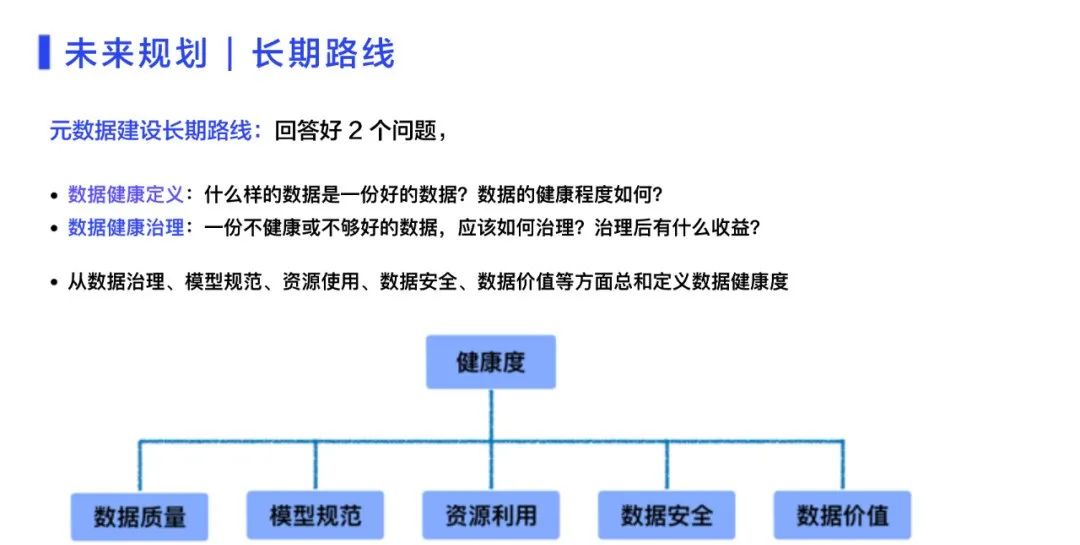
图 15 未来规划-长期路线
3、业务赋能业务赋能就是如何让业务愿意把数据接入到中台。根据以往做消息中间件的经验,需要从业务所重视的痛点出发。比如:对于任何一个业务,它在质量层面都涉及到的重要数据,是否能及时产出;以及产出之后数据的质量是否可信?是否有问题?
根据以往经验,业务赋能需要从数据治理的层面综合考虑,通过质量、效率、成本三个维度,确保能切实解决业务在质量、效率和成本这三个维度的痛点:
-
在质量层面,通过基线管理、数据质量检查、内容检查,包括重保数据产出的整体链路,都能够实现实时监控产出;
-
在效率层面,可以通过规范建模、查询优化,出数加快和对数据地图的优化,让业务找数速度加快。包括元数据血缘的建设,需要加快对业务中问题的追溯,即提升业务的效率;
-
在成本层面,帮助业务实现成本分析优化的闭环,就能够为成本优化提供一些工具或者抓手。
当能够提供这样完整的解决方案,让业务觉得好用时,业务就有意愿进行尝试。解决业务会遇到的风险,必须要从这三个方面得到切实的落实。
以上的经验得到证实:最早小米内部有特别多的MQ,通过与各部门沟通与策划各自的MQ对接业务,最终统一了所有的MQ。其中包括Talos,成为小米数据总线的实施标准。

图 16 未来规划-业务赋能
作者丨勇幸 来源丨公众号:DataFunTalk(ID:datafuntalk) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK