

GitHub - JiahuiYu/wdsr_ntire2018: Code of our winning entry to NTIRE 2018 super-...
source link: https://github.com/JiahuiYu/wdsr_ntire2018
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
README.md
Wide Activation for Efficient and Accurate Image Super-Resolution
Tech Report | Approach | Results | Bibtex
Run
- Requirements:
- Install PyTorch (tested on release 0.4.0 and 0.4.1).
- Clone EDSR-Pytorch as backbone training framework.
- Training and Validation:
- Copy wdsr_a.py, wdsr_b.py into
EDSR-PyTorch/src/model/. - Modify
EDSR-PyTorch/src/option.pyandEDSR-PyTorch/src/demo.shto support--n_feats, --block_featsoption. - Launch training with EDSR-Pytorch as backbone training framework.
- Copy wdsr_a.py, wdsr_b.py into
Overall Performance
Network Parameters DIV2K (val) PSNR EDSR Baseline 1,372,318 34.61 WDSR Baseline 1,190,100 34.77We measured PSNR using DIV2K 0801 ~ 0900 (trained on 0000 ~ 0800) on RGB channels without self-ensemble which is identical to EDSR baseline model settings. Both baseline models have 16 residual blocks.
More results:
Number of Residual Blocks13SR NetworkEDSRWDSR-AWDSR-BEDSRWDSR-AWDSR-BParameters2.6M0.8M0.8M4.1M2.3M2.3MDIV2K (val) PSNR33.21033.32333.43434.04334.16334.205Number of Residual Blocks58SR NetworkEDSRWDSR-AWDSR-BEDSRWDSR-AWDSR-BParameters5.6M3.7M3.7M7.8M6.0M6.0MDIV2K (val) PSNR34.28434.38834.40934.45734.54134.536Comparisons of EDSR and our proposed WDSR-A, WDSR-B for image bicubic x2 super-resolution on DIV2K dataset.
WDSR Network Architecture

Left: vanilla residual block in EDSR. Middle: wide activation. Right: wider activation with linear low-rank convolution. The proposed wide activation WDSR-A, WDSR-B have similar merits with MobileNet V2 but different architectures and much better PSNR.
Weight Normalization vs. Batch Normalization and No Normalization
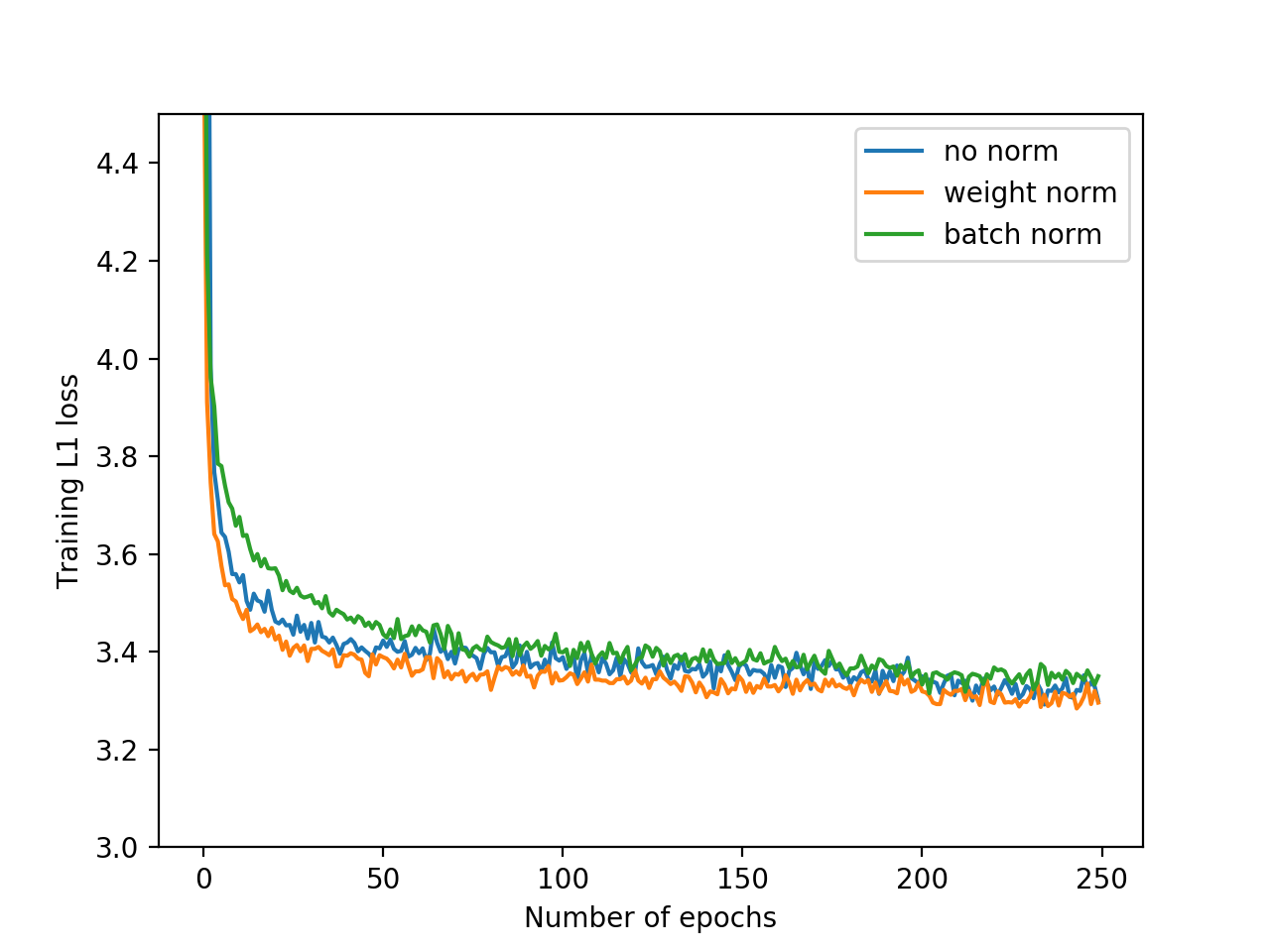
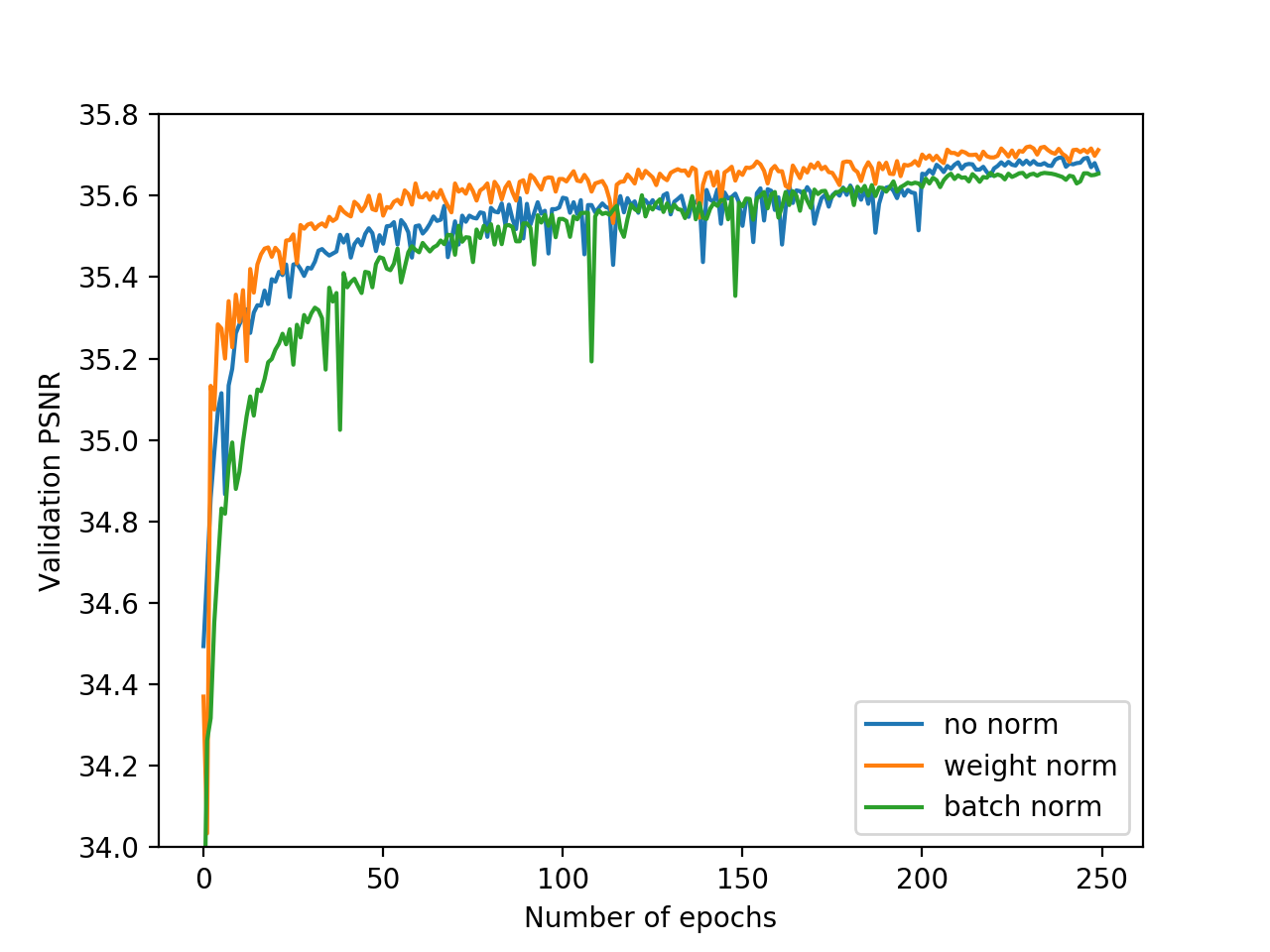
Training loss and validation PSNR with weight normalization, batch normalization or no normalization. Training with weight normalization has faster convergence and better accuracy.
Citing
Please consider cite WDSR for image super-resolution and compression if you find it helpful.
@article{yu2018wide,
title={Wide Activation for Efficient and Accurate Image Super-Resolution},
author={Yu, Jiahui and Fan, Yuchen and Yang, Jianchao and Xu, Ning and Wang, Xinchao and Huang, Thomas S},
journal={arXiv preprint arXiv:1808.08718},
year={2018}
}
@inproceedings{fan2018wide,
title={Wide-activated Deep Residual Networks based Restoration for BPG-compressed Images},
author={Fan, Yuchen and Yu, Jiahui and Huang, Thomas S},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops},
pages={2621--2624},
year={2018}
}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK