

Deconstructing a git commit
source link: https://krishnabiradar.com/blogs/deconstructing-a-git-commit/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
I've been spending my last couple weeks in getting to understand git better and how it works under the hood. Once I understood the inner workings, things like git's 3-way merge and interactive rebase became much clearer to me and I felt more confident with git. So, without wasting any further time, let's get started in understanding how git works.
Every git repo contains a .git directory and everything git tracks or is aware of is stored in this .git directory. When we tell git to track a directory, it creates this .git directory inside that directory and this is where all the magic happens. Let's create a brand new git repository with the `git init` command and have a look at what's inside the .git directory.

directory tree of a fresh git repo
I have briefly explained what each file/directory is about, if some or most of it doesn't make much sense to you then do not worry. After we go through the process of creating a commit, things will be more clear. In this post, we will focus on the object's directory and look at the other directories in the next post. Let's make our first commit and see if we notice any changes in our .git directory. Let's create a file named file1.txt with the content "hello world" in it.
file1.txt
Now let's create our first commit by commiting file1.txt to git and see how it changes the .git directory.
1. git add file1.txt
2. git commit -m "Initial commit"
you might have files with different names, since these file names depend on your git configurations
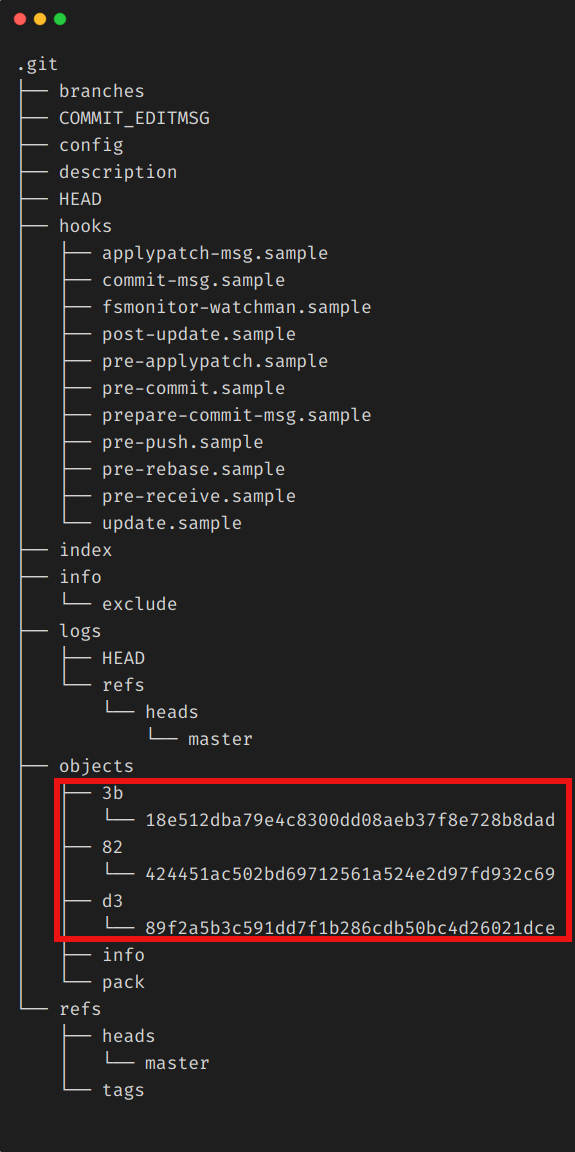
As you can see, after the commit there are 3 new directories in the objects directory with one file in each one of them. Now, let me explain what these three files are about and how and why did git created them. In Git's term, these three files are called object files. There are four types of object files in git:
- Blob - A "blob" is used to store file contents.
- Tree - A "tree" stores information about files/directories like their name, permissions etc and references to other tree objects
- Commit - A "commit" stores reference to a single tree (what i like to call the root tree object), marking it as what the project looked like at a certain point in time. It also contains meta-information about that point in time, such as a timestamp, the author , a pointer to the previous commit(s) (also called parent commit), etc.
- Tag - A "tag" is a way to mark a specific commit as special in some way. It is normally used to tag certain commits as specific releases.
If you actually look at the contents of any of these object files with the cat command, you will see gibberish, that is because git compresses all the contents of the object files with Zlib before storing them.
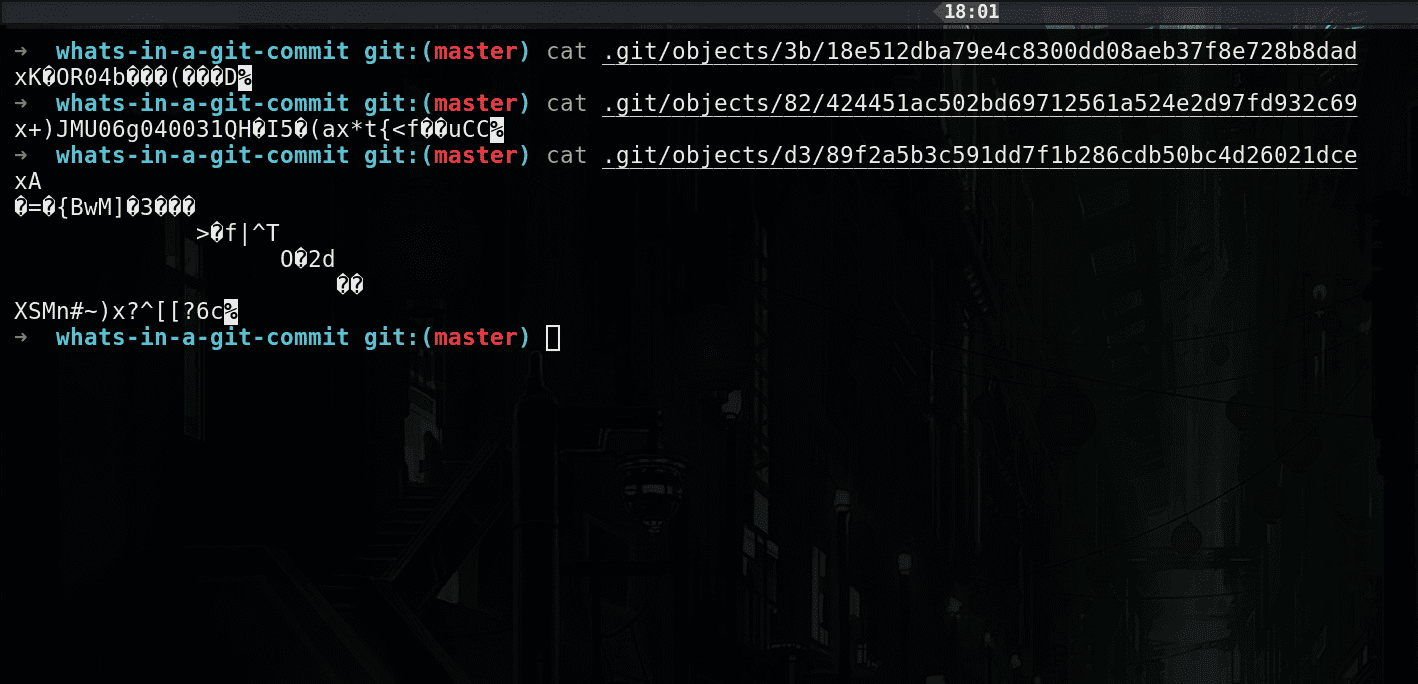
raw object files
You can decompress them using any tool which will allow you to decompress
with zlib. If you have go installed on your machine then you can use
this go
program made
by Kevin Cantwell or with openssl by running openssl zlib -d <fileName> or any other tool which will allow you to decompress with zlib.
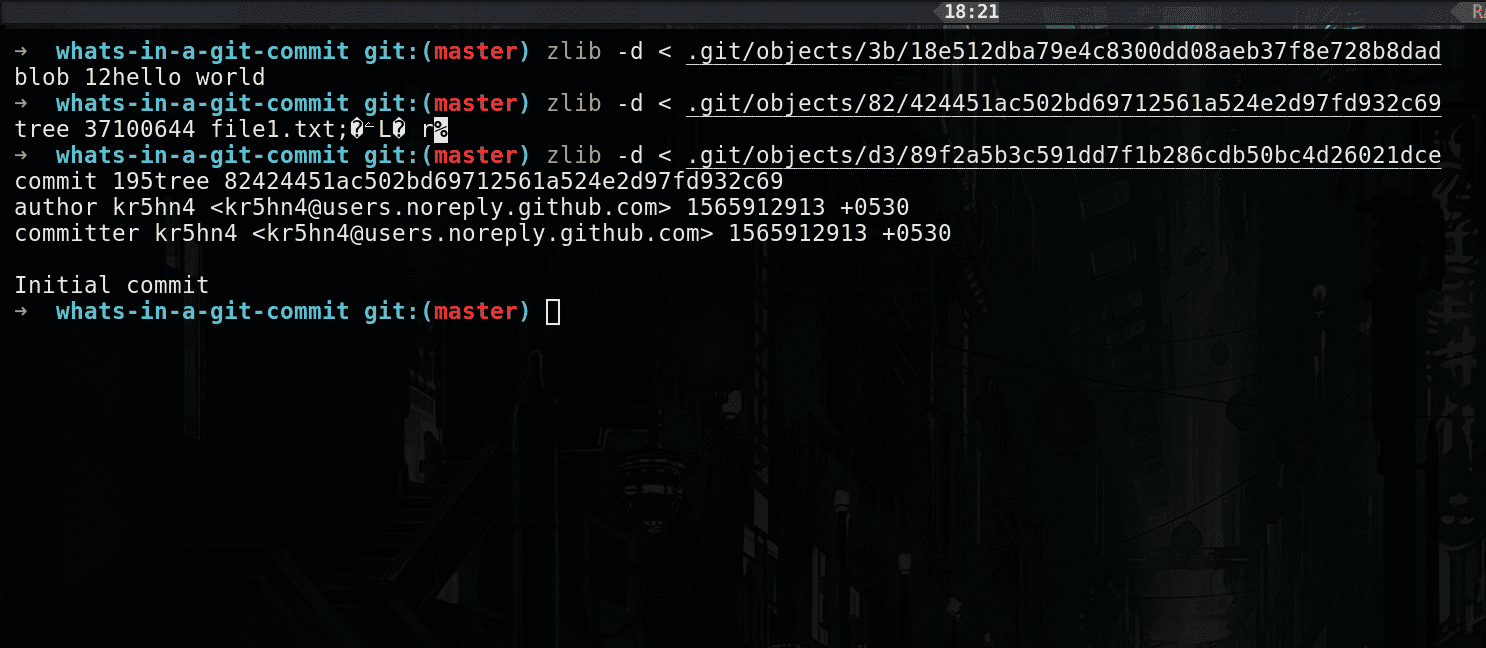
decompressed object files
If you try to calculate the SHA-1 hash of any of these object files after decompressing them, you will notice that their SHA-1 hash is the same as their file name prefixed by the two character folder name in which the file exists.
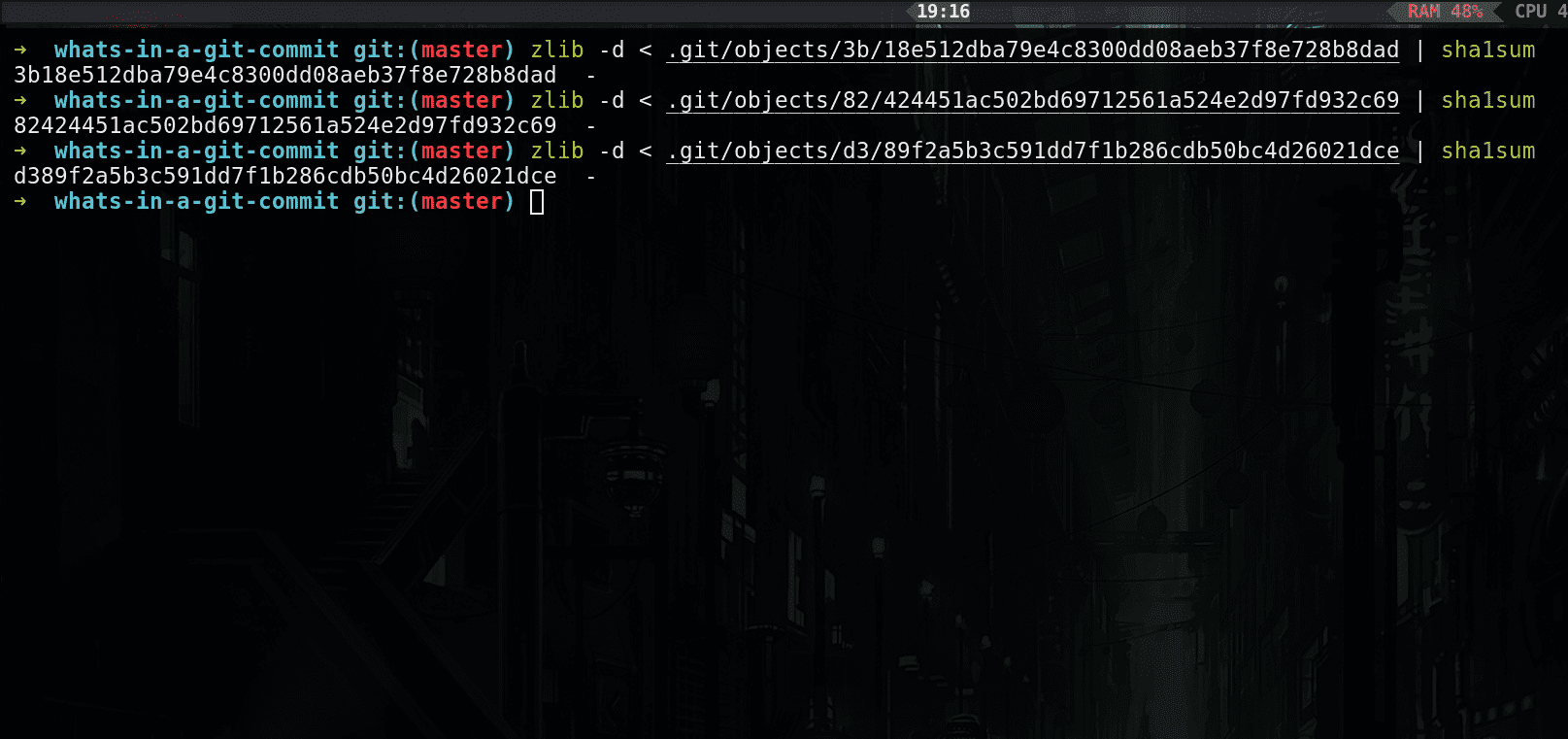
shasum of decompressed object files
This is because git uses content-based addressing i.e. git names its object files based on their content. This way of naming files based on their content is called content-based addressing .This is the reason why git is also called as content-addressable filesystem.
Now let's go through step by step what just happened when we did this commit and see if we can replicate these hashes ourselves. Creating a Git commit consists of two stages i.e. staging and committing. But we will look at these two steps as a single step just for the sake of simplicity. If you would like to know why git uses a staging area, you can read more about it here.
When we create a commit, one of the first thing git does is create a blob object for each file in the repository. In our case we only had one file i.e. file1.txt so git took the contents of file1.txt (remember, only the content of the file and no any other information like file name, permissions etc) and prefixed it with the word "blob" followed by the file size and NUL character and used its SHA-1 hash as the file name and finally git compressed the content with zlib before storing them in objects directory.
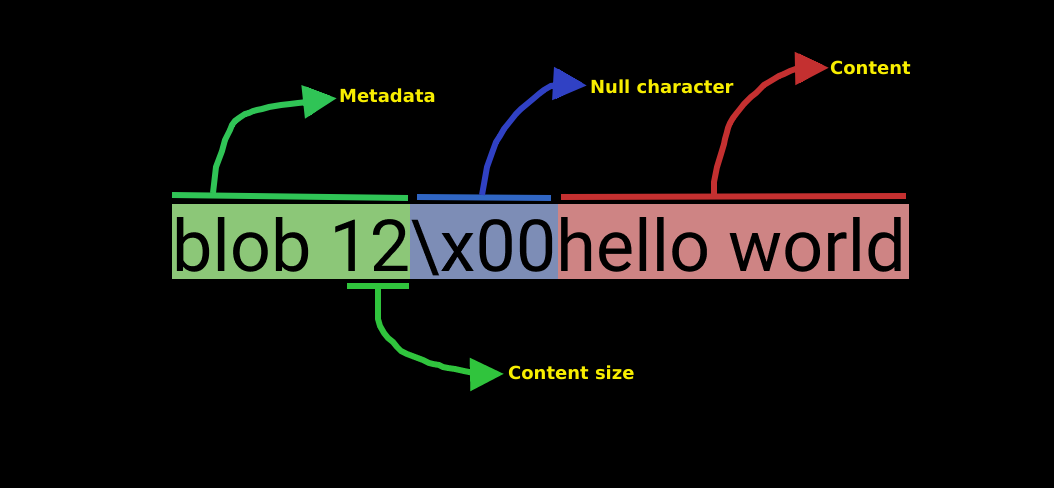
the word blob is so that git can identify this is a blob object. 12 is the content size of this blob object, x00 is the hex code for NUL character (backslash is for escaping), followed by the actual contents of the file.
Let's verify that this is true by running the following command.
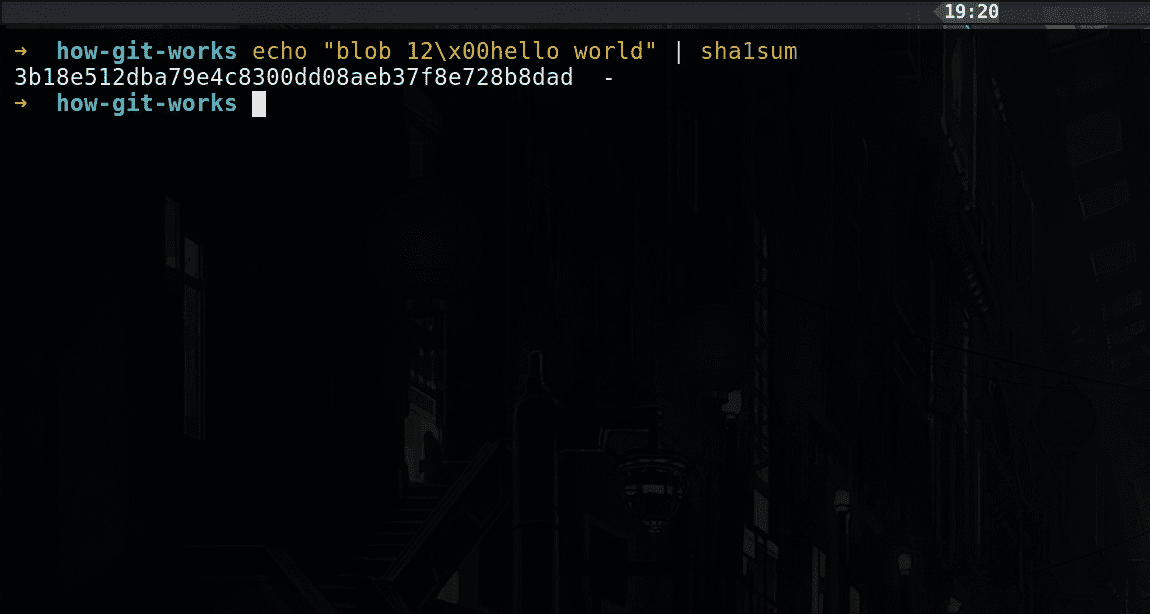
recreate blob hash
As you can see the hash value matches with one of our objects name in the objects directory from our first commit. Git uses the first two characters as the directory name and the remaining as file name, this is to avoid any file system related errors. (Many file systems have a limit on how many files you can have in a single directory).
Ok, so that is how git stores the contents of the files, but how does git know what is the file name that this content belongs to?
Well for that git creates another type of object called tree object. A tree is a simple object that has a bunch of pointers to blobs and other trees - it represents the contents of a single directory and contains other information like file mode, file/directory name, reference to the SHA-1 of the blob/tree object and some metadata. In our case, we only had one directory i.e. working directory with one file in it named file1.txt, if in case we had any other files or folders they would appear in our tree object. And finally, this is how our tree object looks:
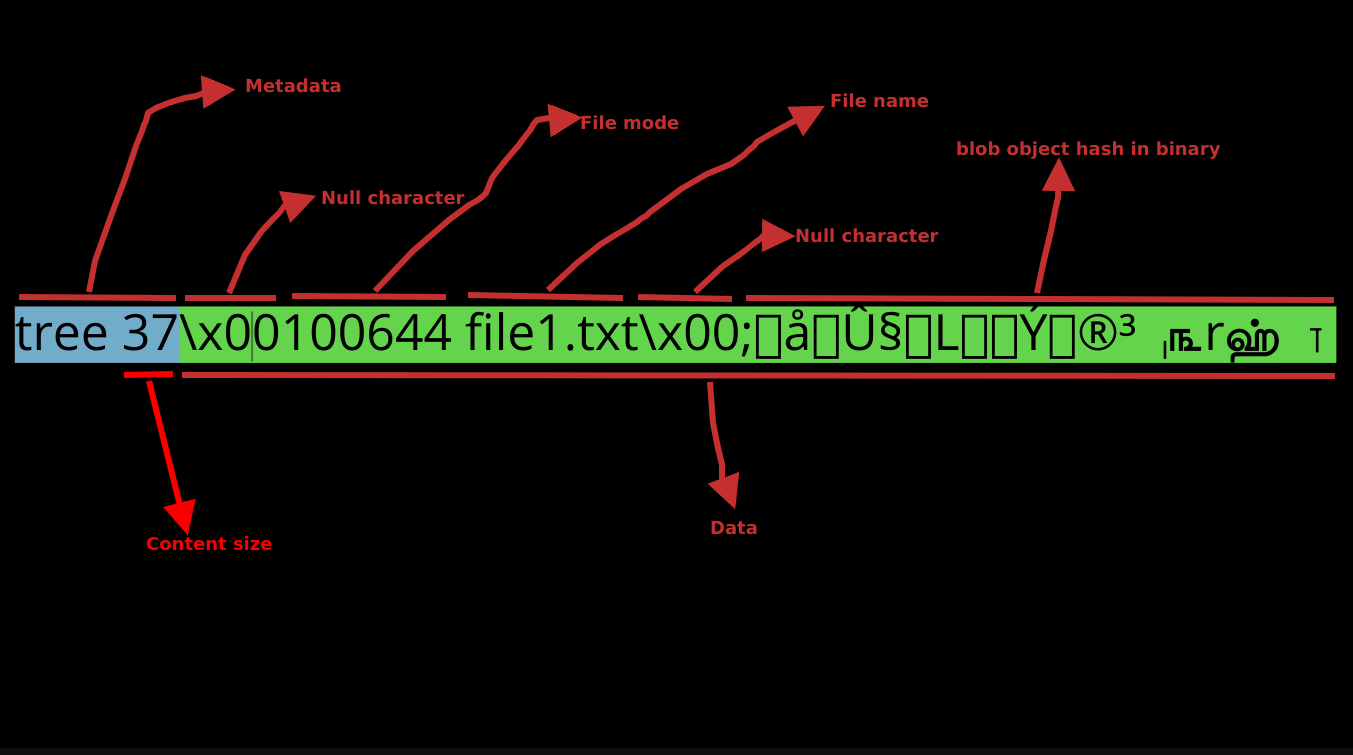
the word tree is so that git can identify this is a tree object. 37 is the content size of this tree object, x00 is the hex code for NUL character (backslash is for escaping), followed by a list of contents of the directory.
The first six characters after the NUL character (100644) represent the file mode, Git uses the following modes:
- 100644 for a normal file
- 100755 for an executable file
- 040000 for a directory
- 120000 for a symbolic link
and after that comes the type of object whether tree, blob or commit followed by the SHA-1 hash of it and finally the file/directory name. An object referenced by a tree may be a blob, representing the contents of a file, or another tree, representing the contents of a subdirectory.
You can use the following command to recreate the tree hash:
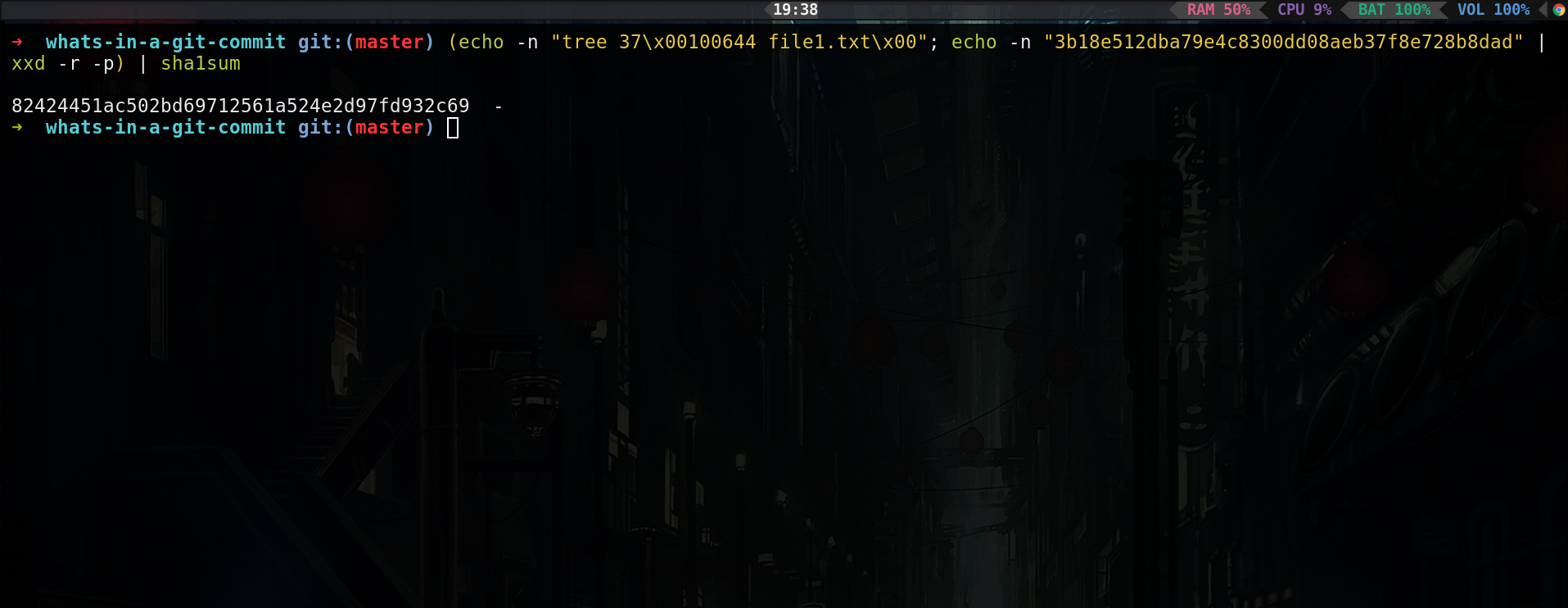
Recreate tree hash
The tree object is a bit weird, in it, it does not include a new line character at the end (that is why we have to pass the -n flag to echo to tell echo to not include newline character at the end, because by default echo appends a new line character at the end) and also stores the hash values in binary. Why is that? Nobody knows.
Finally, git creates a commit object to tie everything together. In our case the commit object is d389f2a5b3c591dd7f1b286cdb50bc4d26021dce. This is what you see with the git log command. The commit object contains information about the commit like the author, committer, commit message, a reference to the tree object of the working directory and a reference to parent commit (In our case we don't have a parent commit since this is our first commit, which is also called as root commit).
Let me tell you how git calculated the SHA-1 sum of the commit object.
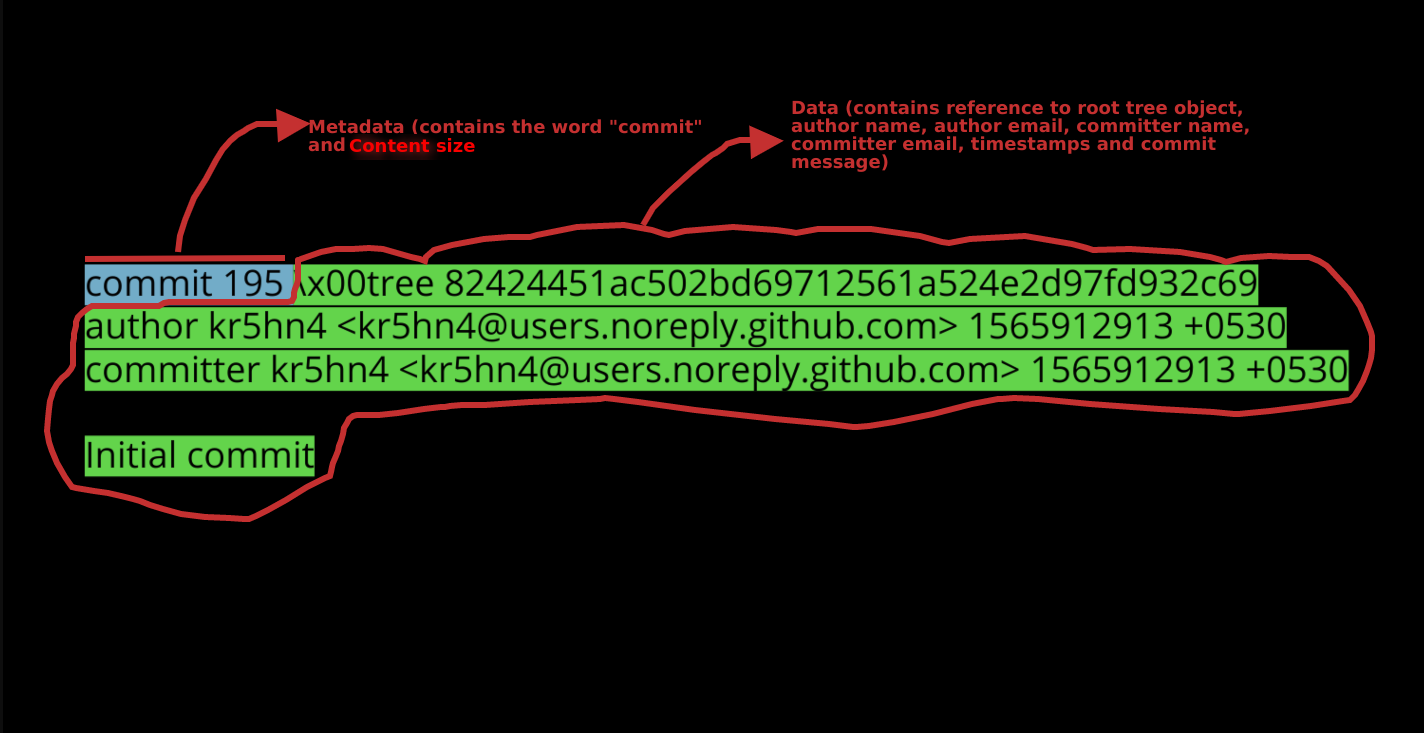
the word commit is so that git can identify this is a commit object. 195 is the content size of this commit object, x00 is the hex code for NUL character (backslash is for escaping), followed by a reference to the root tree object and other information like author, commiter and the commit message.
You can use the following command to recreate the commit hash:
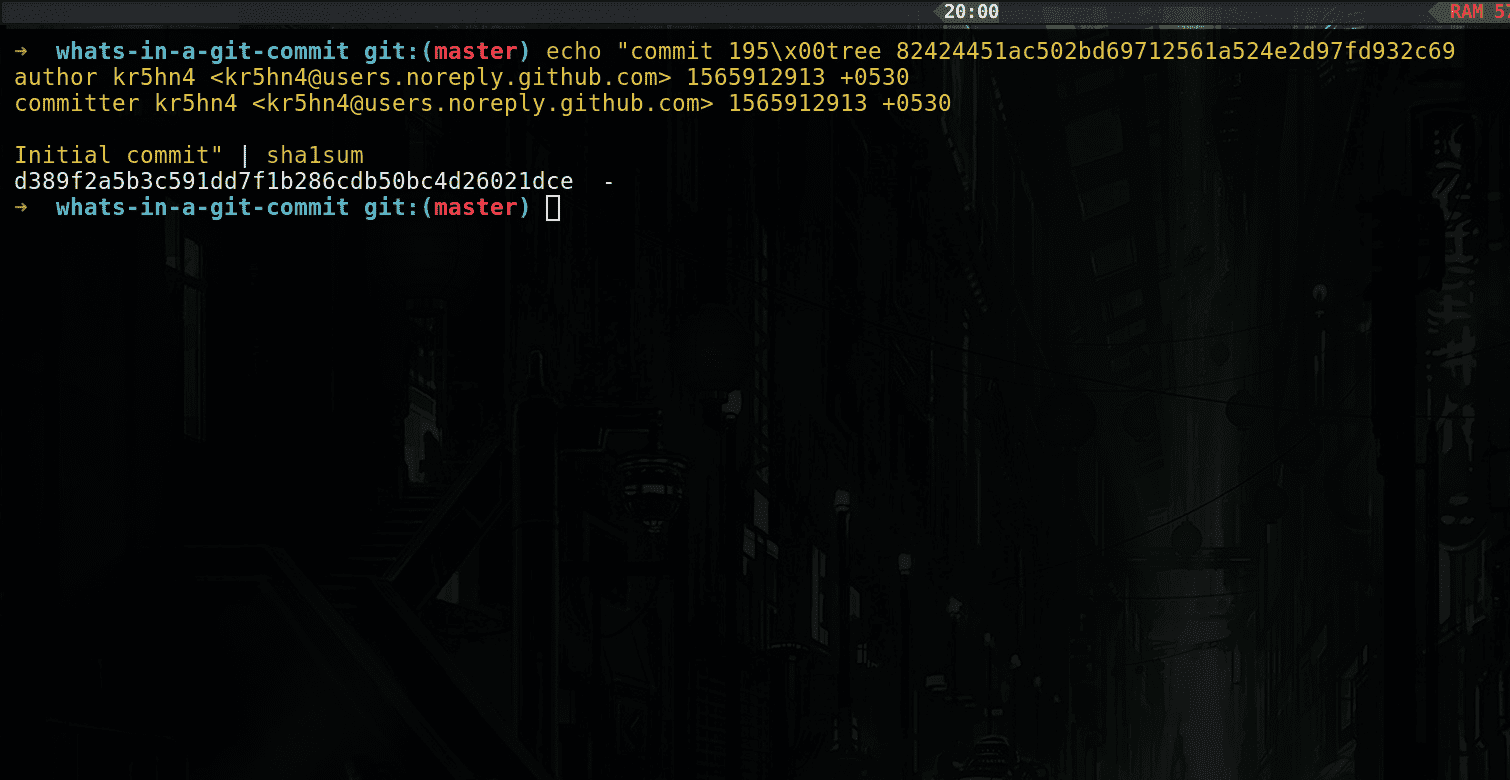
commit hash
And this is how git links commits to trees and trees to blobs.
Many people like to think that git just stores the file changes between commits, but that is not the case. A git commit is like taking a snapshot of the working directory (more like photo copying) at a particular point in history and this snapshot is a copy of the entire working directory which comprises of commit, tree and blob objects. What that means is every time you do a commit git will store the entire contents of the working directory at the time of the commit in .git directory. Now, you might wonder, isn't that inefficient disk space-wise? well not really, because since git uses content-based addressing, git will use the same blobs and tree objects for multiple commits if the contents of the file/directory have not changed.
Here is a visual representation of a sample repo showing how git connects commits, trees and blobs together.
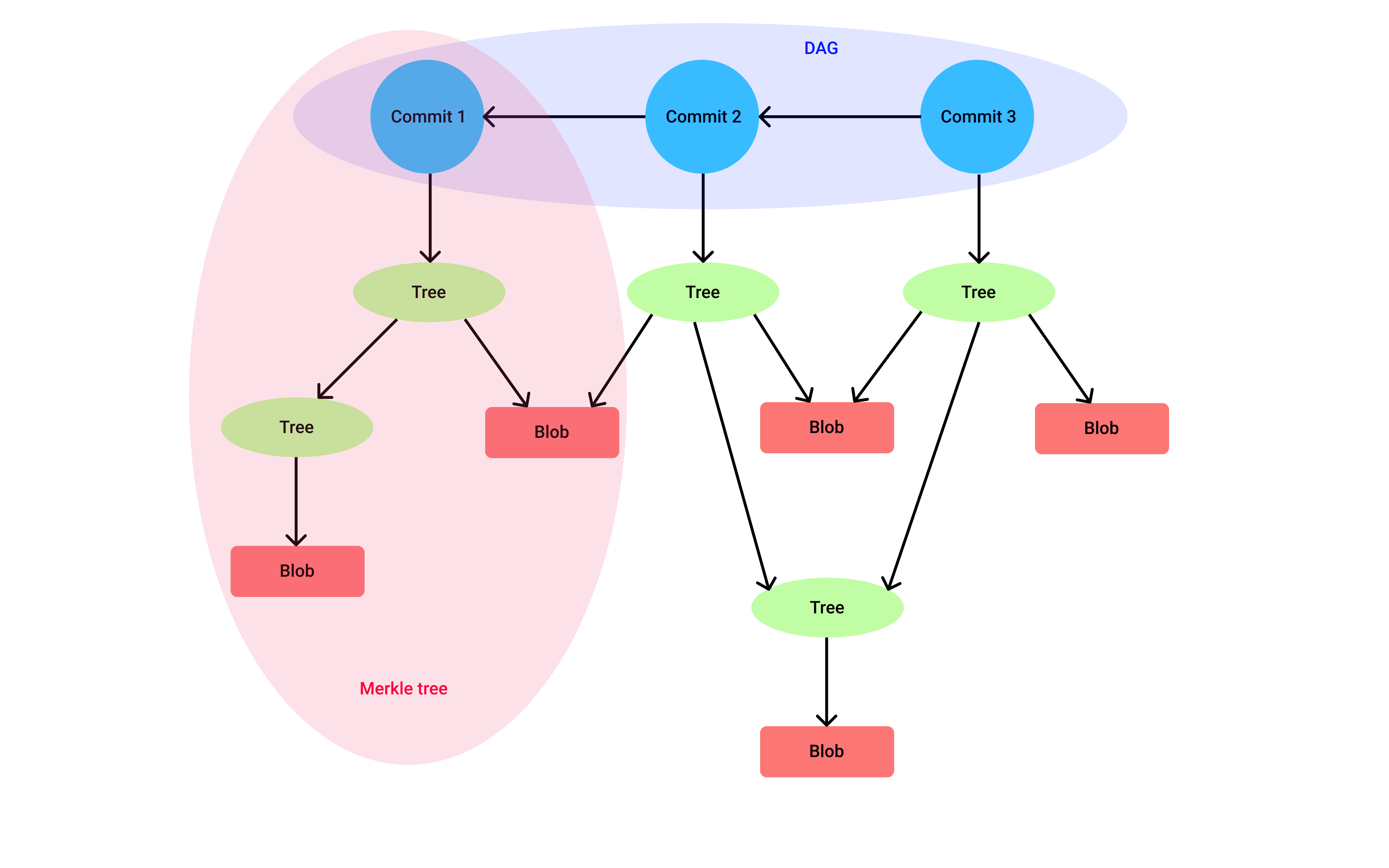
This type of data structure is also called a merkledag, because its a combination of merkle tree and a DAG.
That's all in this post, in the next post we will look at how git maintains branches, define tags, and various git configuration options.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK