

火焰图与JOL
source link: https://www.tony-bro.com/posts/1695971305/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
火焰图与JOL
在应用监控、调优中,机器的CPU和内存无疑是一个重点,毕竟这是白花花的银子,实打实的成本所在。本番介绍两款本人觉得比较好用并且小巧的分析工具,分别针对CPU和内存。
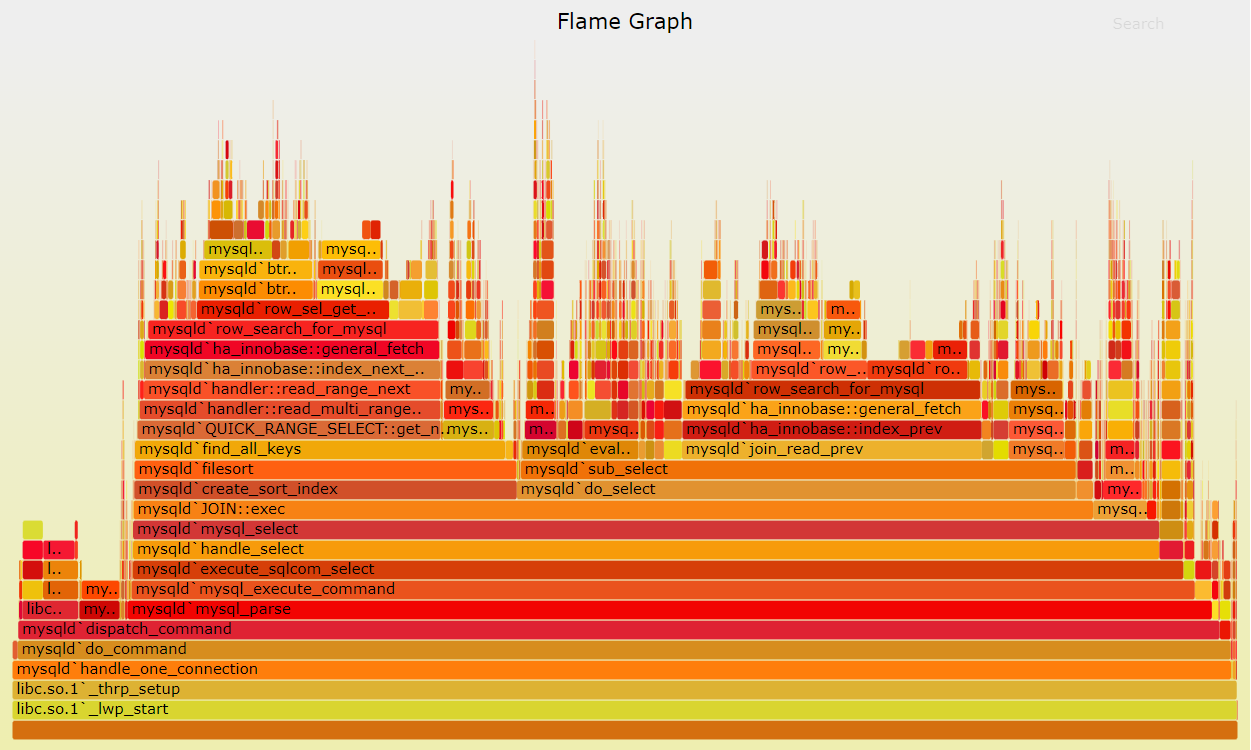
原作者brendangregg在处理 MySQL 性能问题时想要快速深入地理解 CPU 使用情况,因而发明了火焰图。当时作者已经有了常规的profiler和tracer生成的文本统计数据,因此作者的主要目的是解决统计数据可视化的问题,以期高效地洞察监测数据中的信息。
火焰图主要用来分析CPU的使用情况,但是随着发展目前火焰图也有多种细分类型,比如冷热图、对比图等,这里就不细节介绍了,可以去官网进行了解。
火焰图在Github开源,主要采用Perl编写,perl属于解释执行,因此在使用时只需要从github上把项目clone下来并且安装好perl(现在mac应该都有自带)就可以直接运行。项目包含了一些数据源处理工具(stackcollapse-x.pl)和核心出图工具(flamegraph.pl),具体参数在README中有说明,也可以直接使用-h参数来查看。
火焰图的数据源是调用栈(stacktrace),可以从各种性能分析工具获取,根据不同操作系统列出如下:
- Linux: perf, eBPF, SystemTap, and ktap
- Solaris, illumos, FreeBSD: DTrace
- Mac OS X: DTrace and Instruments
- Windows: Xperf.exe
一旦有了一个可以生成有意义的调用栈的分析器,把数据转换成火焰图通常是一件比较容易的事情。
以Linux下典型的分析工具perf命令为例,它是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。通常,它的执行频率是 99Hz(每秒99次),如果99次都返回同一个函数名,那就说明 CPU 这一秒钟都在执行同一个函数,可能存在性能问题。
sudo perf record -F 99 -p 13204 -g -- sleep 30
上面的代码中,perf record表示记录,-F 99表示每秒99次,-p 13204是进程号,即对哪个进程进行分析,-g表示记录调用栈,sleep 30则是持续30秒。运行完成后会生成一个庞大的文本文件,如果服务器有n个cpu,每秒采集m次,持续s秒,那么最终会有 n m s 个调用栈。为了便于阅读,perf命令本身也提供了一个统计工具来统计展示每个调用栈出现的百分比,然后从高到低排列,但是可读性还是不够高。
# perf record -F 99 -p 13204 -g -- sleep 30
# perf report -n --stdio
# ========
# captured on: Tue Dec 9 03:54:11 2014
# hostname : bgregg-test
# os release : 3.13.11.6
[...]
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................. ...................................
#
20.42% 605 bash [kernel.kallsyms] [k] xen_hypercall_xen_version
|
--- xen_hypercall_xen_version
check_events
|
|--44.13%-- syscall_trace_enter
| tracesys
| |
| |--35.58%-- __GI___libc_fcntl
| | |
| | |--65.26%-- do_redirection_internal
| | | do_redirections
| | | execute_builtin_or_function
| | | execute_simple_command
| | | execute_command_internal
| | | execute_command
| | | execute_while_or_until
| | | execute_while_command
| | | execute_command_internal
| | | execute_command
| | | reader_loop
| | | main
| | | __libc_start_main
| | |
| | --34.74%-- do_redirections
| | |
| | |--54.55%-- execute_builtin_or_function
| | | execute_simple_command
| | | execute_command_internal
| | | execute_command
| | | execute_while_or_until
| | | execute_while_command
| | | execute_command_internal
| | | execute_command
| | | reader_loop
| | | main
| | | __libc_start_main
| | |
[...]
火焰图的含义
作者原文翻译:
- 图中的每个框表示堆栈中的一个函数(stack frame)。
- Y 轴显示堆栈深度(堆栈上的帧数)。顶部的框显示了cpu正在执行的函数。在它之下的一切都是它的祖先。函数下面的函数是它的父函数,就像堆栈层级一样。(一些火焰图表实现倾向于颠倒顺序,使用“冰柱布局”,因此火焰看起来像倒过来了一样。)
- X 轴横跨样本总体。它不像大多数图表那样显示时间从左到右的流逝。从左到右的顺序没有任何意义(按字母顺序排序以最大限度地合并帧)。
- 盒子的宽度(也就是占据X轴的长度)显示了它在cpu上执行的总时间或者作为在cpu上执行函数的祖先(基于样本数量)的时间。盒子相对较宽的函数每次执行可能比那些具有窄盒子的函数消耗更多的 CPU,或者它们可能是被调用得更频繁。
- 如果同时运行和采样多个线程,则示例计数可能超过运行时间。
所以观察火焰图的时候,瓶颈往往会以“平顶”的形式表现出来。火焰图的颜色并没有特殊含义,通常是随机选择的暖色,因为表示的是CPU的繁忙程度。
火焰图是SVG 图片,可以在浏览器中打开,与用户互动,注意上图就是可交互的。
- 鼠标悬浮:火焰的每一个盒子都会标注函数名,鼠标悬浮时会在图的底部显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。
- 点击放大:点击某一个盒子会放大,以这个盒子为底占据全部宽度,放大显示该盒子上面的内容。点击后会在左上角显示“Reset Zoom”连接按钮来恢复原样。
- 搜索:图的右上角会显示“Search”连接按钮,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。
Java应用的火焰图
stacktrace对于java来说也是一个很常见、常用的概念,因此采集了java的stacktrace我们一样可以通过火焰图来分析java应用的CPU占用情况,火焰图的原作者也曾在JavaOne上发表过相关的演讲。所以问题的核心依旧是如何高效、无损、完整地收集java的调用栈。
使用操作系统级别的分析工具(比如perf)可能无法获取到Java的方法和堆栈,因为它无法将地址转换为java符号,也不能遍历JVM堆栈。而使用JVM分析工具则可能无法获取到操作系统级别的调用信息。理想情况下,JVM堆栈和系统堆栈应该是可以显示在同一张火焰图内。
看了一下原作的博客并且简单搜了一下,在Linux和mac操作系统下推荐使用async-profiler这款工具,其内部使用了Linux的perf命令结合JVMTI调用(AsyncGetCallTrace),这款工具不需要在Java启动的时候附加额外的JVM参数,并且号称不受安全点倾斜问题影响。
这款工具不仅仅可以用于火焰图,还包含了其他工具的适配,比如使用JFR。同时它直接集成了火焰图,可以在数据收集完毕后直接生成输出火焰图(html文件)。
这款工具使用也是比较方便的,github上可以下载到编译好的各个平台的程序。具体使用方法在Github上面描述的也比较清楚。举个简单的例子:
./profiler.sh --all-user -d 30 -o flamegraph -i 5ms -e cpu -f output.html <pid>
-d 30表示收集时间为30s;-o flamegraph表示输出类型为火焰图;-i 5ms表示采集间隔为5毫秒;-e cpu表示收集CPU数据;-f output.html表示指定输出文件名。
由于底层会调用perf命令,因此在较新的系统上可能会遇到系统权限的问题,同时目前容器技术的兴起,很多情况下程序运行在容器内部,也容易出现一些权限限制问题。具体限制和解决方案在原项目的wiki中也有一些说明(Profiling Java in a container & Ristrictions and Limitations),示例命令中的--all-user也是为了应对权限不足的情况而添加的。
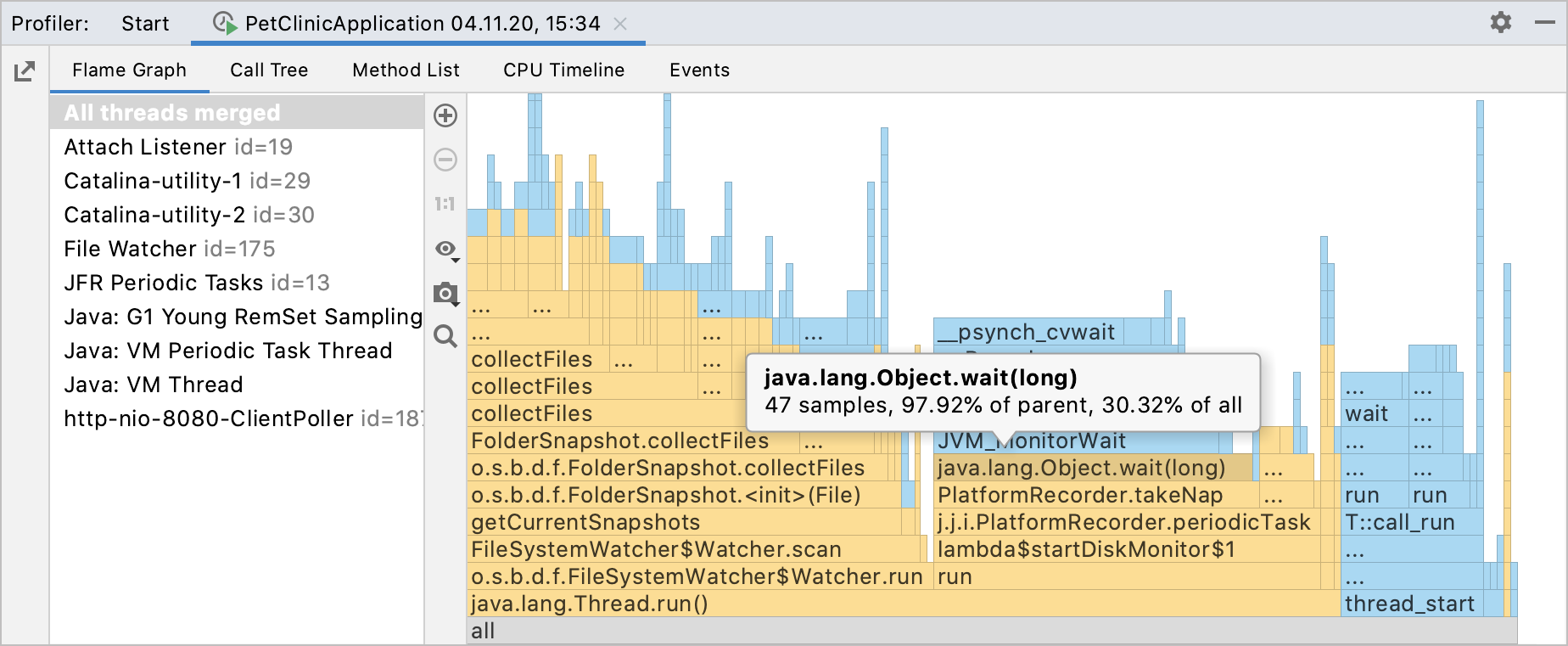
IDEA集成
IDEA自2018.3开始(Ultimate版本)开始提供CPU Profiling Tool,其中就包括async-profiler,IDEA的集成做的很不错,采集完毕后除了火焰图展示,还包括调用树、方法列表、CPU Timeline等展示工具。并且从2021.2开始,IDEA集成的async-profile也支持在windows下使用。详情查看IDEA 2021.2的文档。
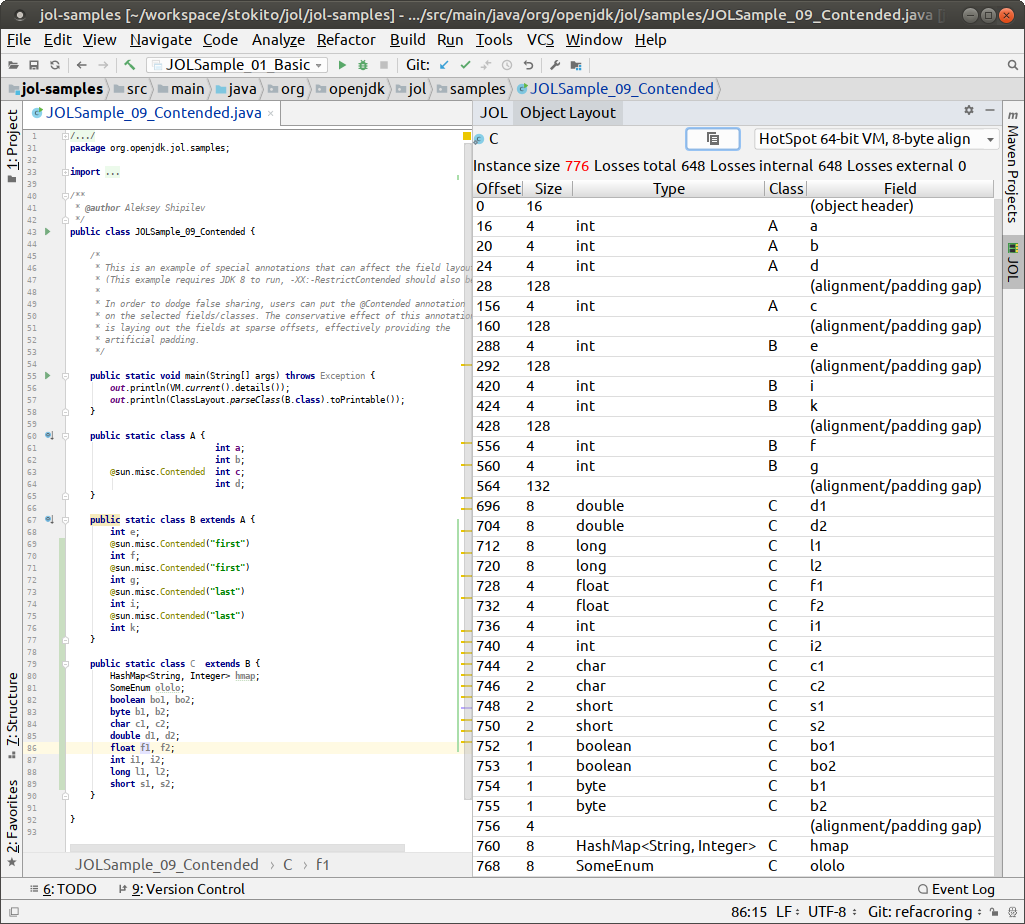
JOL全称为Java Object Layout。它是一个分析JVM对象布局的工具,它也在Github上开源展示,并且提供了可执行工具jar包和maven依赖两种使用方式。包内的工具使用 Unsafe、 JVMTI 和 Serviceability Agent (SA)来解码实际的对象布局、内存占用和引用,这使得 JOL 比其他依赖堆转储、规范假设推断的工具更加准确。
它在Github上的文档还是不错的,比较详细,并且提供了使用样例。这里简单展示一下应用内使用的效果。
以最常见的java.lang.String为例,使用以下代码:
public static void main(String[] args) {
System.out.println(ClassLayout.parseClass("shit").toPrintable());
}
可以得到如下输出(不同操作系统下的输出可能会不同):
java.lang.String object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0xf80002da
12 4 char[] String.value [s, h, i, t]
16 4 int String.hash 0
20 4 (object alignment gap)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
很清晰地展示了String的类对象是如何布局、占用的,包括对象头(markword)、class对象指针、数组长度、int型哈希值以及对齐填充(按8byte对齐)。ClassLayout这个工具类用来展示对象内部信息,不包括对象内的外部引用,因此可以说是对类本身的分析,因此不管输入的字符串内容如何变化,只要是个String,输出的大小都是不变的。
判断一个对象到底会占用多少内存是一个比较常见的需求,也是该工具的一大用处。以常见的观测一定数量字符串实际占用内存大小为例,使用以下代码:
public static void main(String[] args) {
Set<String> set = new HashSet<>();
for (int i = 0; i < 100000; i++) {
set.add(RandomStringUtils.randomAlphanumeric(20));
}
System.out.println(GraphLayout.parseInstance(set).toFootprint());
}
我们在HashSet中存放10w个长度为20的字符串,可以得到如下输出:
java.util.HashSet@58a90037d footprint:
COUNT AVG SUM DESCRIPTION
100000 56 5600000 [C
1 1048592 1048592 [Ljava.util.HashMap$Node;
1 16 16 java.lang.Object
100000 24 2400000 java.lang.String
1 48 48 java.util.HashMap
100000 32 3200000 java.util.HashMap$Node
1 16 16 java.util.HashSet
300004 12248672 (total)
分门别类地展示了哪些部分占用了多少字节以及总计。所以可以很明确地得出结果:10w个长度为20的字符串存入HashSet,大概会占用93mb。GraphLayout这个工具会统计对象的内部占用和引用信息,得出这个对象完整的内存占用情况,所以本人称之为对象分析。
IDEA插件
在IDEA中也有相关的插件,可以直接在插件市场中搜索JOL进行下载安装,但是这个插件主要是用来查看类的布局,也就是上述对类的分析,通过tab来展示布局信息,可以看到编写的类是否适配缓存行。个人觉得实用性不算特别高,不过食之无味,弃之可惜,可以装一下看看,说不定哪天就用到了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK