

如果你完全理解如下内容, 请联系我:[email protected], 讨论更深层次合作 。
source link: https://blog.csdn.net/china_video_expert/article/details/70163297
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
如果你完全理解如下内容, 请联系我:[email protected], 讨论更深层次合作 。
1. 大内高手—内存模型
单线程模型
多线程模型
2. 大内高手—栈/堆
backtrace的实现
alloca的实现
可变参数的实现。
malloc/free系列函数简介
new/delete系列操作符简介
3. 大内高手—全局内存
.bss说明
.data说明
.rodata说明
violatile关键字说明
static关键字说明
const关键字说明
4. 大内高手—内存分配算法
标准C(glibc)分配算法
STL(STLPort)分配算法
OS内部分配算法(伙伴/SLAB)
5. 大内高手—惯用手法
6. 大内高手—共享内存与线程局部存储
7. 大内高手—自动内存回收机制
8. 大内高手—常见内存错误
9. 大内高手—常用调试工具
++++++++++++++++++++++++++++++++++++++++++++++++++++++++
大内高手—内存模型
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
了解linux的内存模型,或许不能让你大幅度提高编程能力,但是作为一个基本知识点应该熟悉。坐火车外出旅行时,即时你对沿途的地方一无所知,仍然可以到达目标地。但是你对整个路途都很比较清楚的话,每到一个站都知道自己在哪里,知道当地的风土人情,对比一下所见所想,旅程可能更有趣一些。
类似的,了解linux的内存模型,你知道每块内存,每个变量,在系统中处于什么样的位置。这同样会让你心情愉快,知道这些,有时还会让你的生活轻更松些。看看变量的地址,你可以大致断定这是否是一个有效的地址。一个变量被破坏了,你可以大致推断谁是犯罪嫌疑人。
Linux的内存模型,一般为:
>=0xc000 0000
内核虚拟存储器
用户代码不可见区域
<0xc000 0000
Stack(用户栈)
ESP指向栈顶
>=0x4000 0000
文件映射区
<0x4000 0000
Heap(运行时堆)
通过brk/sbrk系统调用扩大堆,向上增长。
.data、.bss(读写段)
从可执行文件中加载
>=0x0804 8000
.init、.text、.rodata(只读段)
从可执行文件中加载
<0x0804 8000
很多书上都有类似的描述,本图取自于《深入理解计算机系统》p603,略做修改。本图比较清析,很容易理解,但仍然有两点不足。下面补充说明一下:
1. 第一点是关于运行时堆的。
为说明这个问题,我们先运行一个测试程序,并观察其结果:
#include<stdio.h>
intmain(intargc,char*argv[])
int first= 0;
int*p0= malloc(1024);
int*p1= malloc(1024 * 1024);
int*p2= malloc(512 * 1024 * 1024 );
int*p3= malloc(1024 * 1024 * 1024 );
printf("main=%p print=%p\n",main,printf);
printf("first=%p\n", &first);
printf("p0=%p p1=%p p2=%p p3=%p\n",p0,p1,p2,p3);
getchar();
return0;
运行后,输出结果为:
main=0x8048404 print=0x8048324
first=0xbfcd1264
p0=0x9253008 p1=0xb7ec0008 p2=0x97ebf008 p3=0x57ebe008
l main和print两个函数是代码段(.text)的,其地址符合表一的描述。
l first是第一个临时变量,由于在first之前还有一些环境变量,它的值并非0xbfffffff,而是0xbfcd1264,这是正常的。
l p0是在堆中分配的,其地址小于0x4000 0000,这也是正常的。
l 但p1和p2也是在堆中分配的,而其地址竟大于0x4000 0000,与表一描述不符。
原因在于:运行时堆的位置与内存管理算法相关,也就是与malloc的实现相关。关于内存管理算法的问题,我们在后继文章中有详细描述,这里只作简要说明。在glibc实现的内存管理算法中,Malloc小块内存是在小于0x4000 0000的内存中分配的,通过brk/sbrk不断向上扩展,而分配大块内存,malloc直接通过系统调用mmap实现,分配得到的地址在文件映射区,所以其地址大于0x4000 0000。
从maps文件中可以清楚的看到一点:
00514000-00515000 r-xp 00514000 00:00 0
00624000-0063e000 r-xp 00000000 03:01 718192 /lib/ld-2.3.5.so
0063e000-0063f000 r-xp 00019000 03:01 718192 /lib/ld-2.3.5.so
0063f000-00640000 rwxp 0001a000 03:01 718192 /lib/ld-2.3.5.so
00642000-00766000 r-xp 00000000 03:01 718193 /lib/libc-2.3.5.so
00766000-00768000 r-xp 00124000 03:01 718193 /lib/libc-2.3.5.so
00768000-0076a000 rwxp 00126000 03:01 718193 /lib/libc-2.3.5.so
0076a000-0076c000 rwxp 0076a000 00:00 0
08048000-08049000 r-xp 00000000 03:01 1307138 /root/test/mem/t.exe
08049000-0804a000 rw-p 00000000 03:01 1307138 /root/test/mem/t.exe
09f5d000-09f7e000 rw-p 09f5d000 00:00 0 [heap]
57e2f000-b7f35000 rw-p 57e2f000 00:00 0
b7f44000-b7f45000 rw-p b7f44000 00:00 0
bfb2f000-bfb45000 rw-p bfb2f000 00:00 0 [stack]
2. 第二是关于多线程的。
现在的应用程序,多线程的居多。表一所描述的模型无法适用于多线程环境。按表一所述,程序最多拥有上G的栈空间,事实上,在多线程情况下,能用的栈空间是非常有限的。为了说明这个问题,我们再看另外一个测试:
#include<stdio.h>
#include<pthread.h>
void*thread_proc(void*param)
int first= 0;
int*p0= malloc(1024);
int*p1= malloc(1024 * 1024);
printf("(0x%x): first=%p\n", pthread_self(), &first);
printf("(0x%x): p0=%p p1=%p \n", pthread_self(),p0,p1);
return0;
#defineN5
intmain(intargc,char*argv[])
intfirst = 0;
inti= 0;
void*ret= NULL;
pthread_ttid[N] = {0};
printf("first=%p\n", &first);
for(i= 0; i < N;i++)
pthread_create(tid+i,NULL,thread_proc,NULL);
for(i= 0; i < N;i++)
pthread_join(tid[i], &ret);
return0;
运行后,输出结果为:
first=0xbfd3d35c
(0xb7f2cbb0): first=0xb7f2c454
(0xb7f2cbb0): p0=0x84d52d8 p1=0xb4c27008
(0xb752bbb0): first=0xb752b454
(0xb752bbb0): p0=0x84d56e0 p1=0xb4b26008
(0xb6b2abb0): first=0xb6b2a454
(0xb6b2abb0): p0=0x84d5ae8 p1=0xb4a25008
(0xb6129bb0): first=0xb6129454
(0xb6129bb0): p0=0x84d5ef0 p1=0xb4924008
(0xb5728bb0): first=0xb5728454
(0xb5728bb0): p0=0x84d62f8 p1=0xb7e2c008
我们看一下:
主线程与第一个线程的栈之间的距离:0xbfd3d35c - 0xb7f2c454=0x7e10f08=126M
第一个线程与第二个线程的栈之间的距离:0xb7f2c454 - 0xb752b454=0xa01000=10M
其它几个线程的栈之间距离均为10M。
也就是说,主线程的栈空间最大为126M,而普通线程的栈空间仅为10M,超这个范围就会造成栈溢出。
栈溢出的后果是比较严重的,或者出现Segmentation fault错误,或者出现莫名其妙的错误。
l 栈
栈作为一种基本数据结构,我并不感到惊讶,用来实现函数调用,这也司空见惯的作法。直到我试图找到另外一种方式实现递归操作时,我才感叹于它的巧妙。要实现递归操作,不用栈不是不可能,而是找不出比它更优雅的方式。
尽管大多数编译器在优化时,会把常用的参数或者局部变量放入寄存器中。但用栈来管理函数调用时的临时变量(局部变量和参数)是通用做法,前者只是辅助手段,且只在当前函数中使用,一旦调用下一层函数,这些值仍然要存入栈中才行。
通常情况下,栈向下(低地址)增长,每向栈中PUSH一个元素,栈顶就向低地址扩展,每从栈中POP一个元素,栈顶就向高地址回退。一个有兴趣的问题:在x86平台上,栈顶寄存器为ESP,那么ESP的值在是PUSH操作之前修改呢,还是在PUSH操作之后修改呢?PUSH ESP这条指令会向栈中存入什么数据呢?据说x86系列CPU中,除了286外,都是先修改ESP,再压栈的。由于286没有CPUID指令,有的OS用这种方法检查286的型号。
一个函数内的局部变量以及其调用下一级函数的参数,所占用的内存空间作为一个基本的单元,称为一个帧(frame)。在gdb里,f命令就是用来查看指定帧的信息的。在两个frame之间通过还存有其它信息,比如上一层frame的分界地址(EBP)等。
关于栈的基本知识,就先介绍这么多,我们下面来看看一些关于栈的技巧及应用:
1. backtrace的实现
callstack调试器的基本功能之一,利用此功能,你可以看到各级函数的调用关系。在gdb中,这一功能被称为backtrace,输入bt命令就可以看到当前函数的callstack。它的实现多少有些有趣,我们在这里研究一下。
我们先看看栈的基本模型
函数参数入栈的顺序与具体的调用方式有关
返回本次调用后,下一条指令的地址
保存调用者的EBP,然后EBP指向此时的栈顶。
临时变量1
临时变量2
临时变量3
临时变量…
临时变量5
要实现callstack我们需要知道以下信息:
l 调用函数时的指令地址(即当时的EIP)。
l 指令地址对应的源代码代码位置。
关于第一点,从上表中,我们可以看出,栈中存有各级EIP的值,我们取出来就行了。用下面的代码可以轻易实现:
#include<stdio.h>
intbacktrace(void**BUFFER,int SIZE)
int n = 0;
int*p = &n;
int i = 0;
int ebp = p[1];
int eip = p[2];
for(i= 0; i < SIZE; i++)
BUFFER[i] = (void*)eip;
p = (int*)ebp;
ebp = p[0];
eip = p[1];
return SIZE;
#defineN 4
staticvoid test2()
int i = 0;
void*BUFFER[N] = {0};
backtrace(BUFFER,N);
for(i= 0; i < N; i++)
printf("%p\n", BUFFER[i]);
return;
staticvoid test1()
test2();
staticvoid test()
test1();
intmain(intargc,char*argv[])
test();
return 0;
程序输出:
0x8048460
0x804849c
0x80484a9
0x80484cc
关于第二点,如何把指令地址与行号对应起来,这也很简单。可以从MAP文件或者ELF中查询。Binutil带有一个addr2line的小工具,可以帮助实现这一点。
[root@linux bt]# addr2line 0x804849c -e bt.exe
/root/test/bt/bt.c:42
2. alloca的实现
大家都知道动态分配的内存,一定要释放掉,否则就会有内存泄露。可能鲜有人知,动态分配的内存,可以不用释放。Alloca就是这样一个函数,最后一个a代表auto,即自动释放的意思。
Alloca是在栈中分配内存的。即然是在栈中分配,就像其它在栈中分配的临时变量一样,在当前函数调用完成时,这块内存自动释放。
正如我们前面讲过,栈的大小是有限制的,普通线程的栈只有10M大小,所以在分配时,要量力而行,且不要分配过大内存。
Alloca可能会渐渐的退出历史舞台,原因是新的C/C++标准都支持变长数组。比如int array[n],老版本的编译器要求n是常量,而新编译器允许n是变量。编译器支持的这一功能完全可以取代alloca。
这不是一个标准函数,但像linux和win32等大多数平台都支持。即使少数平台不支持,要自己实现也不难。这里我们简单介绍一下alloca的实现方法。
我们先看看一个小程序,再看看它对应的汇编代码,一切都清楚了。
#include<stdio.h>
intmain(intargc,char*argv[])
int n = 0;
int*p = alloca(1024);
printf("&n=%p p=%p\n", &n,p);
return 0;
汇编代码为:
intmain(intargc,char*argv[])
8048394: 55 push �p
8048395: 89 e5 mov %esp,�p
8048397: 83 ec 18 sub $0x18,%esp
804839a: 83 e4 f0 and $0xfffffff0,%esp
804839d: b8 00 00 00 00 mov $0x0,�x
80483a2: 83 c0 0f add $0xf,�x
80483a5: 83 c0 0f add $0xf,�x
80483a8: c1 e8 04 shr $0x4,�x
80483ab: c1 e0 04 shl $0x4,�x
80483ae: 29 c4 sub �x,%esp
int n = 0;
80483b0: c7 45 fc 00 00 00 00 movl $0x0,0xfffffffc(�p)
int*p = alloca(1024);
80483b7: 81 ec 10 04 00 00 sub $0x410,%esp
80483bd: 8d 44 24 0c lea 0xc(%esp),�x
80483c1: 83 c0 0f add $0xf,�x
80483c4: c1 e8 04 shr $0x4,�x
80483c7: c1 e0 04 shl $0x4,�x
80483ca: 89 45f8 mov �x,0xfffffff8(�p)
printf("&n=%p p=%p\n", &n,p);
80483cd: 8b 45f8 mov 0xfffffff8(�p),�x
80483d0: 89 44 24 08 mov �x,0x8(%esp)
80483d4: 8d 45 fc lea 0xfffffffc(�p),�x
80483d7: 89 44 24 04 mov �x,0x4(%esp)
80483db: c7 04 24 98 84 04 08 movl $0x8048498,(%esp)
80483e2: e8d1 fe ff ff call 80482b8 <printf@plt>
return 0;
80483e7: b8 00 00 00 00 mov $0x0,�x
其中关键的一条指令为:sub $0x410,%esp
由此可以看出实现alloca,仅仅是把ESP减去指定大小,扩大栈空间(记记住栈是向下增长),这块空间就是分配的内存。
3. 可变参数的实现。
对新手来说,可变参数的函数也是比较神奇。还是以一个小程序来说明它的实现。
#include<stdio.h>
#include<stdarg.h>
intprint(constchar*fmt, ...)
int n1 = 0;
int n2 = 0;
int n3 = 0;
va_list ap;
va_start(ap,fmt);
n1 =va_arg(ap,int);
n2 = va_arg(ap,int);
n3 =va_arg(ap,int);
va_end(ap);
printf("n1=%d n2=%d n3=%d\n", n1, n2, n3);
return 0;
intmain(intarg, char argv[])
print("%d\n", 1, 2, 3);
return 0;
我们看看对应的汇编代码:
intprint(constchar*fmt, ...)
8048394: 55 push �p
8048395: 89 e5 mov %esp,�p
8048397: 83 ec 28 sub $0x28,%esp
int n1 = 0;
804839a: c7 45 fc 00 00 00 00 movl $0x0,0xfffffffc(�p)
int n2 = 0;
80483a1: c7 45f8 00 00 00 00 movl $0x0,0xfffffff8(�p)
int n3 = 0;
80483a8: c7 45f4 00 00 00 00 movl $0x0,0xfffffff4(�p)
va_list ap;
va_start(ap,fmt);
80483af: 8d 45 0c lea 0xc(�p),%eax
80483b2: 89 45 f0 mov %eax,0xfffffff0(�p)
n1 =va_arg(ap,int);
80483b5: 8b 55 f0 mov 0xfffffff0(�p),�x
80483b8: 8d 45 f0 lea 0xfffffff0(�p),%eax
80483bb: 83 00 04 addl $0x4,(%eax)
80483be: 8b 02 mov (�x),%eax
80483c0: 89 45 fc mov %eax,0xfffffffc(�p)
n2 = va_arg(ap,int);
80483c3: 8b 55 f0 mov 0xfffffff0(�p),�x
80483c6: 8d 45 f0 lea 0xfffffff0(�p),%eax
80483c9: 83 00 04 addl $0x4,(%eax)
80483cc: 8b 02 mov (�x),%eax
80483ce: 89 45f8 mov %eax,0xfffffff8(�p)
n3 =va_arg(ap,int);
80483d1: 8b 55 f0 mov 0xfffffff0(�p),�x
80483d4: 8d 45 f0 lea 0xfffffff0(�p),%eax
80483d7: 83 00 04 addl $0x4,(%eax)
80483da: 8b 02 mov (�x),%eax
80483dc: 89 45f4 mov %eax,0xfffffff4(�p)
va_end(ap);
printf("n1=%d n2=%d n3=%d\n", n1, n2, n3);
80483df: 8b 45f4 mov 0xfffffff4(�p),%eax
80483e2: 89 44 24 0c mov %eax,0xc(%esp)
80483e6: 8b 45f8 mov 0xfffffff8(�p),%eax
80483e9: 89 44 24 08 mov %eax,0x8(%esp)
80483ed: 8b 45 fc mov 0xfffffffc(�p),%eax
80483f0: 89 44 24 04 mov %eax,0x4(%esp)
80483f4: c7 04 24f8 84 04 08 movl $0x80484f8,(%esp)
80483fb: e8 b8 fe ff ff call 80482b8 <printf@plt>
return 0;
8048400: b8 00 00 00 00 mov $0x0,%eax
intmain(intarg,char argv[])
8048407: 55 push �p
8048408: 89 e5 mov %esp,�p
804840a: 83 ec 18 sub $0x18,%esp
804840d: 83 e4 f0 and $0xfffffff0,%esp
8048410: b8 00 00 00 00 mov $0x0,%eax
8048415: 83 c0 0f add $0xf,%eax
8048418: 83 c0 0f add $0xf,%eax
804841b: c1 e8 04 shr $0x4,%eax
804841e: c1 e0 04 shl $0x4,%eax
8048421: 29 c4 sub %eax,%esp
int n = print("%d\n", 1, 2, 3);
8048423: c7 44 24 0c 03 00 00 movl $0x3,0xc(%esp)
804842a: 00
804842b: c7 44 24 08 02 00 00 movl $0x2,0x8(%esp)
8048432: 00
8048433: c7 44 24 04 01 00 00 movl $0x1,0x4(%esp)
804843a: 00
804843b: c7 04 24 0b 85 04 08 movl $0x804850b,(%esp)
8048442: e8 4d ff ff ff call 8048394 <print>
8048447: 89 45 fc mov %eax,0xfffffffc(�p)
return 0;
804844a: b8 00 00 00 00 mov $0x0,%eax
从汇编代码中,我们可以看出,参数是逆序入栈的。在取参数时,先让ap指向第一个参数,又因为栈是向下增长的,不断把指针向上移动就可以取出所有参数了。
有人可能会说,全局内存就是全局变量嘛,有必要专门一章来介绍吗?这么简单的东西,还能玩出花来?我从来没有深究它,不一样写程序吗?关于全局内存这个主题虽然玩不出花来,但确实有些重要,了解这些知识,对于优化程序的时间和空间很有帮助。因为有好几次这样经历,我才决定花一章篇幅来介绍它。
正如大家所知道的,全局变量是放在全局内存中的,但反过来却未必成立。用static修饰的局部变量就是放在放全局内存的,它的作用域是局部的,但生命期是全局的。在有的嵌入式平台中,堆实际上就是一个全局变量,它占用相当大的一块内存,在运行时,把这块内存进行二次分配。
这里我们并不强调全局变量和全局内存的差别。在本文中,全局强调的是它的生命期,而不是它的作用域,所以有时可能把两者的概念互换。
一般来说,在一起定义的两个全局变量,在内存的中位置是相邻的。这是一个简单的常识,但有时挺有用,如果一个全局变量被破坏了,不防先查查其前后相关变量的访问代码,看看是否存在越界访问的可能。
在ELF格式的可执行文件中,全局内存包括三种:bss、data和rodata。其它可执行文件格式与之类似。了解了这三种数据的特点,我们才能充分发挥它们的长处,达到速度与空间的最优化。
1. bss
已经记不清bss代表Block Storage Start还是Block Started by Symbol。像这我这种没有用过那些史前计算机的人,终究无法明白这样怪异的名字,也就记不住了。不过没有关系,重要的是,我们要清楚bss全局变量有什么样特点,以及如何利用它。
通俗的说,bss是指那些没有初始化的和初始化为0的全局变量。它有什么特点呢,让我们来看看一个小程序的表现。
intbss_array[1024 * 1024] = {0};
intmain(intargc,char*argv[])
return 0;
[root@localhost bss]# gcc -g bss.c -o bss.exe
[root@localhost bss]# ll
total 12
-rw-r--r-- 1root root 84Jun 22 14:32 bss.c
-rwxr-xr-x1 root root 5683 Jun 22 14:32 bss.exe
变量bss_array的大小为4M,而可执行文件的大小只有5K。由此可见,bss类型的全局变量只占运行时的内存空间,而不占文件空间。
另外,大多数操作系统,在加载程序时,会把所有的bss全局变量全部清零,无需要你手工去清零。但为保证程序的可移植性,手工把这些变量初始化为0也是一个好习惯。
2. data
与bss相比,data就容易明白多了,它的名字就暗示着里面存放着数据。当然,如果数据全是零,为了优化考虑,编译器把它当作bss处理。通俗的说,data指那些初始化过(非零)的非const的全局变量。它有什么特点呢,我们还是来看看一个小程序的表现。
intdata_array[1024 * 1024] = {1};
intmain(intargc,char*argv[])
return 0;
[root@localhostdata]# gcc-gdata.c -odata.exe
[root@localhostdata]# ll
total 4112
-rw-r--r-- 1root root 85Jun 22 14:35 data.c
-rwxr-xr-x1 root root 4200025 Jun 22 14:35 data.exe
仅仅是把初始化的值改为非零了,文件就变为4M多。由此可见,data类型的全局变量是即占文件空间,又占用运行时内存空间的。
3. rodata
rodata的意义同样明显,ro代表read only,即只读数据(const)。关于rodata类型的数据,要注意以下几点:
l 常量不一定就放在rodata里,有的立即数直接编码在指令里,存放在代码段(.text)中。
l 对于字符串常量,编译器会自动去掉重复的字符串,保证一个字符串在一个可执行文件(EXE/SO)中只存在一份拷贝。
l rodata是在多个进程间是共享的,这可以提高空间利用率。
l 在有的嵌入式系统中,rodata放在ROM(如norflash)里,运行时直接读取ROM内存,无需要加载到RAM内存中。
l 在嵌入式linux系统中,通过一种叫作XIP(就地执行)的技术,也可以直接读取,而无需要加载到RAM内存中。
由此可见,把在运行过程中不会改变的数据设为rodata类型的,是有很多好处的:在多个进程间共享,可以大大提高空间利用率,甚至不占用RAM空间。同时由于rodata在只读的内存页面(page)中,是受保护的,任何试图对它的修改都会被及时发现,这可以帮助提高程序的稳定性。
4. 变量与关键字
static关键字用途太多,以致于让新手模糊。不过,总结起来就有两种作用,改变生命期和限制作用域。如:
l 修饰inline函数:限制作用域
l 修饰普通函数:限制作用域
l 修饰局部变量:改变生命期
l 修饰全局变量:限制作用域
const关键字倒是比较明了,用const修饰的变量放在rodata里,字符串默认就是常量。对const,注意以下几点就行了。
l 指针常量:指向的数据是常量。如 const char* p = “abc”; p指向的内容是常量,但p本身不是常量,你可以让p再指向”123”。
l 常量指针:指针本身是常量。如:char* const p = “abc”; p本身就是常量,你不能让p再指向”123”。
l 指针常量 +常量指针:指针和指针指向的数据都是常量。const char* const p =”abc”;两者都是常量,不能再修改。
violatile关键字通常用来修饰多线程共享的全局变量和IO内存。告诉编译器,不要把此类变量优化到寄存器中,每次都要老老实实的从内存中读取,因为它们随时都可能变化。这个关键字可能比较生僻,但千万不要忘了它,否则一个错误让你调试好几天也得不到一点线索。
内存管理器(一)
作为一个 C程序员,每天都在和malloc/free/calloc/realloc系列函数打交道。也许和它们混得太熟了,反而忽略了它们的存在,甚至有了三五年的交情,仍然对它们的实现一无所知。相反,一些好奇心未泯的新手,对它们的实现有着浓厚的兴趣。当初正是一个新同事的问题,促使我去研究内存管理算法的实现。内存管理算法多少有些神秘,我们很少想着去实现自己的内存管理算法,这也难怪:有这样需求的情况并不多。其实,至于内存分配算法的实现,说简单也简单,说复杂也复杂。要写一个简单的,或许半天时间就可以搞掂,而要写一个真正实用的,可能要花上你几周甚至几个月的时间。
malloc和free是两个核心函数,而calloc和realloc之所以存在,完全是为了提高效率的缘故。否则完全可以用malloc和free的组合来模拟它们。
拿calloc函数的实现来说,在32位机上,内存管理器保证内存至少是4字节对齐的,其长度也会扩展到能被4字节整除,那么其清零算法就可以优化。可以一次清零4个字节,这大大提高清零速度。
拿realloc函数的实现来说,如果realloc的指针后面有足够的空间,内存管理器可以直接扩展其大小,而无须拷贝原有内容。当然,新大小比原来还小时,更不拷贝了。相反,通过malloc和free来实现realloc时,两种情况下都要拷贝,效率自然会低不少。
另外还有两个非机标准的,但很常用的函数,也涉及到内存分配:strdup和strndup。这两个函数在linux和win32下都支持,非常方便。这完全可以用malloc来模拟,而且没有性能上的损失。
这里我们主要关注malloc和free两个函数的实现,并以glibc 2.3.5(32位linux)为例分析。
内存管理器的目标
内存管理器为什么难写?在设计内存管理算法时,要考虑什么因素?管理内存这是内存管理器的功能需求。正如设计其它软件一样,质量需求一样占有重要的地位。分析内存管理算法之前,我们先看看对内存管理算法的质量需求有哪些:
l 最大化兼容性
要实现内存管理器时,先要定义出分配器的接口函数。接口函数没有必要标新立异,而是要遵循现有标准(如POSIX或者Win32),让使用者可以平滑的过度到新的内存管理器上。
l 最大化可移植性
通常情况下,内存管理器要向OS申请内存,然后进行二次分配。所以,在适当的时候要扩展内存或释放多余的内存,这要调用OS提供的函数才行。OS提供的函数则是因平台而异,尽量抽象出平台相关的代码,保证内存管理器的可移植性。
l 浪费最小的空间
内存管理器要管理内存,必然要使用自己一些数据结构,这些数据结构本身也要占内存空间。在用户眼中,这些内存空间毫无疑问是浪费掉了,如果浪费在内存管理器身的内存太多,显然是不可以接受的。
内存碎片也是浪费空间的罪魁祸首,若内存管理器中有大量的内存碎片,它们是一些不连续的小块内存,它们总量可能很大,但无法使用,这也是不可以接受的。
l 最快的速度
内存分配/释放是常用的操作。按着2/8原则,常用的操作就是性能热点,热点函数的性能对系统的整体性能尤为重要。
l 最大化可调性(以适应于不同的情况)
内存管理算法设计的难点就在于要适应用不同的情况。事实上,如果缺乏应用的上下文,是无法评估内存管理算法的好坏的。可以说在任何情况下,专用算法都比通用算法在时/空性能上的表现更优。
为每种情况都写一套内存管理算法,显然是不太合适的。我们不需要追求最优算法,那样代价太高,能达到次优就行了。设计一套通用内存管理算法,通过一些参数对它进行配置,可以让它在特定情况也有相当出色的表现,这就是可调性。
l 最大化局部性(Locality)
大家都知道,使用cache可以提高程度的速度,但很多人未必知道cache使程序速度提高的真正原因。拿CPU内部的cache和RAM的访问速度相比,速度可能相差一个数量级。两者的速度上的差异固然重要,但这并不是提高速度的充分条件,只是必要条件。
另外一个条件是程序访问内存的局部性(Locality)。大多数情况下,程序总访问一块内存附近的内存,把附近的内存先加入到cache中,下次访问cache中的数据,速度就会提高。否则,如果程序一会儿访问这里,一会儿访问另外一块相隔十万八千里的内存,这只会使数据在内存与cache之间来回搬运,不但于提高速度无益,反而会大大降低程序的速度。
因此,内存管理算法要考虑这一因素,减少cache miss和page fault。
l 最大化调试功能
作为一个C/C++程序员,内存错误可以说是我们的噩梦,上一次的内存错误一定还让你记忆犹新。内存管理器提供的调试功能,强大易用,特别对于嵌入式环境来说,内存错误检测工具缺乏,内存管理器提供的调试功能就更是不可或缺了。
l 最大化适应性
前面说了最大化可调性,以便让内存管理器适用于不同的情况。但是,对于不同情况都要去调设置,无疑太麻烦,是非用户友好的。要尽量让内存管理器适用于很广的情况,只有极少情况下才去调设置。
设计是一个多目标优化的过程,有些目标之间存在着竞争。如何平衡这些竞争力是设计的难点之一。在不同的情况下,这些目标的重要性又不一样,所以根本不存在一个最好的内存分配算法。
关于glibc的内存分配器,我们并打算做代码级分析,只谈谈几点有趣的东西:
1. Glibc分配算法概述:
l 小于等于64字节:用pool算法分配。
l 64到512字节之间:在最佳凭配算法分配和pool算法分配中取一种合适的。
l 大于等于512字节:用最佳凭配算法分配。
l 大于等于128K:直接调用OS提供的函数(如mmap)分配。
2. Glibc扩展内存的方式:
l int brk(void *end_data_segment);
本函数用于扩展堆空间(堆空间的定义可参考内存模型一章),用end_data_segment指明堆的结束地址。
l void *sbrk(ptrdiff_t increment);
本函数用于扩展堆空间(堆空间的定义可参考内存模型一章),用increment指定要增加的大小。
l void* mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset);
本函数用于分配大块内存了,如前面所述大于128K的内存。
3. 空指针和零长度内存
l free(NULL)会让程序crash吗?答案是不会,标准C要求free接受空指针,然后什么也不做。
l malloc(0)会分配成功吗?答案是会的,它会返回一块最小内存给你。
4. 对齐与取整
l 内存管理器会保证分配出来的内存地址是对齐的,通常是4或8字节对齐。
l 内存管理器会对要求内存长度取整,让内存长度能被4或8的整除。
5. 已经分配内存的结构
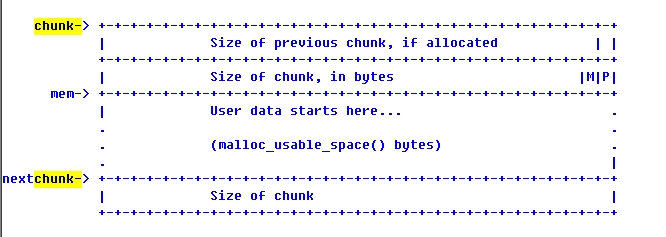
如果前面有一块有效内存块的,则第一个size_t指明前一块内存的大小。
第二个size_t指明自己的大小,同时还指明:自己是不是用mmap分配的(M),前面是否有一个效内存块(P)。你可能觉得奇怪,在32位机上,sizeof(size_t)就是32位,怎么还能留下两个位来保存标志呢?前面我们说了,会对内存长度取整,保证最低2或3bits为0,即是空闲的。
6. 空闲内存的管理

由此可以看出,最小内存块的长度为16字节:
sizeof(size_t) +
sizeof(size_t) +
sizeof(void*) +
sizeof(void*) +
这一招非常管用,第一次看到时,感觉简直太巧妙了。这使得无需要额外的内存来管理空闲块,利用空闲块自己,把空闲块强制转换成一个双向链表就行了。
大内高手—共享内存与线程局部存储
城里的人想出去,城外的人想进来。这是《围城》里的一句话,它可能比《围城》本身更加有名。我想这句话的前提是,要么住在城里,要么住在城外,二者只能居其一。否则想住在城里就可以住在城里,想住在城外就可以住在城外,你大可以选择单日住在城里,双日住在城外,也就没有心思去想出去还是进来了。
理想情况是即可以住在城里又可以住在城外,而不是走向极端。尽管像青蛙一样的两栖动物绝不会比人类更高级,但能适应于更多环境的能力毕竟有它的优势。技术也是如此,共享内存和线程局部存储就是实例,它们是为了防止走向内存完全隔离和完全共享两个极端的产物。
当我们发明了MMU时,大家认为天下太平了,各个进程空间独立,互不影响,程序的稳定性将大提高。但马上又认识到,进程完全隔离也不行,因为各个进程之间需要信息共享。于是就搞出一种称为共享内存的东西。
当我们发明了线程的时,大家认为这下可爽了,线程可以并发执行,创建和切换的开销相对进程来说小多了。线程之间的内存是共享的,线程间通信快捷又方便。但马上又认识到,有些信息还是不共享为好,应该让各个线程保留一点隐私。于是就搞出一个线程局部存储的玩意儿。
共享内存和线程局部存储是两个重要又不常用的东西,平时很少用,但有时候又离不了它们。本文介绍将两者的概念、原理和使用方法,把它们放在自己的工具箱里,以供不时之需。
1. 共享内存
大家都知道进程空间是独立的,它们之间互不影响。比如同是0xabcd1234地址的内存,在不同的进程中,它们的数据是不同的,没有关系的。这样做的好处很多:每个进程的地址空间变大了,它们独占4G(32位)的地址空间,让编程实现更容易。各个进程空间独立,一个进程死掉了,不会影响其它进程,提高了系统的稳定性。
要做到进程空间独立,光靠软件是难以实现的,通常要依赖于硬件的帮助。这种硬件通常称为MMU(Memory Manage Unit),即所谓的内存管理单元。在这种体系结构下,内存分为物理内存和虚拟内存两种。物理内存就是实际的内存,你机器上装了多大内存就有多大内存。而应用程序中使用的是虚拟内存,访问内存数据时,由MMU根据页表把虚拟内存地址转换对应的物理内存地址。
MMU把各个进程的虚拟内存映射到不同的物理内存上,这样就保证了进程的虚拟内存是独立的。然而,物理内存往往远远少于各个进程的虚拟内存的总和。怎么办呢,通常的办法是把暂时不用的内存写到磁盘上去,要用的时候再加载回内存中来。一般会搞一个专门的分区保存内存数据,这就是所谓的交换分区。
这些工作由内核配合MMU硬件完成,内存管理是操作系统内核的重要功能。其中为了优化性能,使用了不少高级技术,所以内存管理通常比较复杂。比如:在决定把什么数据换出到磁盘上时,采用最近最少使用的策略,把常用的内存数据放在物理内存中,把不常用的写到磁盘上,这种策略的假设是最近最少使用的内存在将来也很少使用。在创建进程时使用COW(Copy on Write)的技术,大大减少了内存数据的复制。为了提高从虚拟地址到物理地址的转换速度,硬件通常采用TLB技术,把刚转换的地址存在cache里,下次可以直接使用。
从虚拟内存到物理内存的映射并不是一个字节一个字节映射的,而是以一个称为页(page)最小单位的为基础的,页的大小视硬件平台而定,通常是4K。当应用程序访问的内存所在页面不在物理内存中时,MMU产生一个缺页中断,并挂起当前进程,缺页中断负责把相应的数据从磁盘读入内存中,再唤醒挂起的进程。
进程的虚拟内存与物理内存映射关系如下图所示(灰色页为被不在物理内存中的页):

也许我们很少直接使用共享内存,实际上除非性能上有特殊要求,我更愿意采用socket或者管道作为进程间通信的方式。但我们常常间接的使用共享内存,大家都知道共享库(或称为动态库)的优点是,多个应用程序可以公用。如果每个应用程序都加载一份共享库到内存中,显然太浪费了。所以操作系统把共享库放在共享内存中,让多个应用程序共享。另外,同一个应用程序运行多个实例时,也采用同样的方式,保证内存中只有一份可执行代码。这样的共享内存是设为只读属性的,防止应用程序无意中破坏它们。当调试器要设置断点时,相应的页面被拷贝一分,设置为可写的,再向其中写入断点指令。这些事情完全由操作系统等底层软件处理了,应用程序本身无需关心。
共享内存是怎么实现的呢?我们来看看下图(黄色页为共享内存):

由上图可见,实现共享内存非常容易,只是把两个进程的虚拟内存映射同一块物理内存就行了。不过要注意,物理内存相同而虚拟地址却不一定相同,如图中所示进程1的page5和进程2的page2都映射到物理内存的page1上。
如何在程序中使用共享内存呢?通常很简单,操作系统或者函数库提供了一些API给我们使用。如:
Linux:
void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
Win32:
HANDLE CreateFileMapping(
HANDLE hFile, // handle to file
LPSECURITY_ATTRIBUTES lpAttributes, // security
DWORD flProtect, // protection
DWORD dwMaximumSizeHigh, // high-order DWORD of size
DWORD dwMaximumSizeLow, // low-order DWORD of size
LPCTSTR lpName // object name
);
BOOL UnmapViewOfFile(
LPCVOID lpBaseAddress // starting address
);
2. 线程局部存储(TLS)
同一个进程中的多个线程,它们的内存空间是共享的(栈除外),在一个线程修改的内存内容,对所有线程都生效。这是一个优点也是一个缺点。说它是优点,线程的数据交换变得非常快捷。说它是缺点,一个线程死掉了,其它线程也性命不保;多个线程访问共享数据,需要昂贵的同步开销,也容易造成同步相关的BUG;。
在unix下,大家一直都对线程不是很感兴趣,直到很晚以后才引入线程这东西。像X Sever要同时处理N个客户端的连接,每秒钟要响应上百万个请求,开发人员宁愿自己实现调度机制也不用线程。让人很难想象X Server是单进程单线程模型的。再如Apache(1.3x),在unix下的实现也是采用多进程模型的,把像记分板等公共信息放入共享内存中,也不愿意采用多线程模型。
正如《unix编程艺术》中所说,线程局部存储的出现,使得这种情况出现了转机。采用线程局部存储,每个线程有一定的私有空间。这可以避免部分无意的破坏,不过仍然无法避免有意的破坏行为。
个人认为,这完全是因为unix程序不喜欢面向对象方法引起的,数据没有很好的封装起来,全局变量满天飞,在多线程情况下自然容易出问题。如果采用面向对象的方法,可以让这种情况大为改观,而无需要线程局部存储来帮忙。
当然,多一种技术就多一种选择,知道线程局部存储还是有用的。尽管只用过几次线程局部存储的方法,在那种情况下,没有线程局部存储,确实很难用其它办法实现。
线程局部存储在不同的平台有不同的实现,可移植性不太好。幸好要实现线程局部存储并不难,最简单的办法就是建立一个全局表,通过当前线程ID去查询相应的数据,因为各个线程的ID不同,查到的数据自然也不同了。
大多数平台都提供了线程局部存储的方法,无需要我们自己去实现:
linux:
int pthread_key_create(pthread_key_t *key, void (*destructor)(void*));
int pthread_key_delete(pthread_key_t key);
void *pthread_getspecific(pthread_key_t key);
int pthread_setspecific(pthread_key_t key, const void *value);
__thread int i;
Win32
DWORD TlsAlloc(VOID);
BOOL TlsFree(
DWORD dwTlsIndex // TLS index
BOOL TlsSetValue(
DWORD dwTlsIndex, // TLS index
LPVOID lpTlsValue // value to store
LPVOID TlsGetValue(
DWORD dwTlsIndex // TLS index
__declspec( thread ) int tls_i = 1;
~~end~~
常见内存错误
随着诸如代码重构和单元测试等方法引入实践,调试技能渐渐弱化了,甚至有人主张废除调试器。这是有道理的,原因在于调试的代价往往太大了,特别是调试系统集成之后的BUG,一个BUG花了几天甚至数周时间并非罕见。
而这些难以定位的BUG基本上可以归为两类:内存错误和并发问题。而又以内存错误最为普遍,即使是久经沙场的老手,也有时也难免落入陷阱。前事不忘,后世之师,了解这些常见的错误,在编程时就加以注意,把出错的概率降到最低,可以节省不少时间。
这些列举一些常见的内存错误,供新手参考。
1. 内存泄露。
大家都知道,在堆上分配的内存,如果不再使用了,应该把它释放掉,以便后面其它地方可以重用。在C/C++中,内存管理器不会帮你自动回收不再使用的内存。如果你忘了释放不再使用的内存,这些内存就不能被重用,就造成了所谓的内存泄露。
把内存泄露列为首位,倒并不是因为它有多么严重的后果,而因为它是最为常见的一类错误。一两处内存泄露通常不至于让程序崩溃,也不会出现逻辑上的错误,加上进程退出时,系统会自动释放该进程所有相关的内存,所以内存泄露的后果相对来说还是比较温和的。当然了,量变会产生质变,一旦内存泄露过多以致于耗尽内存,后续内存分配将会失败,程序可能因此而崩溃。
现在的PC机内存够大了,加上进程有独立的内存空间,对于一些小程序来说,内存泄露已经不是太大的威胁。但对于大型软件,特别是长时间运行的软件,或者嵌入式系统来说,内存泄露仍然是致命的因素之一。
不管在什么情况下,采取比较谨慎的态度,杜绝内存泄露的出现,都是可取的。相反,认为内存有的是,对内存泄露放任自流都不是负责的。尽管一些工具可以帮助我们检查内存泄露问题,我认为还是应该在编程时就仔细一点,及早排除这类错误,工具只是用作验证的手段。
2. 内存越界访问。
内存越界访问有两种:一种是读越界,即读了不属于自己的数据,如果所读的内存地址是无效的,程度立刻就崩溃了。如果所读内存地址是有效的,在读的时候不会出问题,但由于读到的数据是随机的,它会产生不可预料的后果。另外一种是写越界,又叫缓冲区溢出。所写入的数据对别人来说是随机的,它也会产生不可预料的后果。
内存越界访问造成的后果非常严重,是程序稳定性的致命威胁之一。更麻烦的是,它造成的后果是随机的,表现出来的症状和时机也是随机的,让BUG的现象和本质看似没有什么联系,这给BUG的定位带来极大的困难。
一些工具可以够帮助检查内存越界访问的问题,但也不能太依赖于工具。内存越界访问通常是动态出现的,即依赖于测试数据,在极端的情况下才会出现,除非精心设计测试数据,工具也无能为力。工具本身也有一些限制,甚至在一些大型项目中,工具变得完全不可用。比较保险的方法还是在编程是就小心,特别是对于外部传入的参数要仔细检查。
3. 野指针。
野指针是指那些你已经释放掉的内存指针。当你调用free(p)时,你真正清楚这个动作背后的内容吗?你会说p指向的内存被释放了。没错,p本身有变化吗?答案是p本身没有变化。它指向的内存仍然是有效的,你继续读写p指向的内存,没有人能拦得住你。
释放掉的内存会被内存管理器重新分配,此时,野指针指向的内存已经被赋予新的意义。对野指针指向内存的访问,无论是有意还是无意的,都为此会付出巨大代价,因为它造成的后果,如同越界访问一样是不可预料的。
释放内存后立即把对应指针置为空值,这是避免野指针常用的方法。这个方法简单有效,只是要注意,当然指针是从函数外层传入的时,在函数内把指针置为空值,对外层的指针没有影响。比如,你在析构函数里把this指针置为空值,没有任何效果,这时应该在函数外层把指针置为空值。
4. 访问空指针。
空指针在C/C++中占有特殊的地址,通常用来判断一个指针的有效性。空指针一般定义为0。现代操作系统都会保留从0开始的一块内存,至于这块内存有多大,视不同的操作系统而定。一旦程序试图访问这块内存,系统就会触发一个异常。
操作系统为什么要保留一块内存,而不是仅仅保留一个字节的内存呢?原因是:一般内存管理都是按页进行管理的,无法单纯保留一个字节,至少要保留一个页面。保留一块内存也有额外的好处,可以检查诸如p=NULL; p[1]之类的内存错误。
在一些嵌入式系统(如arm7)中,从0开始的一块内存是用来安装中断向量的,没有MMU的保护,直接访问这块内存好像不会引发异常。不过这块内存是代码段的,不是程序中有效的变量地址,所以用空指针来判断指针的有效性仍然可行。
在访问指针指向的内存时,在确保指针不是空指针。访问空指针指向的内存,通常会导致程度崩溃,或者不可预料的错误。
5. 引用未初始化的变量。
未初始化变量的内容是随机的(像VC一类的编译器会把它们初始化为固定值,如0xcc),使用这些数据会造成不可预料的后果,调试这样的BUG也是非常困难的。
对于态度严谨的程度员来说,防止这类BUG非常容易。在声明变量时就对它进行初始化,是一个编程的好习惯。另外也要重视编译器的警告信息,发现有引用未初始化的变量,立即修改过来。
6. 不清楚指针运算。
对于一些新手来说,指针常常让他们犯糊涂。
比如int *p = …; p+1等于(size_t)p + 1吗
老手自然清楚,新手可能就搞不清了。事实上, p+n等于 (size_t)p + n * sizeof(*p)
指针是C/C++中最有力的武器,功能非常强大,无论是变量指针还是函数指针,都应该掌握都非常熟练。只要有不确定的地方,马上写个小程序验证一下。对每一个细节都了然于胸,在编程时会省下不少时间。
7. 结构的成员顺序变化引发的错误。
在初始化一个结构时,老手可能很少像新手那样老老实实的,一个成员一个成员的为结构初始化,而是采用快捷方式,如:
Structs
int l;
char*p;
intmain(intargc,char*argv[])
struct s s1 = {4, "abcd"};
return 0;
以上这种方式是非常危险的,原因在于你对结构的内存布局作了假设。如果这个结构是第三方提供的,他很可能调整结构中成员的相对位置。而这样的调整往往不会在文档中说明,你自然很少去关注。如果调整的两个成员具有相同数据类型,编译时不会有任何警告,而程序的逻辑上可能相距十万八千里了。
正确的初始化方法应该是(当然,一个成员一个成员的初始化也行):
structs
int l;
char*p;
intmain(intargc,char*argv[])
struct s s1 = {.l=4, .p= "abcd"};
struct s s2 = {l:4,p:"abcd"};
return 0;
8. 结构的大小变化引发的错误。
我们看看下面这个例子:
structbase
int n;
structs
struct base b;
int m;
在OOP中,我们可以认为第二个结构继承了第一结构,这有什么问题吗?当然没有,这是C语言中实现继承的基本手法。
现在假设第一个结构是第三方提供的,第二个结构是你自己的。第三方提供的库是以DLL方式分发的,DLL最大好处在于可以独立替换。但随着软件的进化,问题可能就来了。
当第三方在第一个结构中增加了一个新的成员int k;,编译好后把DLL给你,你直接给了客户了。程序加载时不会有任何问题,在运行逻辑可能完全改变!原因是两个结构的内存布局重叠了。解决这类错误的唯一办法就是全部重新相关的代码。
解决这类错误的唯一办法就是重新编译全部代码。由此看来,DLL并不见得可以动态替换,如果你想了解更多相关内容,建议阅读《COM本质论》。
9. 分配/释放不配对。
大家都知道malloc要和free配对使用,new要和delete/delete[]配对使用,重载了类new操作,应该同时重载类的delete/delete[]操作。这些都是书上反复强调过的,除非当时晕了头,一般不会犯这样的低级错误。
而有时候我们却被蒙在鼓里,两个代码看起来都是调用的free函数,实际上却调用了不同的实现。比如在Win32下,调试版与发布版,单线程与多线程是不同的运行时库,不同的运行时库使用的是不同的内存管理器。一不小心链接错了库,那你就麻烦了。程序可能动则崩溃,原因在于在一个内存管理器中分配的内存,在另外一个内存管理器中释放时出现了问题。
10. 返回指向临时变量的指针
大家都知道,栈里面的变量都是临时的。当前函数执行完成时,相关的临时变量和参数都被清除了。不能把指向这些临时变量的指针返回给调用者,这样的指针指向的数据是随机的,会给程序造成不可预料的后果。
下面是个错误的例子:
char* get_str(void)
char str[] = {"abcd"};
return str;
intmain(intargc, char* argv[])
char*p = get_str();
printf("%s\n",p);
return 0;
下面这个例子没有问题,大家知道为什么吗?
char*get_str(void)
char*str = {"abcd"};
return str;
intmain(intargc,char*argv[])
char*p = get_str();
printf("%s\n",p);
return 0;
11. 试图修改常量
在函数参数前加上const修饰符,只是给编译器做类型检查用的,编译器禁止修改这样的变量。但这并不是强制的,你完全可以用强制类型转换绕过去,一般也不会出什么错。
而全局常量和字符串,用强制类型转换绕过去,运行时仍然会出错。原因在于它们是是放在.rodata里面的,而.rodata内存页面是不能修改的。试图对它们修改,会引发内存错误。
下面这个程序在运行时会出错:
intmain(intargc,char*argv[])
char*p = "abcd";
*p= '1';
return 0;
12. 误解传值与传引用
在C/C++中,参数默认传递方式是传值的,即在参数入栈时被拷贝一份。在函数里修改这些参数,不会影响外面的调用者。如:
#include <stdlib.h>
#include <stdio.h>
void get_str(char* p)
p = malloc(sizeof("abcd"));
strcpy(p, "abcd");
return;
int main(int argc, char* argv[])
char* p = NULL;
get_str(p);
printf("p=%p\n", p);
return 0;
在main函数里,p的值仍然是空值。
13. 重名符号。
无论是函数名还是变量名,如果在不同的作用范围内重名,自然没有问题。但如果两个符号的作用域有交集,如全局变量和局部变量,全局变量与全局变量之间,重名的现象一定要坚决避免。gcc有一些隐式规则来决定处理同名变量的方式,编译时可能没有任何警告和错误,但结果通常并非你所期望的。
下面例子编译时就没有警告:
#include<stdlib.h>
#include<stdio.h>
intcount = 0;
intget_count(void)
return count;
main.c
#include <stdio.h>
extern int get_count(void);
int count;
int main(int argc, char* argv[])
count = 10;
printf("get_count=%d\n", get_count());
return 0;
如果把main.c中的int count;修改为int count = 0;,gcc就会编辑出错,说multiple definition of `count'。它的隐式规则比较奇妙吧,所以还是不要依赖它为好。
14. 栈溢出。
我们在前面关于堆栈的一节讲过,在PC上,普通线程的栈空间也有十几M,通常够用了,定义大一点的临时变量不会有什么问题。
而在一些嵌入式中,线程的栈空间可能只5K大小,甚至小到只有256个字节。在这样的平台中,栈溢出是最常用的错误之一。在编程时应该清楚自己平台的限制,避免栈溢出的可能。
15. 误用sizeof。
尽管C/C++通常是按值传递参数,而数组则是例外,在传递数组参数时,数组退化为指针(即按引用传递),用sizeof是无法取得数组的大小的。
从下面这个例子可以看出:
voidtest(charstr[20])
printf("%s:size=%d\n", __func__, sizeof(str));
intmain(intargc,char*argv[])
char str[20] = {0};
test(str);
printf("%s:size=%d\n", __func__, sizeof(str));
return 0;
[root@localhost mm]# ./t.exe
test:size=4
main:size=20
16. 字节对齐。
字节对齐主要目的是提高内存访问的效率。但在有的平台(如arm7)上,就不光是效率问题了,如果不对齐,得到的数据是错误的。
所幸的是,大多数情况下,编译会保证全局变量和临时变量按正确的方式对齐。内存管理器会保证动态内存按正确的方式对齐。要注意的是,在不同类型的变量之间转换时要小心,如把char*强制转换为int*时,要格外小心。
另外,字节对齐也会造成结构大小的变化,在程序内部用sizeof来取得结构的大小,这就足够了。若数据要在不同的机器间传递时,在通信协议中要规定对齐的方式,避免对齐方式不一致引发的问题。
17. 字节顺序。
字节顺序历来是设计跨平台软件时头疼的问题。字节顺序是关于数据在物理内存中的布局的问题,最常见的字节顺序有两种:大端模式与小端模式。
大端模式是高位字节数据存放在低地址处,低位字节数据存放在高地址处。
小端模式指低位字节数据存放在内存低地址处,高位字节数据存放在内存高地址处;
比如long n = 0x11223344。
第1个字节
第2个字节
第3个字节
第4个字节
在普通软件中,字节顺序问题并不引人注目。而在开发与网络通信和数据交换有关的软件时,字节顺序问题就要特殊注意了。
18. 多线程共享变量没有用valotile修饰。
在关于全局内存的一节中,我们讲了valotile的作用,它告诉编译器,不要把变量优化到寄存器中。在开发多线程并发的软件时,如果这些线程共享一些全局变量,这些全局变量最好用valotile修饰。这样可以避免因为编译器优化而引起的错误,这样的错误非常难查。
可能还有其它一些内存相关错误,一时想不全面,这里算是抛砖引玉吧,希望各位高手补充。
《POSA》中根据模式粒度把模式分为三类:架构模式、设计模式和惯用手法。其中把分层模式、管道过滤器和微内核模式等归为架构模式,把代理模式、命令模式和出版-订阅模式等归为设计模式,而把引用计数等归为惯用手法。这三类模式间的界限比较模糊,在特定的情况,有的设计模式可以作为架构模式来用,有的把架构模式也作为设计模式来用。
在通常情况下,我们可以说架构模式、设计模式和惯用手法,三者的重要性依次递减,毕竟整体决策比局部决策的影响面更大。但是任何整体都是局部组成的,局部的决策也会影响全局。惯用手法的影响虽然是局部的,其作用仍然很重要。它不但在提高软件的质量方面,而且在加快软件开发进度方面都有很大贡献。本文介绍几种关于内存的惯用手法,这些手法对于老手来说已经习以为常,对于新手来说则是必修秘技。
1. 预分配
假想我们实现了一个动态数组(vector)时,当向其中增加元素时,它会自动扩展(缩减)缓冲区的大小,无需要调用者关心。扩展缓冲区的大小的原理都是一样的:
l 先分配一块更大的缓冲区。
l 把数据从老的缓冲区拷贝到新的缓冲区。
l 释放老的缓冲区。
如果你使用realloc来实现,内存管理器可能会做些优化:如果老的缓冲区后面有连续的空闲空间,它只需要简单的扩展老的缓冲区,而跳过后面两个步骤。但在大多数情况下,它都要通过上述三个步骤来完成扩展。
以此可见,扩展缓冲区对调用者来说虽然是透明的,但决不是免费的。它得付出相当大的时间代价,以及由此产生的产生内存碎片问题。如果每次向vector中增加一个元素,都要扩展缓冲区,显然是不太合适的。
此时我们可以采用预分配机制,每次扩展时,不是需要多大就扩展多大,而是预先分配一大块内存。这一大块可以供后面较长一段时间使用,直到把这块内存全用完了,再继续用同样的方式扩展。
预分配机制比较常见,多见于一些带buffer的容器实现中,比如像vector和string等。
2. 对象引用计数
在面向对象的系统中,对象之间的协作关系非常复杂。所谓协作其实就调用对象的函数或者向对象发送消息,但不管调用函数还是发送消息,总是要通过某种方式知道目标对象才行。而最常见的做法就是保存目标对象的引用(指针),直接引用对象而不是拷贝对象,提高了时间和空间上的效率,也避免了拷贝对象的麻烦,而且有的地方就是要对象共享才行。
对象被别人引用了,但自己可能并不知道。此时麻烦就来了,如果对象被释放了,对该对象的引用就变成了野针,系统随时可能因此而崩溃。不释放也不行,因为那样会出现内存泄露。怎么办呢?
此时我们可以采用对象引用计数,对象有一个引用计数器,不管谁要引用这个对象,就要把对象的引用计数器加1,如果不再该引用了,就把对象的引用计数器减1。当对象的引用计数器被减为0时,说明没有其它对象引用它,该对象就可以安全的释放了。这样,对象的生命周期就得到了有效的管理。
对象引用计数运用相当广泛。像在COM和glib里,都是作为对象系统的基本设施之一。即使在像JAVA和C#等现代语言中,对象引用计数也是非常重要的,它是实现垃圾回收(GC)的基本手段之一。
代码示例: (atlcom.h: CcomObject)
STDMETHOD_(ULONG,AddRef)() {returnInternalAddRef();}
STDMETHOD_(ULONG,Release)()
ULONG l = InternalRelease();
if (l == 0)
delete this;
return l;
3. 写时拷贝(COW)
OS内核创建子进程的过程是最常见而且最有效的COW例子:创建子进程时,子进程要继承父进程内存空间中的数据。但继承之后,两者各自有独立的内存空间,修改各自的数据不会互相影响。
要做到这一点,最简单的办法就是直接把父进程的内存空间拷贝一份。这样做可行,但问题在于拷贝内容太多,无论是时间还是空间上的开销都让人无法接受。况且,在大多数情况下,子进程只会使用少数继承过来的数据,而且多数是读取,只有少量是修改,也就说大部分拷贝的动作白做了。怎么办呢?
此时可以采用写时拷贝(COW),COW代表Copy on Write。最初的拷贝只是个假象,并不是真正的拷贝,只是把引用计数加1,并设置适当的标志。如果双方都只是读取这些数据,那好办,直接读就行了。而任何一方要修改时,为了不影响另外一方,它要把数据拷贝一份,然后修改拷贝的这一份。也就是说在修改数据时,拷贝动作才真正发生。
当然,在真正拷贝的时候,你可以选择只拷贝修改的那一部分,或者拷贝全部数据。在上面的例子中,由于内存通常是按页面来管理的,拷贝时只拷贝相关的页面,而不是拷贝整个内存空间。
写时拷贝(COW)对性能上的贡献很大,差不多任何带MMU的OS都会采用。当然它不限于内核空间,在用户空间也可以使用,比如像一些String类的实现也采用了这种方法。
代码示例(MFC:strcore.cpp):
拷贝时只是增加引用计数:
CString::CString(constCString&stringSrc)
ASSERT(stringSrc.GetData()->nRefs!= 0);
if (stringSrc.GetData()->nRefs>= 0)
ASSERT(stringSrc.GetData() != _afxDataNil);
m_pchData = stringSrc.m_pchData;
InterlockedIncrement(&GetData()->nRefs);
Init();
*this = stringSrc.m_pchData;
修改前才拷贝:
voidCString::MakeUpper()
CopyBeforeWrite();
_tcsupr(m_pchData);
voidCString::MakeLower()
CopyBeforeWrite();
_tcslwr(m_pchData);
拷贝动作:
voidCString::CopyBeforeWrite()
if (GetData()->nRefs> 1)
CStringData*pData = GetData();
Release();
AllocBuffer(pData->nDataLength);
memcpy(m_pchData,pData->data(), (pData->nDataLength+1)*sizeof(TCHAR));
ASSERT(GetData()->nRefs<= 1);
4. 固定大小分配
频繁的分配大量小块内存是内存管理器的挑战之一。
首先是空间利用率上的问题:由于内存管理本身的需要一些辅助内存,假设每块内存需要8字节用作辅助内存,那么即使只要分配4个字节这样的小块内存,仍然要浪费8字节内存。一块小内存不要紧,若存在大量小块内存,所浪费的空间就可观了。
其次是内存碎片问题:频繁分配大量小块内存,很容易造成内存碎片问题。这不但降低内存管理器的效率,同时由于这些内存不连续,虽然空闲却无法使用。
此时可以采用固定大小分配,这种方式通常也叫做缓冲池(pool)分配。缓冲池(pool)先分配一块或者多块连续的大块内存,把它们分成N块大小相等的小块内存,然后进行二次分配。由于这些小块内存大小是固定的,管理大开销非常小,往往只要一个标识位用于标识该单元是否空闲,或者甚至不需要任何标识位。另外,缓冲池(pool)中所有这些小块内存分布在一块或者几块连接内存上,所以不会有内存碎片问题。
固定大小分配运用比较广泛,差不多所有的内存管理器都用这种方法来对付小块内存,比如glibc、STLPort和linux的slab等。
5. 会话缓冲池分配(Session Pool)
服务器要长时间运行,内存泄露是它的威胁之一,任何小概率的内存泄露,都可能会累积到具有破坏性的程度。从它们的运行模式来看,它们总是不断的重复某个过程,而在这个过程中,又要分配大量(次数)内存。
比如像WEB服务器,它不断的处理HTTP请求,我们把一次HTTP请求,称为一次会话。一次会话要经过很多阶段,在这个过程要做各种处理,要多次分配内存。由于处理比较复杂,分配内存的地方又比较多,内存泄露可以说防不甚防。
针对这种情况,我们可以采用会话缓冲池分配。它基于多次分配一次释放的策略,在过程开始时创建会话缓冲池(Session Pool),这个过程中所有内存分配都通过会话缓冲池(Session Pool)来分配,当这个过程完成时,销毁掉会话缓冲池(Session Pool),即释放这个过程中所分配的全部内存。
因为只需要释放一次,内存泄露的可能大大降低。会话缓冲池分配并不是太常见,apache采用的这种用法。后来自己用过两次,感觉效果不错。
当然还有其一些内存惯用手法,如cache等,这里不再多说。上述部分手法在《实时设计模式》里有详细的描述,大家可以参考一下。
调试手段及原理
知其然也知其所以然,是我们《大内高手》系列一贯做法,本文亦是如此。这里我不打算讲解如何使用boundschecker、purify、valgrind或者gdb,使用这些工具非常简单,讲解它们只是多此一举。相反,我们要研究一下这些工具的实现原理。本文将从应用程序、编译器和调试器三个层次来讲解,在不同的层次,有不同的方法,这些方法有各自己的长处和局限。了解这些知识,一方面满足一下新手的好奇心,另一方面也可能有用得着的时候。
从应用程序的角度
最好的情况是从设计到编码都扎扎实实的,避免把错误引入到程序中来,这才是解决问题的根本之道。问题在于,理想情况并不存在,现实中存在着大量有内存错误的程序,如果内存错误很容易避免,JAVA/C#的优势将不会那么突出了。
对于内存错误,应用程序自己能做的非常有限。但由于这类内存错误非常典型,所占比例非常大,所付出的努力与所得的回报相比是非常划算的,仍然值得研究。
前面我们讲了,堆里面的内存是由内存管理器管理的。从应用程序的角度来看,我们能做到的就是打内存管理器的主意。其实原理很简单:
对付内存泄露。重载内存管理函数,在分配时,把这块内存的记录到一个链表中,在释放时,从链表中删除吧,在程序退出时,检查链表是否为空,如果不为空,则说明有内存泄露,否则说明没有泄露。当然,为了查出是哪里的泄露,在链表还要记录是谁分配的,通常记录文件名和行号就行了。
对付内存越界/野指针。对这两者,我们只能检查一些典型的情况,对其它一些情况无能为力,但效果仍然不错。其方法如下(源于《Comparing and contrasting the runtime error detection technologies》):
l 首尾在加保护边界值
Header
Leading guard(0xFC)
User data(0xEB)
Tailing guard(0xFC)
在内存分配时,内存管理器按如上结构填充分配出来的内存。其中Header是管理器自己用的,前后各有几个字节的guard数据,它们的值是固定的。当内存释放时,内存管理器检查这些guard数据是否被修改,如果被修改,说明有写越界。
它的工作机制注定了有它的局限性:只能检查写越界,不能检查读越界,而且只能检查连续性的写越界,对于跳跃性的写越界无能为力。
l 填充空闲内存
空闲内存(0xDD)
内存被释放之后,它的内容填充成固定的值。这样,从指针指向的内存的数据,可以大致判断这个指针是否是野指针。
它同样有它的局限:程序要主动判断才行。如果野指针指向的内存立即被重新分配了,它又被填充成前面那个结构,这时也无法检查出来。
从编译器的角度
boundschecker和purify的实现都可以归于编译器一级。前者采用一种称为CTI(compile-time instrumentation)的技术。VC的编译不是要分几个阶段吗?boundschecker在预处理和编译两个阶段之间,对源文件进行修改。它对所有内存分配释放、内存读写、指针赋值和指针计算等所有内存相关的操作进行分析,并插入自己的代码。比如:
Before
if (m_hsession) gblHandles->ReleaseUserHandle( m_hsession );
if (m_dberr) delete m_dberr;
After
if (m_hsession) {
_Insight_stack_call(0);
gblHandles->ReleaseUserHandle(m_hsession);
_Insight_after_call();
_Insight_ptra_check(1994, (void **) &m_dberr, (void *) m_dberr);
if (m_dberr) {
_Insight_deletea(1994, (void **) &m_dberr, (void *) m_dberr, 0);
delete m_dberr;
Purify则采用一种称为OCI(object code insertion)的技术。不同的是,它对可执行文件的每条指令进行分析,找出所有内存分配释放、内存读写、指针赋值和指针计算等所有内存相关的操作,用自己的指令代替原始的指令。
boundschecker和purify是商业软件,它们的实现是保密的,甚至拥有专利的,无法对其研究,只能找一些皮毛性的介绍。无论是CTI还是OCI这样的名称,多少有些神秘感。其实它们的实现原理并不复杂,通过对valgrind和gcc的bounds checker扩展进行一些粗浅的研究,我们可以知道它们的大致原理。
gcc的bounds checker基本上可以与boundschecker对应起来,都是对源代码进行修改,以达到控制内存操作功能,如malloc/free等内存管理函数、memcpy/strcpy/memset等内存读取函数和指针运算等。Valgrind则与Purify类似,都是通过对目标代码进行修改,来达到同样的目的。
Valgrind对可执行文件进行修改,所以不需要重新编译程序。但它并不是在执行前对可执行文件和所有相关的共享库进行一次性修改,而是和应用程序在同一个进程中运行,动态的修改即将执行的下一段代码。
Valgrind是插件式设计的。Core部分负责对应用程序的整体控制,并把即将修改的代码,转换成一种中间格式,这种格式类似于RISC指令,然后把中间代码传给插件。插件根据要求对中间代码修改,然后把修改后的结果交给core。core接下来把修改后的中间代码转换成原始的x86指令,并执行它。
由此可见,无论是boundschecker、purify、gcc的bounds checker,还是Valgrind,修改源代码也罢,修改二进制也罢,都是代码进行修改。究竟要修改什么,修改成什么样子呢?别急,下面我们就要来介绍:
管理所有内存块。无论是堆、栈还是全局变量,只要有指针引用它,它就被记录到一个全局表中。记录的信息包括内存块的起始地址和大小等。要做到这一点并不难:对于在堆里分配的动态内存,可以通过重载内存管理函数来实现。对于全局变量等静态内存,可以从符号表中得到这些信息。
拦截所有的指针计算。对于指针进行乘除等运算通常意义不大,最常见运算是对指针加减一个偏移量,如++p、p=p+n、p=a[n]等。所有这些有意义的指针操作,都要受到检查。不再是由一条简单的汇编指令来完成,而是由一个函数来完成。
有了以上两点保证,要检查内存错误就非常容易了:比如要检查++p是否有效,首先在全局表中查找p指向的内存块,如果没有找到,说明p是野指针。如果找到了,再检查p+1是否在这块内存范围内,如果不是,那就是越界访问,否则是正常的了。怎么样,简单吧,无论是全局内存、堆还是栈,无论是读还是写,无一能够逃过出工具的法眼。
代码赏析(源于tcc):
对指针运算进行检查:
void*__bound_ptr_add(void*p,int offset)
unsigned long addr = (unsigned long)p;
BoundEntry *e;
#ifdefined(BOUND_DEBUG)
printf("add: 0x%x %d\n", (int)p,offset);
#endif
e = __bound_t1[addr>> (BOUND_T2_BITS+ BOUND_T3_BITS)];
e = (BoundEntry*)((char*)e+
((addr >> (BOUND_T3_BITS- BOUND_E_BITS)) &
((BOUND_T2_SIZE- 1) << BOUND_E_BITS)));
addr -= e->start;
if (addr > e->size) {
e = __bound_find_region(e,p);
addr = (unsigned long)p- e->start;
addr += offset;
if (addr > e->size)
return INVALID_POINTER;
return p + offset;
staticvoid __bound_check(constvoid *p,size_t size)
if (size == 0)
return;
p = __bound_ptr_add((void*)p,size);
if (p == INVALID_POINTER)
bound_error("invalid pointer");
重载内存管理函数:
void*__bound_malloc(size_tsize,const void *caller)
void *ptr;
ptr= libc_malloc(size+ 1);
if (!ptr)
return NULL;
__bound_new_region(ptr,size);
return ptr;
void__bound_free(void*ptr,const void *caller)
if (ptr == NULL)
return;
if (__bound_delete_region(ptr) != 0)
bound_error("freeing invalid region");
libc_free(ptr);
重载内存操作函数:
void*__bound_memcpy(void*dst,const void *src,size_t size)
__bound_check(dst,size);
__bound_check(src,size);
if (src >= dst && src < dst + size)
bound_error("overlapping regions in memcpy()");
return memcpy(dst,src,size);
从调试器的角度
现在有OS的支持,实现一个调试器变得非常简单,至少原理不再神秘。这里我们简要介绍一下win32和linux中的调试器实现原理。
在Win32下,实现调试器主要通过两个函数:WaitForDebugEvent和ContinueDebugEvent。下面是一个调试器的基本模型(源于:《Debugging Applications for Microsoft .NET and Microsoft Windows》)
voidmain ( void )
CreateProcess ( ..., DEBUG_ONLY_THIS_PROCESS,... ) ;
while ( 1 == WaitForDebugEvent( ... ) )
if ( EXIT_PROCESS )
break ;
ContinueDebugEvent ( ... ) ;
由调试器起动被调试的进程,并指定DEBUG_ONLY_THIS_PROCESS标志。按Win32下事件驱动的一贯原则,由被调试的进程主动上报调试事件,调试器然后做相应的处理。
在linux下,实现调试器只要一个函数就行了:ptrace。下面是个简单示例:(源于《Playing with ptrace》)。
#include<sys/ptrace.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#include<linux/user.h>
intmain(intargc,char *argv[])
{ pid_ttraced_process;
struct user_regs_struct regs;
long ins;
if(argc!= 2) {
printf("Usage: %s <pid to be traced>\n",
argv[0],argv[1]);
exit(1);
traced_process = atoi(argv[1]);
ptrace(PTRACE_ATTACH,traced_process,
NULL,NULL);
wait(NULL);
ptrace(PTRACE_GETREGS,traced_process,
NULL, ®s);
ins = ptrace(PTRACE_PEEKTEXT, traced_process,
regs.eip,NULL);
printf("EIP: %lx Instruction executed: %lx\n",
regs.eip,ins);
ptrace(PTRACE_DETACH,traced_process,
NULL,NULL);
return 0;
由于篇幅有限,这里对于调试器的实现不作深入讨论,主要是给新手指一个方向。以后若有时间,再写个专题来介绍linux下的调试器和ptrace本身的实现方法。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK