

每个 Apache Kafka 开发者都应该知道的5件事
source link: https://blog.csdn.net/wypblog/article/details/115843229
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Apache Kafka 是一个开源流处理平台,如今有超过30%的财富500强企业使用该平台。Kafka 有很多特性使其成为事件流平台(event streaming platform)的事实上的标准。在这篇博文中,我将介绍每个 Kafka 开发者都应该知道的五件事,这样在使用 Kafka 就可以避免很多问题。
Tip #1 理解消息传递和持久性保证
对于数据持久性(data durability),我们可以通过 KafkaProducer 类来设置 acks。acks 指的是 Producer 的消息发送确认机制,这个参数支持以下三种选项:
•acks = 0:意味着如果生产者能够通过网络把消息发送出去,那么就认为消息已成功写入 Kafka ,是一种 fire and forget 模式。•acks = 1:意味若 Leader 在收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时会返回确认或错误响应。•acks = all(这个和 request.required.acks = -1 含义一样):意味着 Leader 在返回确认或错误响应之前,会等待所有同步副本都收到悄息。
正如您所看到的,这里需要进行权衡取舍(trade-off)——因为不同的应用程序有不同的需求。我们可以选择较高的吞吐量,但有可能导致数据丢失,或者可以选择以较低吞吐量为代价提供非常高的数据持久性保证。
现在,我们花点时间讨论一下 acks=all 场景。如果你在一个由三个 Kafka broker 组成的集群中发送一条记录,那么这意味着在理想的情况下,Kafka 包含你数据的三个副本:一份存在 lead broker 上,另外两份存在 followers 上。当每个副本的日志都具有相同的记录偏移量时,就认为它们是同步的。换句话说,这些同步副本对于给定的主题分区具有相同的内容。看看下面的插图,清楚地描绘出发生了什么:
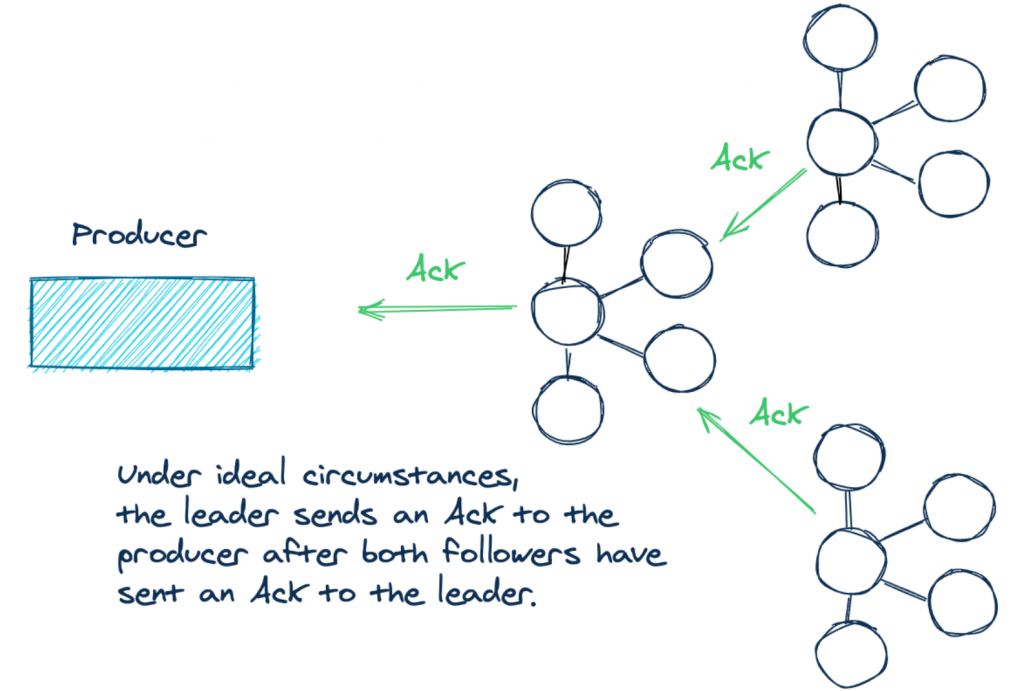
但是使用 acks=all 配置有一些微妙之处,它没有指定需要同步多少个副本。主 broker 总是与自己保持同步。但是,由于网络分区、记录负载等原因,你可能会遇到以下两个 broker 无法跟上的情况。因此,当生产者成功发送时,实际的确认数量可能只来自一个 broker !如果两个 follower 不同步,生产者仍然会收到所需数量的 ack,但是在这种情况下只是 leader 同步了数据。
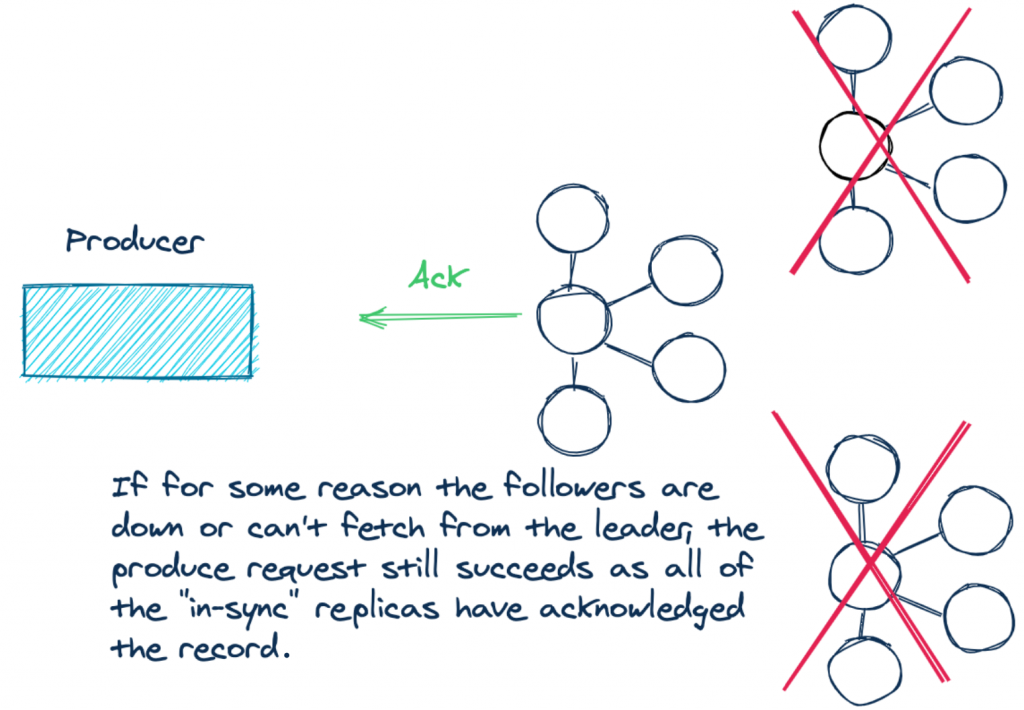
通过设置 acks=all,您正在为数据的持久性付出代价。因此,如果副本没有跟上进度,则有理由要在副本被追上之前为新记录引发异常。
简而言之,我们需要的是使用 acks=all 设置时的保证,成功的发送至少涉及大多数可用的同步 broker(in-sync brokers)。
恰好有一种这样的配置:min.insync.replicas。min.insync.replicas配置强制执行复制操作之前必须同步的副本数。请注意,min.insync.replicas配置是在代理或主题级别设置的,而不是生产者配置。min.insync.replicas的默认值为1。因此,为避免上述情况,在三经纪商集群中,您希望将该值增加到两个。
这里恰好有一个这样的配置:min.insync.replicas。min.insync.replicas 配置强制执行复制操作之前必须同步的副本数。请注意,min.insync.replicas 配置是在 broker 或主题级别设置的,而不是 producer 配置的。min.insync.replicas 的默认值是1。因此,为了避免上述场景,在三个 broker 的集群中,您需要将值增加到2。
让我们回顾一下之前的示例,看看其中的区别:
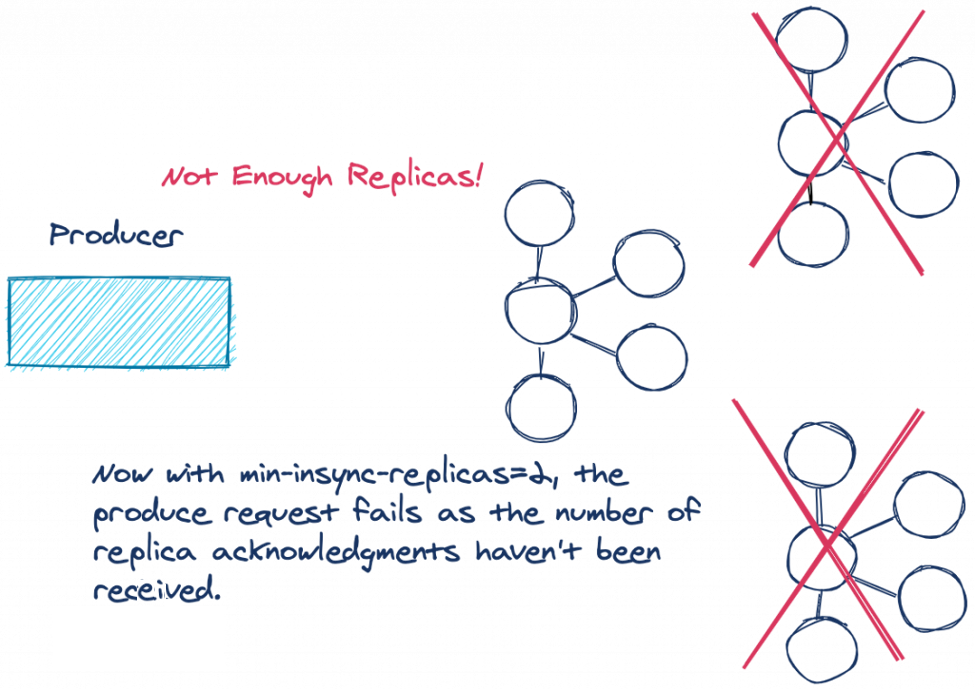
如果同步的副本数量低于配置的数量,则主 broker 不会尝试将记录追加到其日志中。leader broker 将抛出 NotEnoughReplicasException 或 NotEnoughReplicasAfterAppendException 异常,迫使 producer 重试写操作。副本与 leader 不同步被认为是一个可重试的错误,因此生产者将继续重试直到超时。
因此,通过 min.insync.replicas 和生产者 acks 一起使用,可以提高数据的持久性。
Tip #2: 了解 producer API 中新加的 sticky partitioner
Kafka使用分区来增加吞吐量,并将消息分散到集群中所有的 brokers 。Kafka records 采用键/值格式,键可以为空(null)。Kafka 生产者不会立即发送记录,而是将它们放入特定分区的批次中,以便稍后发送。批处理是提高网络利用率的有效手段。有三种方法确定记录应该写入哪个分区。
可以通过重载的 ProducerRecord 构造函数在 ProducerRecord 对象中显式地提供分区。在这种情况下,生产者总是使用这个分区。
如果没有提供任何分区,并且 ProducerRecord 有一个键,则生产者将该键的哈希值除以分区的数量。计算得到的结果数就是生产者将要使用的分区。
如果 ProducerRecord 中没有键,也没有分区,那么以前的 Kafka 使用轮询方法来跨分区分配消息。生产者将批处理中的第一个记录分配给分区0,第二个记录分配给分区1,依此类推,直到分区结束。然后,生产者将从分区0开始,并对所有剩余的记录重复整个过程。
下图描述了此过程:
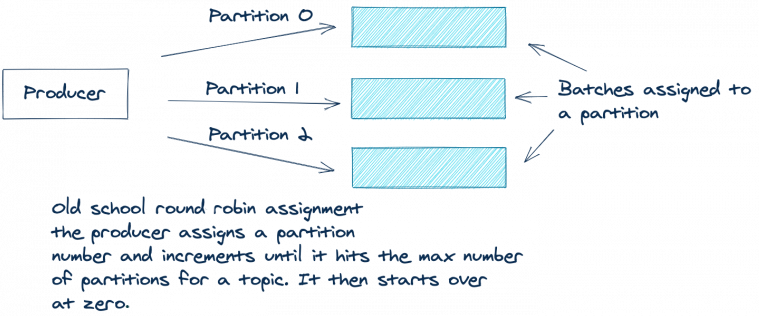
轮询方法适用于跨分区均匀分布记录。但也有一个缺点。由于这种“公平”的轮询方法,您最终可能会发送多个稀疏填充的批处理。发送更少的批并在每个批中发送更多的记录会更有效率。较少的批次意味着更少的生产请求排队,因此 brokers 负载更少。
我们来看一个简化的示例,在该示例中,我们有一个包含三个分区的主题。为了简单起见,假设我们的应用程序生成了9条没有 key 的记录,而这些记录都是同时到达的:
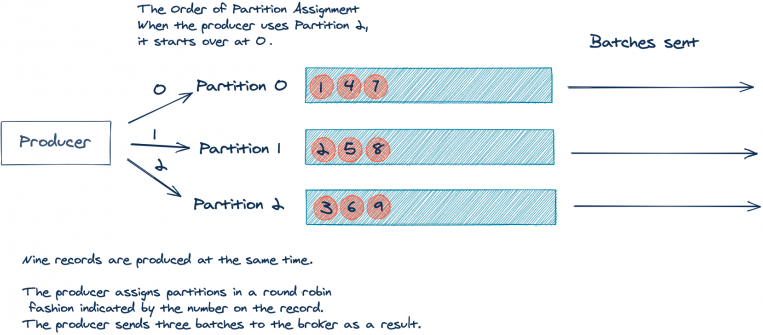
正如我们在上面所看到的,这9条记录将产生3个批次,每个批次里面有三条消息。但是,如果我们能将这9条记录作为一个批次发送就更好了。如前所述,更少的批处理会导致 broker 上更少的网络流量和负载。
Apache Kafka 2.4.0 增加了粘性分区(sticky partitioner)的方法,使得上面的假设成为可能。与对每个记录使用轮询方法不同,粘性分区将记录分配给同一个分区,直到批处理被发送为止。然后,在发送一个批处理之后,粘性分区将分区增加以用于下一个批处理。让我们看下上面的例子使用粘性分区之后的处理方式:
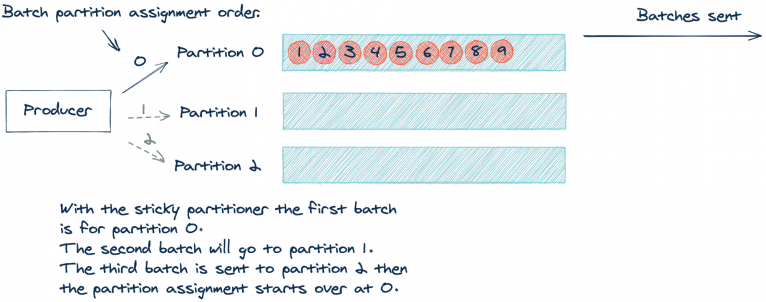
通过使用相同的分区直到批处理满或完成,我们将发送更少的请求,这减少了请求队列上的负载,也减少了系统的延迟。值得注意的是,粘性分区仍然会导致记录的均匀分布。随着时间的推移,均匀分布会发生,因为分区程序会向每个分区发送批处理。我们可以将其视为“每批”轮循或“最终均衡”的方法。
Tip #3: 通过 cooperative rebalancing 来避免“stop-the-world”的消费者组再平衡
Kafka 是一个分布式系统,分布式系统需要做的关键事情之一是处理故障和中断。不仅仅是预测故障,而是完全接受它们。Kafka 如何处理这种预期中断的一个很好的例子是消费者组协议(consumer group protocol),它为一个逻辑应用管理一个消费者的多个实例。如果一个消费者的实例停止了,不管是出于设计还是其他原因,Kafka 将重新平衡并确保另一个消费者实例接管工作。
从 Kafka 2.4版开始,Kafka 引入了新的再平衡协议:合作再平衡(cooperative rebalancing)。但是,在我们深入研究新协议之前,让我们先详细了解消费者组(consumer group)的基础知识。
假设我们有一个分布式应用程序,其中有多个消费者订阅了同一个主题。配置有相同 group.id 的任意一个消费者构成一个逻辑消费者,在 Kafka 中称为消费者组(consumer group)。组中的每个消费者负责从订阅主题的一个或多个分区进行消费,这些分区由消费者组 leader 进行分配。下图说明了这个场景:
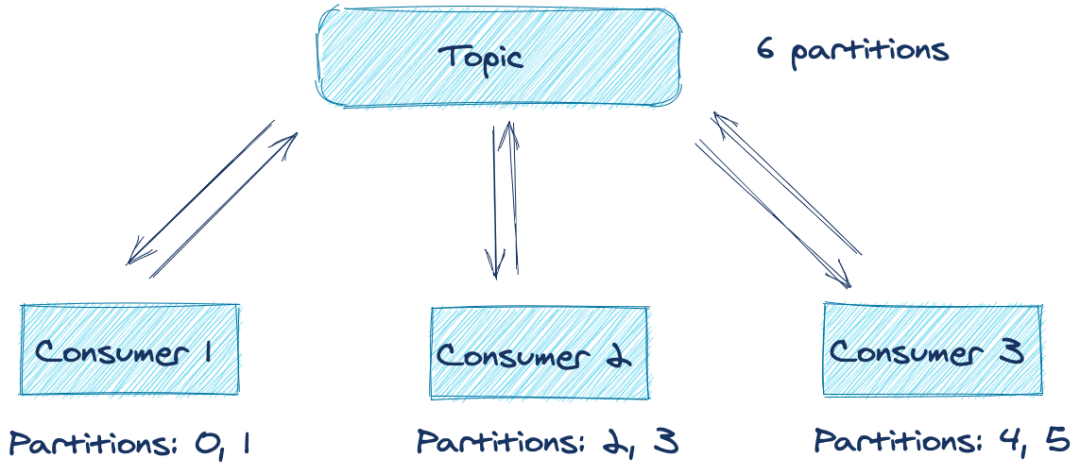
从上图中可以看到,在最佳条件下,三个消费者分别处理来自两个分区的记录。但是,如果其中一个应用程序出现错误或不能再连接到网络,会发生什么情况呢?在应用程序恢复之前对这些主题分区的处理是否会停止?幸运的是,由于消费者再平衡协议,答案是否定的。下面是当一个消费者出现问题,消费者再平衡之后的结果:

正如我们看到的,消费者2由于某些原因出现问题。组协调器(group coordinator)将其从消费者组中删除,并触发所谓的 rebalance。rebalance 是一种机制,它试图在一个消费者组的所有可用成员之间均匀地分配(平衡)工作负载。在这种情况下,由于消费者2离开了组,rebalance 将其以前拥有的分区分配给组的其他活动成员。因此,某个消费者应用程序出现问题不会导致丢失对这些主题分区的处理。
但是,默认的再平衡方法存在一个缺点。每个消费者都需要放弃之前已经分配的主题分区,并且直到重新分配主题分区之后才进行数据处理,这个再平衡有时被称为“stop-the-world”再平衡。为了使问题更加复杂,根据所使用的 ConsumerPartitionAssignor 实例,只需重新分配消费者在重新分配之前拥有的相同主题分区,其最终结果是不需要暂停这些分区上的工作。
重新平衡协议的这种实现方式称为“eager rebalancing”,因为它优先考虑了确保同一组中的没有消费者声明对同一主题分区的所有权的重要性。同一组中的两个消费者拥有同一个主题分区将导致未定义的行为。
尽管防止任何两个消费者声称对同一主题分区的所有权是至关重要的,但事实证明,有一种更好的方法可以在不减少处理时间的情况下提供安全性:增量协作再平衡(incremental cooperative rebalancing)。它首先在 Apache Kafka 2.3 中的 Kafka Connect 中引入,现在已经在消费者组协议中实现了。使用协作方法,消费者不会在重新平衡开始时自动放弃所有主题分区的所有权。相反,所有成员对他们当前的任务进行编码,并将信息转发给组长。然后组长决定哪些分区需要更改所有权,而不是从头生成一个全新的分配。
现在第二种再平衡技术已经实现了,但是这次只涉及需要更改所有权的主题分区。它可以回收不再分配的主题分区或添加新的主题分区。那些不需要移动的主题分区可以继续处理数据。
要启用这个新的再平衡协议,我们需要将 partition.assignment.strategy 设置为 CooperativeStickyAssignor。另外,这个修改是在客户端进行的。要利用新的再平衡协议,只需更新客户端版本。如果你是 Kafka Streams 的用户,还有更好的消息。默认情况下,Kafka Streams 启用的就是这个再平衡协议,因此无需执行其他操作。
Tip #4: 掌握命令行工具
Apache Kafka二进制安装包括位于bin目录中的几个工具。尽管您会在该目录中找到一些工具,但我想向您展示我认为会对您的日常工作产生最大影响的四个工具。我指的是控制台用户,控制台生产者,转储日志和删除记录。
Apache Kafka 二进制安装包括几个位于 bin 目录下的工具。虽然我们可以在该目录中找到几个工具,但我想向您展示我认为对您的日常工作影响最大的四种工具。我这里指的是 console-consumer、console-producer、dump-log 以及 delete-records 四个工具。
Kafka console producer
console-producer 允许我们直接从命令行生成主题的记录。当我们还没有为主题生成数据时,从命令行生成数据是快速测试新的消费者应用程序的一种好方法。要启动 console producer,可以直接运行以下命令:
kafka-console-producer --topic --broker-list <broker-host:port>
执行这个命令后,将出现一个空提示,等待我们的输入,只需键入一些字符,然后按 Enter 即可生成一条消息。
以这种方式发送消息不会发送任何 Key,仅会发送消息的值。幸运的是,kafka-console-producer 为我们提供了一种发送 Key 的方法。我们只需要使用以下命令就可以:
key.separator 属性可以设置任意的字符。现在,我们可以从命令行发送完整的键/值对!如果我们使用 Confluent Schema Registry,那么还可以使用这个工具生成 Avro、Protobuf 和 JSON 模式的消息。
Kafka console consumer
console consumer 可让我们直接从命令行消费 Kafka 主题中的记录。对于原型设计或调试来说是非常宝贵的工具。假设我们构建了一个新的微服务。要快速确认生产者应用程序正在发送消息,我们可以简单地运行以下命令:
kafka-console-consumer --topic --bootstrap-server <broker-host:port>
运行此命令后,我们将开始看到消息在屏幕上滚动(只要当前正在为该主题生成数据)。如果要从头开始查看所有消息,可以在命令中添加 --from-beginning 标志,然后我们将可以查看到这个主题的所有消息。
如果我们使用了 Schema Registry,则有一些特殊的 console-consumer(kafka-protobuf-console-consumer、kafka-json-schema-console-consumer) 可用于消费 Avro,Protobuf 和 JSON Schema 编码的记录。Schema Registry console-consumer 用于处理 Avro,Protobuf 或 JSON 格式的记录,而普通的 console-consumer 则用于处理原始 Java 类型的记录:字符串,长整数,双精度,整数等。普通 console-consumer 的值是 String类型。
如果键或值不是字符串,则需要通过命令行标记(--key-deserializer 和 --value-deserializer)提供反序列化器,这些反序列化器必须是带包名的类。
你可能已经注意到,默认情况下,console-consumer 仅将消息的值部分打印到屏幕上。如果还想查看对应消息的 Key,则可以通过包含必要的标志来实现:
和 console-producer 一样,key.separator 参数的值也是任意的字符。
Dump log
有时,当我们使用 Kafka 时,可能会发现自己需要手动检查主题的底层日志。无论你只是好奇 Kafka 内部还是你需要调试一个问题并验证内容,kafka-dump-log 命令都是你的朋友。下面介绍如何使用这个命令,该示例的主题名为 example:
•--print-data-log 标记指定打印 log 里面的数据;•--files 标记是必选项,可以是逗号分隔的文件列表。
如果想查看 kafka-dump-log 命令的所有支持的选项,可以使用 --help。运行上面的命令可以得到以下的输出:
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1599775774460 size: 81 magic: 2 compresscodec: NONE crc: 3162584294 isvalid: truebaseOffset: 1 lastOffset: 9 count: 9 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 81 CreateTime: 1599775774468 size: 252 magic: 2 compresscodec: NONE crc: 2796351311 isvalid: truedump-log 命令提供了大量信息。您可以清楚地看到每个记录的键、payload (值)、偏移量和时间戳。需要注意的是,上面输出的数据来自仅包含10条消息的演示主题,因此对于真实主题,将有更多的数据。另外,在本例中,主题的键和值都是字符串。如果要使用非字符串的键或值类型,可以在运行 kafka-dump-log 命令的时候加上 --key-decoder-class 或 --value-decoder-class 标记即可。
Delete records
Kafka 将主题记录存储在磁盘上,即使消费者已经读取了这些数据,它也会保留这些数据。然而,记录不是存储在一个大文件中,而是按分区分为多个分段( segments),其中偏移量的顺序在同一主题分区的各个分段之间是连续的。由于服务器的存储不可能无限大,因此 Kafka 提供了一些设置,用于根据时间和大小来控制保留多少数据:
控制数据保留的时间配置为 log.retention.hours ,默认为168小时(一周);log.retention.bytes 参数控制 segments 在删除之前可以增加到多少。但是,log.retention.bytes 的默认设置是-1,这使日志段的大小不受限制。如果您不小心并且没有配置保留大小以及保留时间,则可能会出现磁盘空间用完的情况。请记住,您永远不要进入文件系统并手动删除文件。相反,我们希望有一种受控且受支持的方式从主题中删除记录,以释放空间。幸运的是,Kafka 附带了一个工具,可以根据需要删除数据。
kafka-delete-records 有两个主要的参数:
•--bootstrap-server:需要连接的 brokers 地址;•--offset-json-file:包含删除配置的 Json 文件。下面是 JSON 文件的示例:
正如你所看到的,JSON 文件的格式非常简单,它其实是一个 JSON 对象数组。每个 JSON 对象有以下三个属性:
•Topic:需要删除数据的主题;•Partition:需要删除的分区;•Offset:需要从什么偏移量删除数据,将会把小于这个偏移量的数据删除。
上面示例中,我删除 example 主题的分区 0 的数据。example 主题只包含10条记录,所以您可以很容易地计算启动删除过程的起始偏移量。但在实践中,你很可能不知道应该使用哪种偏移量。还要记住 offset != message number,因此不能直接从“message 42”中删除。如果您将这个值设置为 -1,这意味着您将删除主题中所有数据。可以使用下面命令来删除主题的数据:
运行完这个命令之后,你可以在控制台看到以下的输出:
命令的结果表明,Kafka 从主题分区 example-0 删除了所有记录。low_watermark=10表示可供消费者使用的最低偏移量。因为示例主题中只有10条记录,所以我们知道偏移量的范围是0到9,并且没有消费者可以再次读取这些记录。
Tip #5: 使用消息头的强大功能
Apache Kafka 0.11引入了记录头的概念。记录标题使您能够添加一些有关Kafka记录的元数据,而无需在记录本身的键/值对中添加任何额外的信息。考虑是否要在消息中嵌入一些信息,例如数据所源自的系统的标识符。也许您希望这样做是为了沿袭和审核目的,以便于向下游路由数据。Apache Kafka 0.11 引入了消息头的概念。消息头让你能够添加一些关于 Kafka 记录的元数据,而不需要向记录本身的键/值对添加任何额外的信息。考虑是否要在消息中嵌入一些信息,例如数据所源自系统的标识符,这样我们可以做一些审计相关的统计。
Adding headers to Kafka records
下面是使用 Java 代码给 ProducerRecord 添加消息头:
Retrieving headers
可以使用下面命令在消费端来消费头信息
当然,我们也可以使用 kafkacat 来从命令行上查看消息的头信息:
本文翻译自:Top 5 Things Every Apache Kafka Developer Should Know - https://www.confluent.io/blog/5-things-every-kafka-developer-should-know/#kafka-console-consumer
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK