
19

将CSV的数据发送到kafka(java版)
source link: http://www.cnblogs.com/bolingcavalry/p/13983379.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
为什么将CSV的数据发到kafka
- flink做流式计算时,选用kafka消息作为数据源是常用手段,因此在学习和开发flink过程中,也会将数据集文件中的记录发送到kafka,来模拟不间断数据;
-
整个流程如下:
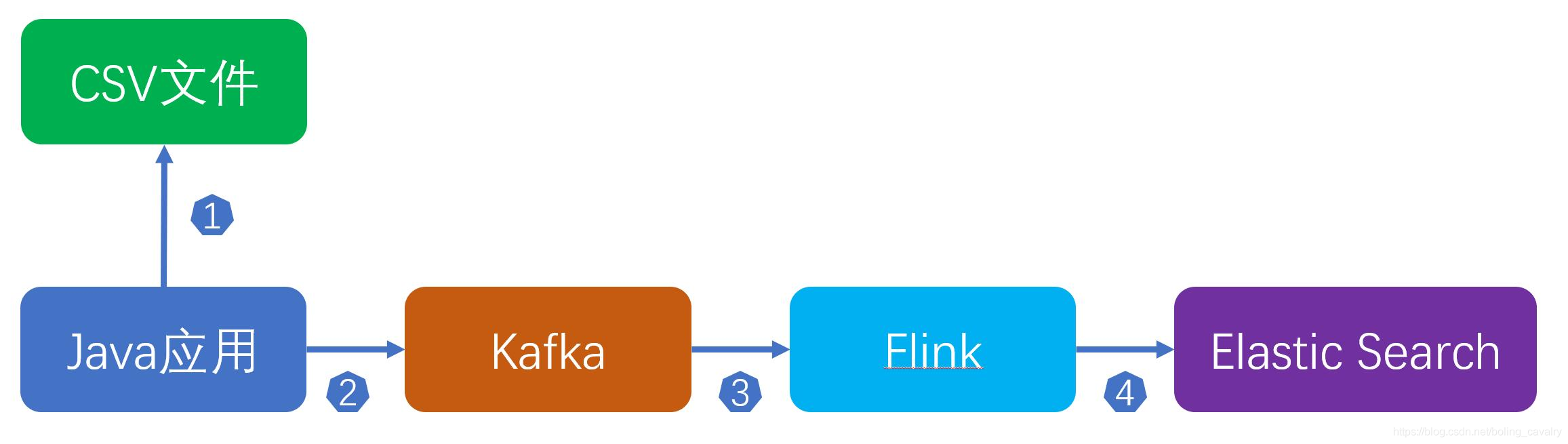
- 您可能会觉得这样做多此一举:flink直接读取CSV不就行了吗?这样做的原因如下:
- 首先,这是学习和开发时的做法,数据集是CSV文件,而生产环境的实时数据却是kafka数据源;
- 其次,Java应用中可以加入一些特殊逻辑,例如数据处理,汇总统计(用来和flink结果对比验证);
- 另外,如果两条记录实际的间隔时间如果是1分钟,那么Java应用在发送消息时也可以间隔一分钟再发送,这个逻辑在flink社区的demo中有具体的实现,此demo也是将数据集发送到kafka,再由flink消费kafka,地址是: https://github.com/ververica/sql-training
如何将CSV的数据发送到kafka
前面的图可以看出,读取CSV再发送消息到kafka的操作是Java应用所为,因此今天的主要工作就是开发这个Java应用,并验证;
版本信息
- JDK:1.8.0_181
- 开发工具:IntelliJ IDEA 2019.2.1 (Ultimate Edition)
- 开发环境:Win10
- Zookeeper:3.4.13
- Kafka:2.4.0(scala:2.12)
关于数据集
- 本次实战用到的数据集是CSV文件,里面是一百零四万条淘宝用户行为数据,该数据来源是阿里云天池公开数据集,我对此数据做了少量调整;
- 此CSV文件可以在CSDN下载,地址: https://download.csdn.net/download/boling_cavalry/12381698
- 也可以在我的Github下载,地址: https://raw.githubusercontent.com/zq2599/blog_demos/master/files/UserBehavior.7z
- 该CSV文件的内容,一共有六列,每列的含义如下表:
- 关于该数据集的详情,请参考 《准备数据集用于flink学习》
Java应用简介
编码前,先把具体内容列出来,然后再挨个实现:
- 从CSV读取记录的工具类:UserBehaviorCsvFileReader
- 每条记录对应的Bean类:UserBehavior
- Java对象序列化成JSON的序列化类:JsonSerializer
- 向kafka发送消息的工具类:KafkaProducer
- 应用类,程序入口:SendMessageApplication
上述五个类即可完成Java应用的工作,接下来开始编码吧;
直接下载源码
- 如果您不想写代码,您可以直接从GitHub下载这个工程的源码,地址和链接信息如下表所示:
-
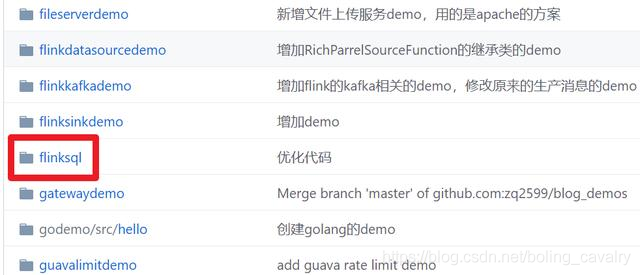
这个git项目中有多个文件夹,本章源码在flinksql这个文件夹下,如下图红框所示:
编码
- 创建maven工程,pom.xml如下,比较重要的jackson和javacsv的依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<artifactId>flinksql</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.0</flink.version>
<kafka.version>2.2.0</kafka.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.10.1</version>
</dependency>
<!-- Logging dependencies -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>net.sourceforge.javacsv</groupId>
<artifactId>javacsv</artifactId>
<version>2.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- Shade plugin to include all dependencies -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 从CSV读取记录的工具类:UserBehaviorCsvFileReader,后面在主程序中会用到java8的Steam API来处理集合,所以UserBehaviorCsvFileReader实现了Supplier接口:
public class UserBehaviorCsvFileReader implements Supplier<UserBehavior> {
private final String filePath;
private CsvReader csvReader;
public UserBehaviorCsvFileReader(String filePath) throws IOException {
this.filePath = filePath;
try {
csvReader = new CsvReader(filePath);
csvReader.readHeaders();
} catch (IOException e) {
throw new IOException("Error reading TaxiRecords from file: " + filePath, e);
}
}
@Override
public UserBehavior get() {
UserBehavior userBehavior = null;
try{
if(csvReader.readRecord()) {
csvReader.getRawRecord();
userBehavior = new UserBehavior(
Long.valueOf(csvReader.get(0)),
Long.valueOf(csvReader.get(1)),
Long.valueOf(csvReader.get(2)),
csvReader.get(3),
new Date(Long.valueOf(csvReader.get(4))*1000L));
}
} catch (IOException e) {
throw new NoSuchElementException("IOException from " + filePath);
}
if (null==userBehavior) {
throw new NoSuchElementException("All records read from " + filePath);
}
return userBehavior;
}
}
- 每条记录对应的Bean类:UserBehavior,和CSV记录格式保持一致即可,表示时间的ts字段,使用了JsonFormat注解,在序列化的时候以此来控制格式:
public class UserBehavior {
@JsonFormat
private long user_id;
@JsonFormat
private long item_id;
@JsonFormat
private long category_id;
@JsonFormat
private String behavior;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd'T'HH:mm:ss'Z'")
private Date ts;
public UserBehavior() {
}
public UserBehavior(long user_id, long item_id, long category_id, String behavior, Date ts) {
this.user_id = user_id;
this.item_id = item_id;
this.category_id = category_id;
this.behavior = behavior;
this.ts = ts;
}
}
- Java对象序列化成JSON的序列化类:JsonSerializer
public class JsonSerializer<T> {
private final ObjectMapper jsonMapper = new ObjectMapper();
public String toJSONString(T r) {
try {
return jsonMapper.writeValueAsString(r);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Could not serialize record: " + r, e);
}
}
public byte[] toJSONBytes(T r) {
try {
return jsonMapper.writeValueAsBytes(r);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Could not serialize record: " + r, e);
}
}
}
- 向kafka发送消息的工具类:KafkaProducer:
public class KafkaProducer implements Consumer<UserBehavior> {
private final String topic;
private final org.apache.kafka.clients.producer.KafkaProducer<byte[], byte[]> producer;
private final JsonSerializer<UserBehavior> serializer;
public KafkaProducer(String kafkaTopic, String kafkaBrokers) {
this.topic = kafkaTopic;
this.producer = new org.apache.kafka.clients.producer.KafkaProducer<>(createKafkaProperties(kafkaBrokers));
this.serializer = new JsonSerializer<>();
}
@Override
public void accept(UserBehavior record) {
// 将对象序列化成byte数组
byte[] data = serializer.toJSONBytes(record);
// 封装
ProducerRecord<byte[], byte[]> kafkaRecord = new ProducerRecord<>(topic, data);
// 发送
producer.send(kafkaRecord);
// 通过sleep控制消息的速度,请依据自身kafka配置以及flink服务器配置来调整
try {
Thread.sleep(500);
}catch(InterruptedException e){
e.printStackTrace();
}
}
/**
* kafka配置
* @param brokers The brokers to connect to.
* @return A Kafka producer configuration.
*/
private static Properties createKafkaProperties(String brokers) {
Properties kafkaProps = new Properties();
kafkaProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
kafkaProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
kafkaProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
return kafkaProps;
}
}
- 最后是应用类SendMessageApplication,CSV文件路径、kafka的topic和borker地址都在此设置,另外借助java8的Stream API,只需少量代码即可完成所有工作:
public class SendMessageApplication {
public static void main(String[] args) throws Exception {
// 文件地址
String filePath = "D:\\temp\\202005\\02\\UserBehavior.csv";
// kafka topic
String topic = "user_behavior";
// kafka borker地址
String broker = "192.168.50.43:9092";
Stream.generate(new UserBehaviorCsvFileReader(filePath))
.sequential()
.forEachOrdered(new KafkaProducer(topic, broker));
}
}
验证
- 请确保kafka已经就绪,并且名为user_behavior的topic已经创建;
- 请将CSV文件准备好;
- 确认SendMessageApplication.java中的文件地址、kafka topic、kafka broker三个参数准确无误;
- 运行SendMessageApplication.java;
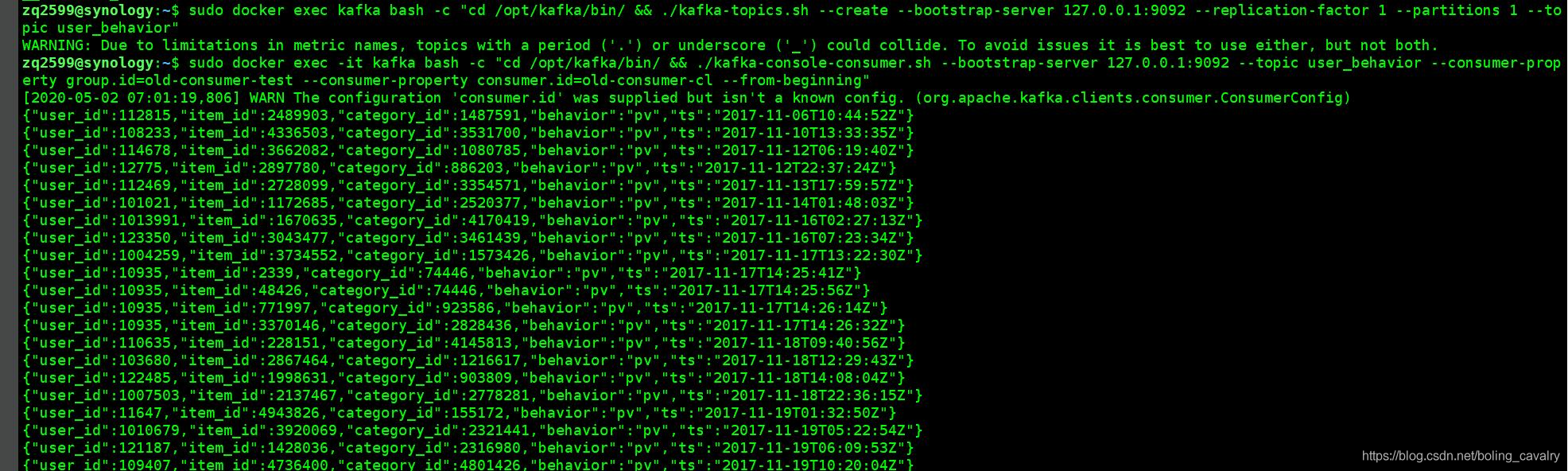
- 开启一个 控制台消息kafka消息,参考命令如下:
./kafka-console-consumer.sh \ --bootstrap-server 127.0.0.1:9092 \ --topic user_behavior \ --consumer-property group.id=old-consumer-test \ --consumer-property consumer.id=old-consumer-cl \ --from-beginning
-
正常情况下可以立即见到消息,如下图:
至此,通过Java应用模拟用户行为消息流的操作就完成了,接下来的flink实战就用这个作为数据源;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demosRecommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK