

手把手教你从数据预处理开始体验图数据库
source link: https://my.oschina.net/u/4169309/blog/5027923
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文首发于 Nebula 公众号:手把手教你从数据预处理开始体验图数据库,由社区用户 Jiayi98 供稿,分享了她离线部署 Nebula Graph、预处理 LDBC 数据集的经验,是个对新手极度友好的手把手教你学 Nebula 分享。
这不是一个标准的压力测试,而是通过一个小规模的测试帮助我熟悉 Nebula 的部署,数据导入工具,查询语言,Java API,数据迁移,以及集群性能的一个简单了解。
所有的准备都需要找个有网的环境
- 安装 Docker:
$ rpm -ivh <rpm包>
$ systemctl start docker --启动
$ systemctl status docker --查看状态
- 安装 docker-compose
$ mv docker-compose /usr/local/bin/ --把docker-compose文件移动到/usr/local/bin
$ chmod a+x /usr/local/bin/docker-compose --改权限
$ docker-compose -version
$ docker load <镜像tar包>
$ docker image ls
- 在机器 manager machine 上执行以下命令初始化 Docker Swarm 集群:
$ sudo docker swarm init --advertise-addr <manager machine ip>
- 根据提示在另一台服务器上以
worker的身份join swarm
$ docker node ls
- 添加
worker node如果出现以下报错:
Error response from daemon: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.9.129:2377: connect: no route to host"
一般是防火墙未关闭导致的(用以下方式关闭防火墙)。
$ systemctl status firewalld.service
$ systemctl disable firewalld.service
- 在 manager 节点上改写
docker-stack.yml,并创建nebula.env
-- nebula.env
TZ=UTC
USER=root
- Yaml file 里的 hostname 多台机器不可同名,启动时的错误多半是因为配置文件写得有问题,v1 升级 v2 也只需要把配置文件里的镜像换一下就可以了。
- 在 manager 节点上动 nebula 集群
$ docker stack deploy <stack name> -c docker-stack.yml
这里附带一些我 Debug / 检查方法:
$ docker service ls --查看服务状态
$ docker service ps <NAME/ID> --查看某一个具体的状态
$ docker stack ps --no-trunc <stack name> --查看 stack 里所有的进程
- 安装 Studio
代码文件夹里是 v1,有一个 v2 的文件夹里是 v2
$ cd nebula-web-docker
$ cd nebula-web-docker/v2
$ docker-compose up -d -- 构建并启动 Studio 服务;
其中,-d 表示在后台运行服务容器
启动成功后,在浏览器地址栏输入:http://ip address:7001
我用的 LDBC。
LDBC 数据预处理
这里需要说明一下,要注意你用的 nebula 版本是否支持 “|” 作为分隔符。
ldbc 的所有 vertex 和 edge 的 ID / index 都有问题,需要处理一下使得所有 vertex 的 ID 变为 unique key。
我的做法是每个 vertex 我都给一个前缀,比如 person,原始 ID 为 933,变为 p933。(为了试用一下我自己搭的 CDH 我用 Spark 做的数据预处理,处理过的数据放在 HDFS 以便后面用 nebula-exchange 导入)

备注:Nebula 不推荐使用 HDD,但我也没有 SSD, 最后测试结果证明 HDD 真的很弱。
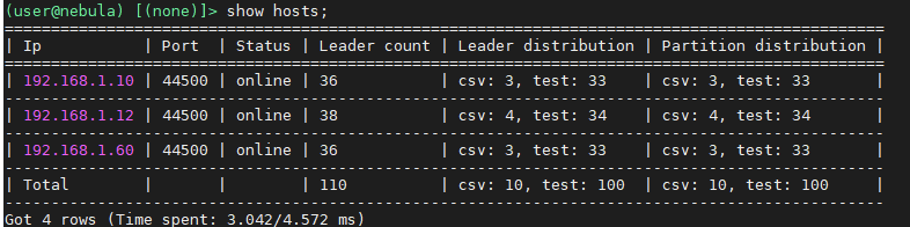
3 节点,服务分布如下
- 192.168.1.10 meta,storage
- 192.168.1.12 graph,meta,storage
- 192.168.1.60 graph,meta,storage
2 图空间:
- csv:10 个 partition
- 原始数据约 42 M
- 7 千多个点,40 万条边
- test:100 个 partition
- 原始数据约 73 G
- 1.1 亿多个点,28.2 亿多条边(Edge: 1,101,535,334;Vertex: 282,612,309)
导入 Nebula 之后,占用储存空间共约 76 G,其中 wal 文件占 2.2 G 左右。
没有做导入的测试,一部分用了 Nebula-Importer 导入,一部分用了 Exchange 导入:
测试方法:
- 选取 1000 个 vertex,进行 1000 次查询的平均值

- 三度超时是将
timeout参数调高至 120 秒后的结果,后来在终端执行了一次三度发现要三百多秒。
最后,希望这份文档对和我一样的小白们有帮助,也感谢一直以来社区和官方的答疑解惑。
Nebula 真的让用户感到真的非常 supportive,在学习使用 Nebula 的过程中我也收获了很多~
进一步交流
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebulae 名片,Nebula 小助手会拉你进群~~
要不要看看【美团的图数据库系统】、【微众银行的数据治理方案】以及其他大厂的风控、知识图谱实践?Follow Nebula 公众号:NebulaGraphCommunity 回复「PPT」即可习得大厂实践技能 ^^
{kind=link}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK