CVPR 2021 | 针对全局 SfM 的高效初始位姿图生成
Original
chaochaoSEU
计算机视觉工坊
4 days ago
计算机视觉工坊 专注于计算机视觉、VSLAM、目标检测、语义分割、自动驾驶、深度学习、AI芯片、产品落地等技术干货及前沿paper分享。这是一个由多个大厂算法研究人员和知名高校博士创立的平台,我们坚持工坊精神,做最有价值的事~
140篇原创内容
Official Account
Efficient Initial Pose-graph Generation for Global SfM作者:Daniel Barath, Dmytro Mishkin, Ivan Eichhardt, Ilia Shipachev, and Jiri Matas
论文地址:https://www.zhuanzhi.ai/paper/dec76db822ad03e66265875c7477bf49
摘要:我们提出了加速全局SfM算法的初始位姿图生成的方法。为了避免由 FLANN 形成暂定点对应关系和由 RANSAC 进行几何验证,这是位姿图创建中最耗时的步骤,我们提出了两种新方法——基于图像对(通常连续匹配)。因此,候选的相对姿态可以从部分构建的位姿图的路径中恢复。考虑到图像的全局相似性和位姿图边缘的质量,我们提出了 A* 遍历的启发式方法。给定来自路径的相对姿态,通过利用已知的对极几何,基于描述符的特征匹配变得“轻量级”。为了在应用 RANSAC 时加快基于 PROSAC 的采样,我们提出了第三种方法,根据先前估计的内点概率对对应项进行排序。该算法在来自 1D SfM 数据集的 402 130 个图像对上进行了测试,它们将特征匹配速度提高了 17 倍,姿态估计速度提高了 5 倍。
1 引言SfM在计算机视觉中得到了几十年的深入研究。大多数早期的方法采用增量策略,逐步构建重建,并在过程中逐个仔细地添加图像[39, 36, 35, 1, 53, 41]。最近的研究[15, 16, 7, 26, 4, 9, 18, 33, 12, 8, 54]表明,全局方法在重建场景时同时考虑所有图像,比增量技术具有类似或更好的精度,同时更有显著效率。此外,全局方法也不太依赖于局部决策或图像排序。通常,SfM的原理包括以下步骤,如图2所示。首先,在所有图像中提取特征。这个步骤很容易并行化,并且具有O(n)个时间复杂度,其中n是重建中要包含的图像的数量。然后,这些特征通常用于将图像对从最可能匹配到最难匹配的图像对排序,例如,通过视觉词袋 [43]。接下来,通过匹配检测到的特征点的通常高维(例如,128的SIFT[25])描述符,在所有图像对之间产生试探性的对应。然后,通过应用RANSAC [14]来过滤对应关系并估计所有图像对之间的相对姿态。通常,特征匹配和几何估计步骤是迄今为止最慢的部分,两者都对图像的数量具有二次复杂度。此外,特征匹配具有二次最坏情况的时间复杂度,因为它取决于各自图像中特征数的乘积。最后,全局集束调整(BA)得到了成对位姿的精确重构。有趣的是,与初始的位姿图生成相比,这个步骤有可以忽略不计的时间需求,即,在我们的实验中需要几分钟。
图2 全局SfM的原理图本文有三个主要贡献——三种新算法,可以消除基于RANSAC的几何估计的需要,并使基于描述的特征匹配“轻量级”。首先,提出了一种利用部分建立的位姿图来避免基于计算要求的基于RANSAC的鲁棒估计的方法。为此,我们为A∗[17]算法提出了一个启发式算法,即使没有视图之间的度量距离,它也可以指导路径查找。缺乏这样的距离源于这样一个事实,即位姿图的边缘表示相对位姿,因此,无论是全局尺度还是任何平移的长度都是已知的。其次,我们提出了一种通过使用由A∗确定的位姿来使耗时的基于描述符的特征匹配“轻量级”的技术。这种引导匹配方法使用基本矩阵有效地选择关键点,从而通过hashing与位姿一致的对应。第三,提出了一种算法,根据点对点对应的历史来自适应地重新排序——无论在之前的估计中,其中一个或两个点都不一致。该方法利用了这些嵌入的特征点可能代表与场景的刚性重建一致的三维点。这种自适应排序通过引导PROSAC [10]尽早找到一个好的样本,从而加快了鲁棒估计。在1D SfM数据集[52]上进行了测试,例如重建。它们持续而显著地加快了位姿图的生成。
1.1 相关技术鲁棒估计。为了加速鲁棒估计,多年来提出了许多算法。NAPSAC [31]、PROSAC [10] 和 P-NAPSAC [6] 修改了 RANSAC 采样策略,以增加早期选择所有内点样本的概率。PROSAC 利用点的先验预测内点概率等级,并从最有希望的点开始采样。NAPSAC 建立在现实世界数据通常在空间上是一致的这一事实之上,并从局部邻域中选择样本,在这些邻域中,内点比率可能很高。P-NAPSAC 结合了 PROSAC 和 NAPSAC 的优点,首先在本地采样,然后逐渐融合到全局采样中。受 Wald 理论启发的序列概率比率测试 [11] (SPRT) 用于在优于先前最佳模型的概率低于阈值时尽早拒绝模型。所有提到的 RANSAC 改进都考虑了单个、孤立的两视图鲁棒估计的情况。在这里,我们利用在对
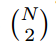
图像对的某些子集进行估计时产生的信息,其中一些图像匹配不止一次。
特征匹配可以通过多种方式加速,例如,通过使用二进制描述符 [40, 2, 50] 或通过限制检测到的特征数量,就像在 SLAM 系统中经常做的那样 [30]。然而,对于一般的 3D 重建问题,这通常会导致不准确的相机位姿 [21]。通常,使用近似最近邻算法,例如 kd-tree 或乘积量化 [29, 23]。基于硬件的加速包括使用 GPU [22]。这些技术都没有考虑到匹配是在多个图像对上执行的,其中在匹配之前,相对姿态可能是已知的,至少大约是已知的。
全局图像的相似性。与匹配(例如视频序列)相比,匹配无序图像集合通常是一项更难、更耗时的任务。这有两个原因。首先,许多图像对可能没有场景的任何常见可见部分,并且浪费了在匹配尝试上花费的时间。此外,不匹配是 RANSAC 的最坏情况,它将运行最大迭代次数,通常比可能匹配的情况多几个数量级。其次,估计对极几何所花费的时间在很大程度上取决于暂定对应关系的内点比率 [13]。内点比率反过来取决于两个观点之间的差异:差异越大,正确的暂定对应关系越少 [28, 27]。一个自然的问题是——是否可以将图像对从最可能匹配到最难匹配或最不可能匹配?图像检索技术通常用于它,例如,可以重用提取的局部特征,通过视觉词袋[43]找到最有希望的候选匹配,然后使用几何约束快速重新排序初步列表[34,42],因为它是在 COLMAP SfM [41] 中实现的。此类系统运行良好,但内存占用很大,现在已被基于 CNN 的全局描述符 [38, 37, 51] 所克服,它们计算速度更快并提供更准确的结果。作为初步步骤,我们使用以下方法生成完全连接的图像相似度图。首先,我们使用 ResNet-50 [20] CNN 提取 GeM [38] 描述符,在 GLD-v1 数据集 [32] 上进行预训练。然后我们计算所有描述符之间的内积相似度,得到一个 n × n 相似度矩阵。相似度矩阵的计算是我们管道的唯一二次步骤。但是,标量乘积运算速度极快。实际上,相似度矩阵的创建和处理花费的时间可以忽略不计。
2. 因定向行走而产生的相对位姿我们提出了一种通过尽可能避免运行 RANSAC 来加速姿势图生成的方法。核心思想利用了这样一个事实,即在从图像集合中估计第 (t+1) 个图像对之间的相对位姿时,我们会得到一个由 t 个边(即 t 个视图对)组成的位姿图。该位姿图通常可用于估计姿势,而无需运行类似 RANSAC 的稳健估计。在接下来的描述中,我们假设视图对是按照它们的相似度分数排序的。因此,我们从最相似的视图对开始姿态估计。让我们假设我们已经成功匹配了 t 个图像对,因此,我们得到了位姿图
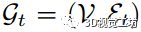
,如图3所示。
因此,视图vs和vd之间的相对位姿通过W被计算为φ(W)。
式(1)的问题是,一个错误估计的姿态φ(f),f属于W,使整个φ(W)错误。因此,我们的目标是在给定的距离内找到multiple walks,即最大深度被限制,以避免无限长的walk。返回的walk将按顺序和立即计算,请参见Alg.1。每当发现一个新的walk W时,从姿态φ(W)和源图像和目标图像之间的对应关系vs和vd分别计算出它的inlier ratio。
Termination。终止。有两种情况下 寻找和测试行的程序终止。它们是如下。1. 当没有找到更多的walk时,这个过程就结束了,因为在最大距离内没有找到更多的行。2. 如果找到了一个相当好的姿势P,这个过程就会终止。我们认为一个相对位姿是合理的,如果它至少有Imin的异常值。
Pose refinement。如果从其中一次walk中成功获得位姿,则仅从位姿图Gt的边缘计算,而不考虑图像vs和vd之间的对应关系。为了提高精度和获得P∗,我们采用了由新估计的模型P初始化的迭代重新加权的最小平方拟合。
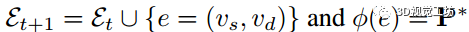 Failures
Failures。在某些情况下,在视图vs和vd之间至少存在一次walk,但隐含的位姿是不正确的,即,它不会导致合理数量的倾斜度。在这些情况下,我们应用了传统的方法,即基于RANSAC的鲁棒估计。
Visibility。在O(1)时间内,可以通过联合查找算法在 O(1) 时间内确定在视图 vs 和 vd 之间的姿势图中是否至少有一次walk。平均而言,更新的时间复杂度为O(log(n))。
Parallel graph building。通过使用每个线程匹配下一个最佳视图对的读写器锁定机制,构建图 G、检查可见性、查找和评估在多个 CPU 上并行运行是有效的。读取器是试图在两个视图之间寻找游走的进程,或者是检查视图 vs 是否从 vd 可见的进程。一个进程只有在向姿势图添加新边或更新联合查找方法以进行可见性检查时才成为写入者,这两者都只需要几个操作。
2.1.位姿图遍历如何有效地在视图 vs 和 vd 之间找到一个步行是一个相当重要的问题。有许多图遍历,但是,其中大多数不适合在合理的时间内在大图中返回游走。我们选择 A* [17] 算法,因为当存在良好的启发式算法时,它可以很好地完成此类任务。在本节中,我们提出了一种通过为 A* 算法定义启发式方法来获得位姿图 Gt 中多次游走的方法。目标是定义一个启发式方法,它在访问尽可能少的顶点的同时引导 A∗ 算法从节点 vs 到节点 vd。由于给定了一个相对位姿图,我们无法定义度量,即测量视图对的欧几里得距离。当具有相对位姿时,全局和局部尺度仍然未知,因此,所有平移都有单位长度。因此,不清楚两个视图彼此接近还是远离。建议的启发式算法由两个函数组成。
3. 带有位姿的引导匹配在匹配图像集合时,最耗时的过程通常是局部描述符匹配 [21],也就是建立暂定对应关系。原因是它具有 O(n2) 复杂度,分别与局部特征的数量(即单个图像对)和图像的数量(即整个集合)有关。我们已经解决了第二个问题(参见第 1.1 节),但是匹配单个图像对仍然需要大量时间。加速特征匹配的常用方法是使用近似最近邻搜索,而不是精确搜索,例如使用 FLANN [29] 中实现的 kd-tree 算法。然而,即使是近似匹配仍然需要相当长的时间并降低相机姿势的准确性 [21]。我们提出了一种替代解决方案——利用来自当前姿势图中的步行的姿势来建立暂定的对应关系。通过仅检查与姿势一致的对应关系,这些姿势将用于使标准描述符匹配“轻量级”。Guided feature matching with pose. 让我们假设我们有一组关键点 Ki, Kj 分别在第 i 个和第 j 个图像中,以及从第 i 个图像到第 j 个图像的相对姿态 Pij = (tij, Rij)∈SE(3)。人们可以很容易地计算出基本矩阵 Eij = [tij]×Rij,并使用它通过 Sampson 距离或对称对极误差 [19] 来测量点对的距离。因此,目标是找到点对 (pi, pj),其中 pi ∈ Ki, pj ∈Kj 和 (pi, pj,Eij) 小于内点-离群点阈值。与使用 L2 范数在所有可能关键点的高维描述符向量上定义特征匹配的传统方法相比,我们建议使用基本矩阵选择一小部分候选匹配。因此,描述符匹配变得明显更快。由于在 2D 中进行匹配,该过程可以通过散列而不是蛮力或近似成对过程来完成。使用基本矩阵,在源图像中找到可能的点对降级为在目标点中找到相应的极线投影到正确位置的点,即,到源图像中的选定点上。因此,可以根据源图像中的极线将目标图像中的点放入 bin 中。一个直接的选择是在对极线的角度上定义 bin,如图 5 所示。我们在进一步的部分中称这种技术为对极散列 (EH)。请注意,即使内在相机参数未知,EH 也适用,因此,我们只有一个基本矩阵。
图5 对极哈希。图像 C2中的点 p2 被分配给 C1(灰色区域)中对应的极线 l 选择的 bin。bin 定义在 C1 中对极线的角度上。对极是 e1 和 e2。让我们将第二个图像中的点(x,y)的第一个图像中对应的上极性线l的角度表示为α(x,y)∈[0;π)。由于上极性几何学的性质,某些α(x,y)角是不可能的。因此,我们定义了由有效角组成的间隔,因此,我们将用一些箱子覆盖为[a, b]:
Point (0, 0) 是第二个图像的左上角,w2 是它的宽度,h2 是它的高度。散列点时,bin 的大小将为 (b−a)/( #bins)。这是实践中的一个重要步骤,因为有时对极点远在图像之外,因此角度范围 < 1。如果没有自适应 bin 大小计算,算法在这种情况下不会加速匹配。注意 [a, b] 是 [0, π) 当对极落在图像内时。在进行传统的描述符匹配时,我们只考虑那些位于相应 bin 中且 Sampson 距离低于用于确定姿势的阈值的匹配。执行引导后,对 2 到 30 个可能的候选对象而不是所有关键点进行描述符匹配。为了进一步清理它,我们应用具有自适应比率阈值的标准 SIFT 比率测试 [25, 21],这取决于最近邻居的数量——池越小,比率测试越严格。详细信息已添加到补充材料中。如果找到一个好的位姿,则在 A* 之后应用匹配过程。由于 A∗ 需要一组对应关系来确定位姿是否合理,因此我们使用来自当前图像可见的点轨迹的对应关系。当成功匹配新图像对时,将计算并更新多视图轨迹。由于全局和增量 SfM 算法都需要点跟踪,因此此步骤不会增加最终处理时间。
4. 自适应对应关系排序在本节中,我们提出了一种策略,在大规模问题中进行成对相对位姿估计时,自适应地设置 PROSAC 采样 [10] 的点对应权重。PROSAC 利用点的先验预测内点概率等级,并从最有希望的点开始采样。逐渐地,抽取不太可能导致所寻求模型的样本。所提出算法的主要思想是基于这样一个事实,即在匹配图像集合时,在一张图像中检测到并与其他图像匹配的特征经常出现多次。因此,在 PROSAC 采样中将首先使用包含较早内点点的对应关系。相反,之前图像中的异常点应该稍后绘制。假设我们得到第 t 个图像对以匹配关键点 Ki、Kj 的集合。来自任一组的每个关键点 p 的得分为 s(t)p∈ [0, 1] 用于确定其在所有关键点中的异常值等级。在成功估计图像对的姿态 Pij 后,我们得到了 (p, q) 的概率 P ((p, q) | Pij) 是给定位姿 Pij 的异常值,其中 (p,q) 是一个暂定的对应关系,p ∈Ki,q ∈Kj。概率 P ((p, q) | Pij)可以计算,例如,在 MSAC [49]、MLESAC [49] 或 MAGSAC++ [6] 中,从假设正态或 χ2 分布的点到模型残差。由于我们不知道概率 P (p| Pij) 和 P (q| Pij) 如何相关,我们假设 p 和 q 与刚性重建一致是独立事件,因此, P((p, q)| Pij) = P(p|Pij)P(q|Pij)。为了能够分解概率 P ((p, q) | Pij),我们假设 P (p|Pij)=P (q| Pij) = sqrt(P ((p, q) | Pij))。然后在第 t 个图像对匹配为 s(t+1)p= s(t)pP (p| Pij) 和 s(t+1)q = s(t)q 之后,使用此概率更新分数 sp 和 sq。让我们设置 s(0)p = 1,因为所有关键点在开始时都可能是异常值。当使用 PROSAC 采样匹配第 (t + 1) 个图像对时,对应关系根据它们的离群点等级 s(0) p 逐渐排序,使得第一个最不可能是离群点。
5. 实验旋转和平移误差(以角度为单位)和处理时间(以秒为单位)的累积分布函数如图 6 所示。我们在这里不包括 MST,因为它匹配的图像对(9922)比其他方法(402)少得多 130)。在准确性方面,基于 A* 的技术导致最准确的旋转矩阵,同时具有与基于广度优先和穷举匹配相似的平移误差。在处理时间方面,所提出的基于 A* 的技术导致比 EM 或 BF 更有效的姿势图生成。请注意,处理时间曲线中的断点是由将 RANSAC 迭代的最大次数设置为 5000 引起的。这是为了避免在内点比率较低时运行 RANSAC 时间过长。
图 6 在 1DSfM 数据集的所有场景上,由不同初始化技术生成的姿态图的误差(以 ee 为单位)和处理时间(以秒为单位)的累积分布函数。所有算法都返回了 402 130 个姿势。成对姿态估计算法的平均、中值和总处理时间如表 1 所示。运行时间也包含这些情况,当 A* 或广度优先遍历没有找到有效姿态时,因此, GC-RANSAC 用于恢复姿势。A* 算法导致几乎一个数量级的加速,其中值时间约为 比GC-RANSAC低20倍。它验证了所提出的启发式算法,即广度优先算法明显慢于 A*。因此,所提出的启发式方法成功地指导了姿势图中的寻路。
我们比较了使用或不使用由 A* 算法确定的姿势的特征匹配速度。在 FLANN 和蛮力匹配中,这意味着我们找到了所有导致对极误差小于内部异常阈值的候选匹配。然后通过基于描述符的匹配选择最佳候选者。运行时间在表 2 中报告。使用姿势显着加快了基于 FLANN 的算法和蛮力算法。与传统的基于 FLANN 的特征匹配相比,所提出的对极散列可实现 17 倍以上的加速。此外,通过对极散列,可以精确地找到邻居,而不是像 FLANN 那样进行近似。
表 4 显示了对 PROSAC 使用不同对应排序技术的稳健估计的平均、中值和总处理时间(以秒为单位)。比较了三种方法:最初为 RANSAC 提出的均匀匹配(无序);PROSAC 当对应关系根据其 SIFT 比率排序时 [10];以及考虑来自早期估计的点的先验信息而提出的自适应重新排序。与均匀采样相比,根据其 SIFT 比率对对应项进行排序将估计速度提高了 10%,而所提出的自适应重新排序导致平均额外的 8% 加速。
表 3 报告了由传统详尽匹配 (EM)、广度优先图遍历 (BF)、建议的基于 A* 的图遍历和使用最小生成树 (MST) 生成的姿势图初始化的 Theia 结果。虽然基于最小生成树的姿态图的生成速度非常快,但可以看出全局 SfM 算法不足以提供合理大小的重建。由 MST 初始化时重建的平均视图数量明显低于使用其他技术。可以看出,所提出的基于 A* 的方法导致与传统方法相似的视图数量和相似的错误。
在图 7 中,A*traversal 访问的平均节点数(左)和获得的准确相对姿势的比率(右)被绘制为权重 λ 的函数。不同的曲线表示不同的最大深度。
6.结论与初始姿态图生成相比,全局 SfM 算法的最终集束调整的时间需求可以忽略不计。为了将这一步加快近一个数量级,我们提出了三种新算法。用于估计来自 1D SfM 数据集的所有场景的位姿图的标准程序(即,FLANN 的特征匹配;类似 RANSAC 的稳健估计的姿势估计)在单个 CPU 上总共花费了 726 487 秒——大约 202 小时。通过使用所提出的算法集(即基于 A* 的姿态估计;用于匹配的对极散列;自适应重新排序),总运行时间减少到 105593 秒(29 小时)。在实验中,A* 在 93:8% 的图像对中找到了有效位姿。因此,由 RANSAC 进行的传统基于 FLANN 的特征匹配和姿态估计仅应用于 6:2 % 的图像对。
备注:作者也是我们
「3D视觉从入门到精通」特邀嘉宾:
一个超干货的3D视觉学习社区原创征稿
初衷3D视觉工坊是基于
优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是
3D视觉、
CV&深度学习、
SLAM、
三维重建、
点云后处理、
自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为
paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的
稿费,我们支持知识有价!
投稿方式邮箱:
[email protected] 或者加下方的小助理微信,另请注明原创投稿。

▲长按加微信联系

▲长按关注公众号

