

微信游戏推荐系统大揭秘
source link: https://zhuanlan.zhihu.com/p/367697065
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
微信游戏推荐系统大揭秘
作者:boxianlai,腾讯 WXG 应用研究员
这篇文章整理于 2020 年 12 月 31 号在腾讯 WXG T 族开放技分享材料,分享内容是我们在搭建一套适合微信游戏业务特色推荐系统过程中的设计方案和实践经验。这套系统从 18 年底开始设计 19 年初开发完成,现在已经在业务上运行了一年多,当前部门所有的推荐业务都已经应用上这套能力,包括所有精品 app 游戏分发和游戏相关的内容推荐、几万款小游戏分发,服务着几亿微信游戏玩家。在实际业务应用中,它切实满足了很多业务对推荐的诉求,同时在业务核心指标上有了不错的提升,下面是最近一段时间三个不同类型应用场景:小游戏推荐、游戏精细化运营挖掘、定向分享收到的业务产品同学的反馈,没有商业互吹,都是真实对业务指标有提升。
我们在搭建过程中很多设计思想和实践经验相信也对其他 BG 的同学有借鉴价值,所以把此次分享内容整理成了一篇 km 文章,希望对大家有一些帮助。
1、业务和项目背景介绍
微信增值业务部当前核心业务是游戏,也就是在微信场景下连接游戏玩家与游戏,同时给玩家提供丰富的游戏服务,比如攻略、战绩、视频、直播等内容,王者周报、和平周报、群排行榜、礼包等服务,另外还为玩家提供建连的渠道,玩家可以在游戏中心、游戏圈里面找到有共同兴趣,志同道合的小伙伴,一起玩更精彩;说了那么多,用一句话概括我们的游戏业务就是:在微信场景下,帮助游戏玩家找到感兴趣的好游戏,并且让玩家们游戏玩得更好,玩得更开心。
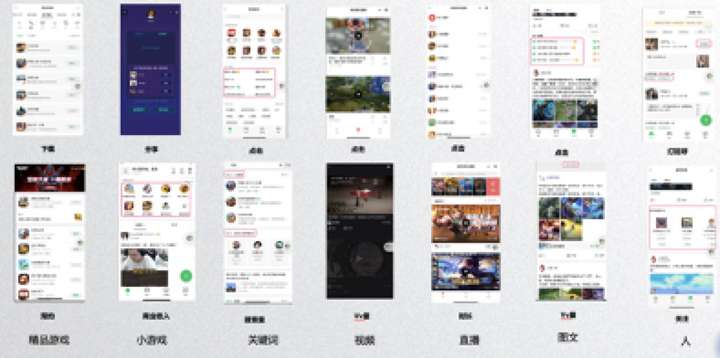
从上图列举的推荐场景可以看出,我们推荐系统也是围绕这个方向来落地应用的,在帮助玩家找到好游戏方面我们有精品 app 游戏分发、小游戏分发场景以及优化用户通过搜索找到目标游戏的场景;游戏服务方面我们有视频流、图文流、直播流等内容推荐场景;在玩家们建连方面我们有玩家关注推荐、游戏 kol 推荐、玩家广场等产品。在上述各种类型的推荐场景之下,每个场景又会有各种各样的业务目标,比如精品 app 游戏除了下载启动,还有新游上线前预约推广,即需要找到对游戏 ip 感兴趣的潜在用户,提升预约率;而小游戏除了启动注册目标之外,同时小游戏还有自己的商业化目标,需要预估商业价值和以流量 roi 为优化目标的场景。而对于游戏内容除了点击转换这个目标之外,还有视频完成度、下翻率、播放时长、人均 vv 等目标。
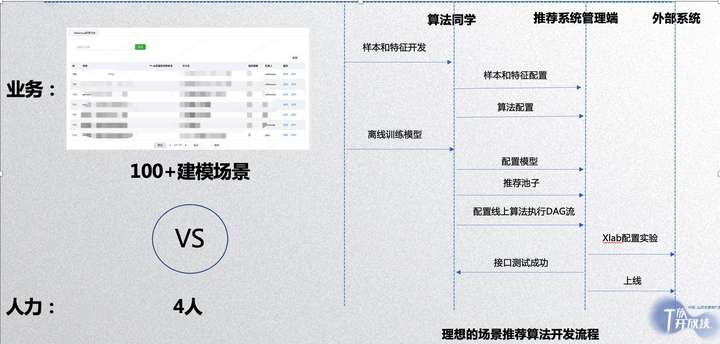
事实上,上面列举的场景只是我们众多推荐场景中的一部分,从我们推荐系统管理端来看,我们已经建立 100+场景模型(一个 taskgroup 对应一个场景接口)。但现实矛盾点是我们只有四个推荐算法同学对接业务,负责的后台也只有一个同学;针对这个矛盾点,我跟后台同学讨论一个理想的推荐场景的开发流程,希望把开发过程尽可能配置化,低代码化,如上图右边部分,算法同学只需要开发场景相关的样本和特征,并将特征表和样本表配置到推荐管理平台,在管理平台上选择合适的算法并配置参数,提交一个离线训练任务,完成后将模型文件和推荐池子相关 hdfs 路径配置到管理平台分发到现网机器上;然后在实验系统 xlab 上配置实验,将实验参数配置到统一推荐管理平台上对应的场景接口(taskgroup)参数中,打通场景接口和实验系统流量分配逻辑,最后把场景接口对应的 taskgroup 名字给到业务后台同学,业务后台同学根据这个名字调用统一的推荐接口,获取推荐打分接口,完成一个场景的推荐开发。为了达到上述的效果,我们设计了推荐系统的整体架构:
主要包括四个部分,离线机器学习平台、统一推荐管理平台、在线推荐引擎以及周边系统;
Ø 离线机器学习平台
模块的核心功能是负责离线数据处理,包括特征、画像开发、场景样本开发、特征工程等相关工作;也负责离线模型训练、离线与线上数据交互、批量打分等等。
Ø 统一推荐管理平台
推荐管理平台是推荐算法开发同学日常工作中使用最多的模块,配置算法、开发特征、配置模型、数据分发、定义推荐系统执行 DAG 图、接口 debug、线上推荐问题排查等等,可以说推荐系统涉及到的工作都在这个平台上完成。
Ø 在线推荐引擎
在线推荐系统负责提供实时接口服务,包括三个核心部分:用户特征模块、推荐执行引擎、共享内存模块;
用户特征模块: 存储用户画像和用户行为数据,起初我们使用 strkv 来存储,根据数据更新周期分为实时特征、小时级特征、天级特征、月级特征;但是月级和天级用户量非常大,上线需要十几个小时,今年统一切到了 featurekv。featurekv 写速度要远快于 strkv,但当时还不支持线上实时写入,所以实时特征我们还是用 strkv。
推荐执行引擎: 负责执行线上推荐逻辑调用,包括接收业务请求,拉去特征,拼接预测样本,调用算法模块,完成推荐打分;其中核心模块是 controller,它负责解析和执行算法同学定义的 DAG 执行图(我们把推荐的执行逻辑定义为一个 DAG 图);还有算法模块负责具体算法实现,每个算法实现是 controller 可调度执行的最小单元(除了机器学习算法实现之外,我们把一些常用的业务逻辑,比如混排、过滤逻辑等也封装成这样的执行单元,也就是后文提到的 stage)。
共享内存模块: 线上预测的时候,同一个接口不同用户请求推荐系统都会用到同一份 item 特征,模型文件,特征编码文件,推荐池子,这种类型数据常驻内存可以减少单次请求耗时,所以后台同学开发了管理这些数据的共享内存模块,结合架构部文件分发工具,算法同学可以指定文件 hdfs 路径,文件分发工具将文件分发到所有线上机器,共享内存模块检测到数据版本更新,将最新数据加载内存,完成线上数据更新。
Ø 周边系统
除了上述推荐系统运行相关的模块之外,还需要实验系统支持算法同学迭代场景模型和实时监控系统可以观测到算法上线之后的效果,线上问题的快速定位。
实验系统: 我们使用架构部和基础产品部提供的 xlab 实验系统,在推荐系统 controller 模块部署实验系统代理,算法同学在 xlab 上配置完实验之后,将实验系统参数配置到推荐接口中,就可以打通实验系统流量分配和推荐系统。
实时监控系统: 实时数据分析之一块,我们部门搭建了 Druid 实时数据分析系统,支持实时数据监控和效果可视化,整体流程后面会讲到。
为了实现上述推荐系统整体架构,我们前期做了大量的调研,邀请了公司内外团队过来分享,详细对比了各个解决方案,对推荐系统各模块技术选型以及公共组件等都做了比较详细对比,下面是我们构建整套系统技术选型和对应的组件:
机器学习方面,传统机器学习我们基于 spark 搭建模型训练 pipeline,而深度学习使用 tensorflow,增量更新模型我们使用 flink 来实现,涉及向量检索召回服务方面,我们搭建了 faiss 服务,实时数据分析我们选择了 druid。
配置和存储方面,我们使用 pg 库存储离线数据处理相关的所有配置,使用 mysql 存储与线上相关所有配置,而 hdfs 是我们数据中转站。
推荐引擎方面,我们基于微信内部的 svrkit 框架搭建的一套 c++推荐服务。
实际搭建过程中发现很多功能模块公司内兄弟部门都有非常好的实现,我们直接拿来主义,比如调度方面直接使用 telsa,实时计算方面直接用 Oceanus 工具,深度学习可以直接使用 spark-fuel 和 yard,存储这一块架构部同学提供了文件分发工具、featurekv、strkv 等。深度学习线上应用上,我们直接使用架构部封装的 HIE(hybrid_inference_engine)有了这些组件大大提升了我们搭建和维护这套系统的效率,在这里也对负责相关组件的同学表示感谢。
除了工具调研之外,我们还邀请了当时在推荐系统方向做得比较好的团队过来分享经验,包括公司内的神盾、看一看、无量推荐系统团队,也邀请外部公司的微博团队。希望从这些团队实践经验中吸取养分,找到适合微信增值业务特点的解决方案。事实上,这些经验帮我们少走了很多弯路,我们的解决方案在业务适配方面做得还不错,在应用过程中功能没有大的改动,后续也只是在上面生长出更多能力。所以也是这次写这篇文章的目的,希望我们的实践经验,可以给大家带来一些启发。接下来会详细介绍各个模块实现细节。
2、离线机器学习平台设计
上面介绍整体架构提到离线平台核心工作包括,数据 ETL、特征开发、样本开发、特征工程、模型训练和预测、线上和离线数据打通等工作。其中特征工程、模型训练和预测、线上线下数据打通是任何一个场景建模都是需要做得工作,离线平台通过工具化和流程化实现通用组件,避免重复工作。而数据 ETL、特征开发、样本开发是与业务场景强绑定,很难通过自动化方式实现,需要算法同学结合业务目标定制化实现,离线平台提供基础工具,帮助场景建模同学提高开发效率,下图是离线平台实现逻辑:
从下往上分别包括底层数据源接口,数据挖掘基础工具库,这两部分主要帮助算法同学提升日常数据开发效率;往上是场景建模过程中核心三个组件,算法库、特征工程、业务样本模块;算法库包含两个部分,一个部分是基于 spark 实现,另一部分是基于 tensorflow 实现,这里没有使用 telsa 训练组件,而是自己做了二次开发,主要原因是离线算法需要和线上引擎数据协议进行打通,比如我们需要将训练好的模型和相关文件封装到一个 pb 文件中,直接部署到现网机器可以拉去到的地方,不需要每个算法同学都要单独实现数据部署逻辑;另外我们希望模型训练可以跟数据处理逻辑无缝衔接,减少数据中转。
特征工程主要包括特征开发、特征处理、特征评估等涉及到特征相关的操作都封装到单独模块中,方便算法同学对特征进行单独分析和测试;涉及到样本处理工作我们放在样本模块中完成,包括样本采样逻辑,不同目标样本处理,还有一些小流量场景需要多周期样本处理等等。再往上实现了基于 DAG 图的机器学习 pipeline,目的是将场景整个建模过程通过有向无环图的方式管理起来,数据读取逻辑被定义为节点,数据操作逻辑被定义为边,节点只关心从物理存储中拉去数据;边主要是数据处理逻辑定义,不关心数据来源;这样数据读取和数据操作进行节藕。我们根据定义的边和节点,可以组合出不同的 DAG,比如模型训练、模型预测、号码包生成、外部接口等等,供上面应用层调用。最上面是我们推荐系统管理端,我们希望与模型相关的工作都可以通过配置化方式进行。下面详细介绍核心模块实现细节:
Ø 底层基础库
基础库提供了开发过程中常用基础工具,目标是帮助开发同学提升日常数据处理的效率,主要包括 tdw 操作接口封装和通用工具封装,如下图所示:
tdw 提供原始数据接口,在实际业务开发过程中并没有那么友好,比如 spark 读取 tdw 表数据,需要先配置 spark 程序入口环境,初始化 tdw tool 工具,处理表分区,然后再调用表读取 api 进行读取;其中前面步骤都是通用重复的工作,所以在平台提供的 api 基础上,进行二次封装。在开发过程中,开发同学不需要关心环境变量和参数配置,直接初始化封装的类,然后使用简易接口进行表操作和表处理,提升工作效率。
通用工具,其实是把日常工作中都会用到的能力进行封装,比如日期处理,日志处理,编码解码以及类型转换等。以前这些小工具都散落在各个地方,现在有协作工程,能力也慢慢积累起来了。另外与业务相关的工具我们也做了收拢,比如游 ID 间相互转化,游戏品类 ID 和名称相互转化等等,这些业务上通用的能力我们也集成到基础库中,不需要每个同学重复实现。
Ø 算法库设计
算法库设计的核心是扩展性,一方面可以快速便捷扩展新的算法进来。在实际业务应用中,我们不需要那些花里胡哨,很难落地应用的算法,需要的是那些能解决业务问题,可以快速与线上打通,并验证效果的算法;另外一方面算法库可以便捷的集成外部团队的能力,将外部专业团队成熟的能力快速应用到业务中,解决业务问题。出于上述考虑,也吸收公司内其他团队经验,设计了下面这个架构:
算法基类定义了算法基本操作,并将算法通用操作提前实现,比如模型参数初始化,模型部署操作等,其他算法直接继承即可;然后分别定义了分类算法、聚类算法、相似度算法、深度学习类算法还有 nlp 相关的算法抽象操作。最后是具体算法实例的实现,分类算法实现了常用的如 LR、FM、RF、xgb 等;聚类有 kmean;相似度算法实现了三种类型相似,基于内容、基于用户行为序列、这二种相似算法都是将 item 或者 user 进行向量化,然后通过向量内积计算 item 或者 user 之间的相似度。
在游戏中心视频相关推荐场景实验数据来看,基于内容向量化效果稳定性最好,推荐出来的内容基本符合认知,比如鲁班七号的视频,推荐出来都是与鲁班或者射手相关的内容。在深度学习方面核心是打通数据流程,训练和线上预测都依托 tensorflow 和 tf-serving 通用框架,接下来也会详细介绍整体流程。对于 nlp 相关算法,主要是基于 hanNLP 来实现了包括常用的分词、实体识别、文本分类等功能。最后通过工厂方法实现对应算法实例路由。
Ø 深度学习流程设计
2019 年下半年游戏中心很多场景对混排和多目标优化能力诉求越来越强,包括内容 feeds 流、游戏 tab feeds 流里面精品游戏、小游戏等不同类型不同目标的混排。最开始我们采用的方案是增加规则混排逻辑,比如按比例混排,给定概率混排,根据模型打分分数运算混排等。后来还采用双层排序逻辑:先预估用户对不同类型的偏好分布,再根据这个偏好分布从不同类型的已排序好的列表中选择对应的 item,生成最终的排序列表。这些方式可以满足业务需求,但是指标没有显著提升,核心原因是层与层之间是割裂的,没有作为一个整体去优化,而业界成熟的做法是把不同层通过网络结构结合在一起,为此我们在当前能力的基础上,开发了一套流程来支持 nn 能力。
如上图所示,深度学习训练流程是在原有的机器学习平台的基础上,通过集成外部能力来实现的。根据不同的业务需求,我们实现了两条不同的训练路径,一个是在 tesla 平台上,基于 spark-fuel 来实现,应用于线上业务;另外一个是基于数据中心笛卡尔系统+yard 来实现,应用于需要推荐、图像、文本挖掘等能力的业务。我们主要开发工作包括:在算法库中增加一个算法模版,这个模版的工作是把业务训练数据生成下层对接系统可以处理的格式(当前推荐业务使用 libsvm 格式),并将生成好的数据持久化到 hdfs 上;然后基于 tensorflow 实现网络结构、数据读取模块、以及模型持久化模块;最后把模型推送到线上,而线上 tensorflow-serving 是后台同学基于架构部 HIE 实现的。需要注意的是在线上使用的时候,要保证特征编码文件与模型文件保持原子更新。有了这套训练和线上预测框架之后,算法同学可以发挥的空间就更大了,除了推荐算法上落地应用外,我们游戏直播里面的英雄识别、游戏人生漫骂识别等涉及图像、文本相关的服务也都应用这一套能力,具体细节这里就不展开讲。
Ø 页面配置化设计方案
下图是我们现网统一推荐管理端页面,包含两个大模块:推荐系统和数据资源管理。推荐系统包括我们特征管理、离线模型训练配置、线上推荐接口执行流(json 表征的 DAG 图)配置、还有就是推荐接口调试和问题排查的 debug 工具。数据资源管理主要涉及到离线数据和线上数据打通部分,包括用户特征导入 kv 和 item 特征、推荐池子、模型文件等推送到现网机器的定时分发任务配置。
统一推荐管理端把现网推荐开发涉及到的工作都包含进来了,使得离线数据挖掘和线上业务上线推荐模型代码最小化,大大提升了场景算法迭代效率。管理端设计上,如下图所示我们主要拆解成离线和在线两个部分:
离线部分对接的是离线计算平台和离线数据部署模块,通过配置相关的参数,完成场景数据开发、模型训练、数据上线的整个过程。算法同学在离线部分页面的配置信息,我们会存储在 tpg 库中。离线训练模型的时候,通过指定场景配置的算法 ID,就可以检索到存储在 tpg 表中算法 ID 对应的算法相关的参数信息,并将它们封装到算法上下文中(algorithmContext),然后根据配置信息拉取数据生成训练样本,调用算法同学指定的算法训练模型,输出评估指标,最后将模型部署在对应路径下,完成离线训练。离线数据部署配置背后隐含了两个部分工作,第一个是离线特征出库有一个 dataDeploy 模块,会根据算法配置信息上的上线状态,拉取需要上线的特征,并将这些特征序列化成定义好的 pb 格式,写入 hdfs 中。另外一个是后台同学开发的数据 upload 工具,根据算法同学配置的数据相关信息(信息存储在后台 mysql 中)利用 Hadoop 客户端从 hdfs 路径下拉去数据,定时导入到现网 kv(featurekv)或者推送到现网机器。这部分工作对于场景算法开发同学来时是透明的,他只需要完成页面配置即可。
在线部分对接的是现网数据和推荐引擎,包括现网模块配置、stage 配置、taskgroup 配置、task 配置、场景相关的资源配置。这些配置里面的每一条记录都会有一个名字标识,比如线上实现的每一个可执行算法单元,会在 stage 配置页面上使用唯一 name 进行标识,后面应用的时候通过这个 name 就可以调用这个算法单元;现网场景数据也是一样,配置的每个数据资源也会对应唯一 name,比如小游戏推荐池子对应一个 name A,精品游戏推荐池子对应的 name B。一个场景有了资源和需要执行算法单元之后,就可以配置一个推荐接口(taskgroup),如下图所示:
一个推荐接口(taskgroup)下面可以配置多个执行逻辑(task,可以理解成是一个接口下面会有多个实验)如下图所示,游戏中心首页直播推荐接口,配置了两个 task:
每个 task 对应着一个 json 表征的 DAG 图,它包括:执行流程是怎样(使用哪些算法,执行逻辑是串行还是并行),每个算法使用哪些数据(特征、池子等,给定前面配置的资源 name 即可)这个图在一开始设计的时候是拖拽的方式来添加和删除图节点,目前还是算法同学自己写 json 串。如下图是一个 task 配置:
所有这些线上配置信息会存储在现网 mysql 中,线上执行模块可以直接通过 name 访问对应的文件。完成上面配置之后,算法同学就可以在页面对单个 task 进行 debug,满足上线标准之后(排序是否正常、耗时是否满足线上标准等),就可以把 taskgroup name 给到业务后台同学,完成上线。
从上面看出,因为我们通过页面配置打通了从离线到线上的全流程,所以负责流程中每个环节的同学工作效率都有很大提升。
Ø 平台能力拓展
离线平台能力我们希望打造成部门底层通用的基础能力,不仅仅在推荐业务上使用,还能拓展到画像、数据分析、安全以及所有跟机器学习相关的业务上。事实上围绕着这个平台,我们也做了很多能力升级和拓展,比如最近在小游戏,基于平台能力,我们搭建了提供给小游戏开发者的自助精准用户挖掘能力和广告 rta 能力,帮助他们提升用户获取能力和降低用户获取成本。
从上图可以看出,以前开发者买量大多数只能针对包进行出价和投放;但现在在小游戏开发者管理端上,通过我们这套能力在 pv 维度上进行过滤和出价,对于一些用户过滤或者降低出价,对于其他可以用更高价获取,提升整体买量 roi。对于平台来说,以前为了帮助小游戏开发者更好的买量,我们需要投入专人挖掘精准号码包,但有了这套系统之后,我们的人力开始往能力建设迁移,后面希望我们建设好的一个能力,开发者可以通过这个平台第一时间使用到。下面简单提一下号码包平台设计思路,上面推荐管理端配置信息我们都是用户固定表格式来存储,但是号码包平台考虑到平台页面灵活性(未来配置信息变动大),我们方案是后台同学将配置生成 json 串,然后通过参数的方式传入给平台开发者提交挖包任务之后,直接通过 tesla api 调度挖包任务,完成挖包操作,整个流程都是开发者自助完成。这套系统已经在稳定运行了一个多月,有很多小游戏开发者再用这些能力,而投放 roi 上也有明显提升,符合预期。后面有更多实践经验我们在详细聊聊这一块的工作。
3、推荐引擎设计
业界大部分推荐团队一般包含一个算法组和引擎工程组,算法组负责场景离线建模和数据相关的工作;引擎工程组负责线上工程实现,包括算法模块开发、线上数据流处理以及系统调度相关工作。但是我们团队没有独立引擎组,为了保证未来推荐系统能够适应业务快速迭代,和后台同学商量我们推荐引擎设计上应该与其他推荐团队有所差异,首先在分工上后台同学负责整体框架的开发,同时把基础能力接口化,比如读取用户特征、读取模型文件等,然后单独出一个算法模块给算法同学实现模型线上预测打分逻辑,也就是利用这些基础接口,算法同学可以完成数据读取、数据处理到最终模型预测开发。这样分工一个明显的好处是算法同学很清楚线上链路,当业务场景出现 badcase 时,可以快速定位到问题,同时也减少了很多沟通成本。后续业务需要使用到某些算法的时候,算法同学可以利用这些基础能力完成线上开发,当然一些很难的算法实现,我们也会请求后台同学支持。在实际应用中,这样的分工让我们可以快速响应业务需求,特别是业务逻辑相关的,比如加权、过滤、混排等。
另外一方面,我们很难像其他推荐团队一样有专门同学单独负责推荐的单个环节,比如召回、粗排、精排、混排,所以在引擎架构设计需要淡化这些层级关系,所以我们定义了 action、node、stage 这些算子。其中 stage 表示可以调度的最小单元;node 是由 stage 组成的并行执行的最小单元;action 是由 node 组成的串行之行的最小单元。另外我们统一这些算子的输入输出,使得这些算子可以相互嵌套。通过这样的设计,算法同学可以根据业务的需求,自由组合这些基本单元,来达到召回、粗排、精排、混排的推荐架构。而算法使用上也比固定层级的设计要更加灵活,比如 FM 算法可以作为召回、粗排层或者精排、混排层,算法同学可以根据场景特点进行自由组合搭配。整个推荐引擎架构如下图所示:
当一个用户请求一个业务时,推荐引擎会根据实验系统命中情况,确定用户命中哪个策略,拿到这个策略对应的 task 名字,然后根据 task 名字可以在 mysql 中获取 task 对应的 DAG 执行图,controller 通过解析并执行这个 DAG 图,得到推荐结果,返回给业务后台。下图是后台同学在实现上函数逻辑调用关系,这里就不细讲,有兴趣的同学可以找我们这边后台同学了解实现细节。
线上部分算法同学涉及的工作主要是两块,一个是线上算法实现;另外一个是数据结构设计和对应的数据处理。首先看一下线上算法实现部分,从上面架构也可以看出,线上最小执行单元是 stage,它本质上就是一个 svrkit RPC 接口,其实也就是一个算法或者策略的实现,比如我们现在现网有 LR、FM、xgb、tagRecall、tf、加权混排、根据概率分布混排等 stage。一个 stage 内部逻辑如下图所示:
其中 stageMeta 是算法同学在统一推荐管理端在配置 task 执行 DAG 图的时候需要提供的,表示这个 stage 执行过程中使用哪些数据,执行参数是怎样的。而物理维度上的数据是通过架构部的文件分发系统,从 hdfs 或 ceph 拉取并分发到现网机器磁盘,然后本地资源管理模块会定期 check 资源版本,有新版更新会解析并加载到内存中,供 stage 使用。为了满足 stage 之间可以相互组合,我们统一了 stage 的输入和输出,输入是一个 repeated,它可以是业务请求 stage 时带入的 data,也可以是上一个 stage 或者上层并行执行的多个 stage 的结果。
这里提到 data 结构可以理解为就是候选列表以及列表内每个 item 所带的参数,比如上层打分、来源、权重等。而当前 stage 输出也是一个 data,可以作为结果反馈给后台,也可以作为下一层 stage 的输入。对于一个 stage 内部包含两个部分,一个模型加载和预测部分;另外一个是根据 stagemeta 信息和输入的候选打分列表生成模型打分数据格式,然后将这个数据喂给模型打分,生成结果数据。
算法同学涉及到的另外一个部分工作是数据结构设计和数据处理,下图列举了我们在线上使用的核心数据结构,包括特征结构、模型结构、特征交叉结构。为了保证线上线下一致性,我们都采用 protobuf 来表征。对于特征我们采用了双层 map 结构来存储,第一层是 featureDataSet 单个 item/单个用户所拥有的特征,map 的 key 是特征名字,value 是内层 map featureDataPairs,它是该特征的取值。比如游戏偏好这个特征,内层取值可能是 rpg、moba 或许休闲等。单维度特征相关信息用 featureData 存储。
对于特征交叉结构,我们使用二叉树来存储交叉信息,叶子结点表示交叉子特征,内节点表示交叉算子,通过这样的设计,我们就可以进行二阶交叉、三阶交叉…..,n 阶交叉。离线模型使用的交叉特征信息是与模型绑定在一个 pb 结构里面进行出库的,保证模型和交叉文件原子性。类似的还有特征名字和 index 之间的映射关系,也需要与模型 pb 进行原子更新,当然这是很细节的实现部分了。对于图中的模型结构一部分是单个算法的定义,把训练好的模型信息封装到 pb 里面。另外需要把刚才提到涉及到原子更新的信息在模型持久化的时候,部署在一个 pb 文件中,这样做的目的是保证线上线下数据一致,这里也就是前面提到为什么说离线没有直接用 tesla 或者其他平台提供训练能力,而是自己实现里面的训练逻辑的原因。
4、推荐系统实时化方案
19 年初的时候,部门后台同学搭建了一套基于 Oceanus+Druid 实时监控系统,帮助业务可以实时查看和监控业务指标和服务性能指标。同时把还协议接入、数据清洗、协议转发 kafka 等各个环节进行了封装。推荐系统实时化也是在延展,一方面监控推荐场景的实验实时效果;另外一方面在这基础上,增加实时特征和模型增量更新的能力,整体流程如下图所示:
在实时流配置模块,可以根据协议 ID 对协议数据进行清洗和筛选出场景对应的数据(Oceanus 每个核只能处理 1W/s 行,数据太多容易阻塞,所以清洗和筛选需要前置)然后新建一个 kafka 的 topic 并关联协议数据。后面的算法大部分的开发工作都是在 oceanus 上完成的。对于实时特征,我们定义了实时特征的通用结构,在 Oceanus 上完成特征逻辑的开发后台,item 特征会落到 hdfs 上,通过文件分发系统分发到现网机器上;用户特征则是再写入到 kafka,经过后台一个 svrkit 服务将特征写入现网 kv。增量学习的流程是在 Oceanus 上完成样本逻辑开发之后,再将样本数据写入到 kafka,后台有一个 svrkit 服务读取样本数据,并调用现网预测部分的数据处理模块,根据样本信息生成 libsvn 格式数据写入到 kafka,然后再回到 oceanus 上完成模型训练、评估和部署。
5、遇到的问题与挑战
前面已经把搭建推荐系统的整体流程介绍完成,下面介绍我们在实际业务应用过程中遇到的几个问题和挑战以及我们的应对方案。首先是数据管理,从离线建模到模型部署上线的各个环节都涉及到离线与线上的数据交互,一开始我们是每个场景算法开发同学各自维护各个场景数据上传脚本,并通过 crontab 定时导入到线上。随着接入推荐系统的场景越来越多,这种方式很快就遇到瓶颈了:维护成本高、数据分散、数据质量很难保证、线上出现 badcase 定位周期长等等。为了解决这个问题,我们从两个方面进行着手,首先与线上交互的数据统一放到一起管理,使用页面配置代替脚步;另外一块是把特征相关的数据上线使用 dataDeploy 模块进行统一出库和上线,并提供数据查询工具,可以快速查到现网数据,让算法法同学确认数据是否正常上线。
第二个挑战是我们业务场景很多,负责场景建模的就固定几个同学,随着接入推荐系统场景越来越多,单个同学的负担也越来越重,特别是花在 badcase 定位和异常排查时间非常多;为了缓解这个问题,我们梳理了推荐整体流程,把重点环节监控起来,同时结合实时监控,帮助我们提前感知到线上异常。当发现异常时,结合 ilog 系统快速定位到问题发生的场景和原因。另外一块我们搭建了推荐系统的白板系统,如下图所示,通过给定的 taskgroup 和对应 task,把线上打分流程可视化出来,同时展示出打分过程中使用的特征细节。
运维成本高还有另外一个非常大的挑战是我们活动资源推送带来瞬间流量峰值。这个瞬间流量峰值,直接把推荐系统搞挂了,自动扩容还没启动,机器资源就跑满了,导致大量的逻辑失败。印象最深的是 19 年这个系统第一次经受春节考验,大量红点资源推送,导致大量用户涌入游戏中心,把推荐系统撑挂了,好在后台有备选 list,后台同学手动把部分流量切到默认 list,才没有影响到现网用户。这里也非常感谢团队,没有责备我们,而是在春节期间带领我们寻找解决方案。当前我们的做法根据流量自动分级处理,第一级是正常推荐;第二级是部署另外一个与推荐系统并行的模块,如果推荐系统模块挂了,自动切到这个模块,执行耗资源少的兜底逻辑;第三级是所有模块都失败了,切到后台 list。下图所示的 ID=453 的 task 就是这个接口配置的兜底逻辑。另外一方面对耗时和耗资源代码进行优化。经过这些优化之后,系统再也没有出现大面积失败的情况了。
第三个是所有推荐系统都会面临的耗时问题。开始只接入 IEG 精品游戏推荐场景,因为 item 个数少,没有耗时问题。但是随着小游戏分发和内容分发场景的上线,耗时随着 item 个数增加而增加。这里我们的后台同学把线上打分整个流程做了耗时评估,发现数据处理占了总体耗时的 70%,进一步细化分析则发现核心问题是在涉及数据结构的时候埋下了一个隐患,pb 里面 map 结构使用 string key 性能非常差,后面改成 int64;同时对特征拼接流程进行优化,优先拼接好用户特征,再拼接上 item 和交叉特征,而不是单个 uin-item pair 对进行拼接,经过这些优化,耗时明显改善。另外对应多 item 和多特征的场景,通过增加粗排层,在性能和准确度上进行权衡。
上面把我们推荐系统从调研、设计、搭建再到运维整个过程介绍完了,希望能给大家带来一些启发。
最后大家有问题或者好的想法欢迎一起来交流。
更多干货尽在腾讯技术,欢迎关注官方公众号:腾讯技术工程,交流群已建立,交流讨论可加QQ 群:160315980(备注腾讯技术) 。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK